







- 论文题目:RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion

所解决的问题
用强化学习控制GAN网络,以使得GAN更快,更鲁棒。将其用于点云数据生成。全网第一次用RL控制GAN。通过数据驱动的方法填补三维数据中的数据缺失。
所采用的方法?

预训练阶段,训练一个自编码器,用于生成隐空间的表示,之后用这个去训练GAN网络。强化学习智能体用于选择合适的
z
z
z向量,去合成隐空间的表示。与之前的反向传播发现
z
z
z向量不同,本文采用RL的方法进行选择。
主要由三个模块组成:1. 自编码器;2.
l
l
l-GAN;3. 强化学习智能体(RL)。
自编码器
自编码器用的损失函数如下:
d C H ( P 1 , P 2 ) = ∑ a ∈ P 1 min b ∈ P 2 ∥ a − b ∥ 2 2 + ∑ b ∈ P 2 min a ∈ P 1 ∥ a − b ∥ 2 2 d_{C H}\left(P_{1}, P_{2}\right)=\sum_{a \in P_{1}} \min _{b \in P_{2}}\|a-b\|_{2}^{2}+\sum_{b \in P_{2}} \min _{a \in P_{1}}\|a-b\|_{2}^{2} dCH(P1,P2)=a∈P1∑b∈P2min∥a−b∥22+b∈P2∑a∈P1min∥a−b∥22
其中 P 1 P_{1} P1和 P 2 P_{2} P2代表点云的输入和输出。
l l l-GAN
结合GFV来训练GAN。
- Chamfer loss:
输入点云数据
P
i
n
P_{in}
Pin和生成器和解码器输出数据
E
−
1
(
G
(
z
)
)
E^{-1}(G(z))
E−1(G(z))做loss:
L C H = d C H ( P i n , E − 1 ( G ( z ) ) ) L_{C H}=d_{C H}\left(P_{i n}, E^{-1}(G(z))\right) LCH=dCH(Pin,E−1(G(z)))
- GFV loss:生成
CFVG ( z ) G(z) G(z)和输入点云 E ( P i n ) E(P_{in}) E(Pin)
L G F V = ∥ G ( z ) − E ( P i n ) ∥ 2 2 L_{G F V}=\left\|G(z)-E\left(P_{i n}\right)\right\|_{2}^{2} LGFV=∥G(z)−E(Pin)∥22
- Discriminator loss 判别器损失函数:
L D = − D ( G ( z ) ) L_{D}=-D(G(z)) LD=−D(G(z))
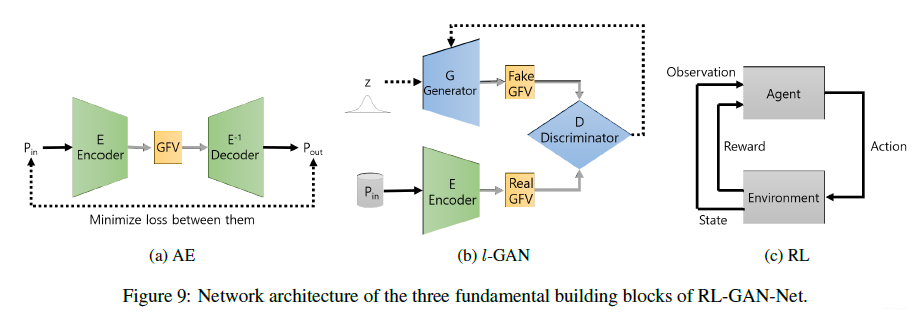
强化学习
强化学习用于快速选择GAN生成器的输入
z
z
z:

奖励函数定义为:
r = w C H ⋅ r C H + w G F V ⋅ r G F V + w D ⋅ r D r=w_{C H} \cdot r_{C H}+w_{G F V} \cdot r_{G F V}+w_{D} \cdot r_{D} r=wCH⋅rCH+wGFV⋅rGFV+wD⋅rD
其中
r
C
H
=
−
L
C
H
r_{CH}=-L_{CH}
rCH=−LCH,
r
G
F
V
=
−
l
G
F
V
r_{GFV}=-l_{GFV}
rGFV=−lGFV,
r
D
=
−
L
D
r_{D}=-L_{D}
rD=−LD。智能体用DDPG算法。

取得的效果?



参考资料
相似文献:
- Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas J. Guibas. Representation learning and adversarial generation of 3d point clouds. CoRR, abs/1707.02392, 2017. (有提到用隐空间数据训练GAN会更稳定)。
相关GitHub链接:
- https://github.com/lijx10/SO-Net
- https://github.com/heykeetae/Self-Attention-GAN
- https://github.com/sfujim/TD3
我的微信公众号名称:小小何先生
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!















 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









