






最早的模仿学习是行为克隆,行为克隆的方法只能模仿轨迹,无法进行泛化。而逆向强化学习是从专家示例中学到背后的回报函数,能泛化到其他情况,因此属于模仿到了精髓。
IRL的提出动机主要有以下两点:
- 多任务学习:蜜蜂是如何权衡飞行距离、时间、捕食动物威胁等多个任务下找到一个最优的飞行路径的?
IRL针对的也是序列决策问题,并非是单步决策问题。 - 学回报函数:难以量化回报函数的领域。

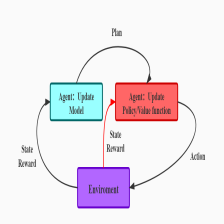
很多时候我们拿不到最优策略,但是获取最优策略的采样数据却是非常容易的。因此逆强化学习的流程如下所示:
- 智能体随机产生一个策略。
- 智能体的策略采样得到的数据与专家数据采样得到的数据对比,学习奖励函数。
- 利用所学的奖励函数进行强化学习,提高自身策略水平。
- 策略差距较小则停止迭代,否者回到第二步。
- 其在机器人领域的应用、较全面的理论知识,可参考以下资料链接:Robot learning by demonstration
有限状态下的求解
以下推导过程主要来自:Algorithms for Inverse Reinforcement Learning。
假定最优策略为 π ∗ \pi^{*} π∗,其它策略为 π \pi π,有:
V π ∗ ( s ) ⩾ V π ( s ) q π ∗ ( s , a ) ⩾ q π ( s , a ) \begin{array}{l} V_{\pi^{*}}(s) \geqslant V_{\pi}(s) \\ q_{\pi^{*}}(s, a) \geqslant q_{\pi}(s, a) \end{array} Vπ∗(s)⩾Vπ(s)qπ∗(s,a)⩾qπ(s,a)
依据Bellman Equation有:
V π = R + γ P s ′ ∣ ( s , π ∗ ( s ) ) V π V^{\pi}=R+\gamma P_{s^{\prime}|(s,\pi^{*}(s))}V^{\pi} Vπ=R+γPs′∣(s,π∗(s))Vπ
因此有:
V π = ( I − γ P s ′ ∣ ( s , π ∗ ( s ) ) ) − 1 R V^{\pi}=(I-\gamma P_{s^{\prime}|(s,\pi^{*}(s))})^{-1}R Vπ=(I−γPs′∣(s,π∗(s)))−1R
这里我们想要求出奖励 R R R的函数方程,因此期望消去 V π V^{\pi} Vπ由:
P s ′ ∣ ( s , π ∗ ( s ) ) V π ≥ P s ′ ∣ ( s , π ( s ) ) V π P_{s^{\prime}|(s,\pi^{*}(s))}V^{\pi} \geq P_{s^{\prime}|(s,\pi(s))}V^{\pi} Ps′∣(s,π∗(s))Vπ≥Ps′∣(s,π(s))Vπ
可以消去 V π V^{\pi} Vπ得到:
( P s ′ ∣ ( s , π ∗ ( s ) ) − P s ′ ∣ ( s , π ( s ) ) ) ( I − γ P s ′ ∣ ( s , π ∗ ( s ) ) ) − 1 R ≥ 0 (P_{s^{\prime}|(s,\pi^{*}(s))}-P_{s^{\prime}|(s,\pi(s))})(I-\gamma P_{s^{\prime}|(s,\pi^{*}(s))})^{-1}R \geq 0 (Ps′∣(s,π∗(s))−Ps′∣(s,π(s)))(I−γPs′∣(s,π∗(s)))−1R≥0
如果假定专家数据为最优策略下的采样数据,则求取的奖励函数期望能够使得上述公式越大越好,上述推导则变成了一个线性规划问题:
max ( P s , π ∗ ( s ) − P s , a ) ( I − γ P π ∗ ) R s.t. ( P s , π ∗ ( s ) − P s , a ) ( I − γ P π ∗ ) R ⩾ 0 \begin{array}{l} \max \left(P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}-\boldsymbol{P}_{\boldsymbol{s}, \boldsymbol{a}}\right)\left(\boldsymbol{I}-\gamma \boldsymbol{P}_{\pi^{*}}\right) \boldsymbol{R} \\ \text { s.t. } \quad\left(P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}-\boldsymbol{P}_{\boldsymbol{s}, \boldsymbol{a}}\right)\left(\boldsymbol{I}-\gamma \boldsymbol{P}_{\pi^{*}}\right) \boldsymbol{R} \geqslant 0 \end{array} max(Ps,π∗(s)−Ps,a)(I−γPπ∗)R s.t. (Ps,π∗(s)−Ps,a)(I−γPπ∗)R⩾0
上述线性规划问题的约束比较弱,回报函数可以成比例地扩大或者缩小同样能够满足约束,并且回报函数取0时也能满足约束,但这种情况实际上是没有意义的。因此考虑增加约束:
- 限制回报的范围:
∣
R
∣
≤
R
m
a
x
|R| \leq R_{max}
∣R∣≤Rmax。并且
Ng认为在其它所有情况都相同的时候,回报函数的取值越小越“简单”也就越可取,可以选择在优化的目标函数上加上一个惩罚项 − λ ∣ ∣ R ∣ ∣ 1 -\lambda||R||_{1} −λ∣∣R∣∣1,类似L1、L2正则化,都是为了防止参数过大。(这里引入了另一个问题, λ \lambda λ参数的取值问题。) - 只考虑最优策略和次优策略的差异:之前考虑的是最优策略优于其它所有策略,也就是以相同的权重考虑最优策略和其它策略之间的差距,但是最优策略和次优策略之间的差距会显得更加重要。
引入这两个约束之后,原问题的规划变为:
max R [ min a { ( P s , π ∗ ( s ) − P s , a ) ( I − γ P π ∗ ) − 1 R } − λ ∣ R ∣ ] s.t. − ( P s , π ∗ ( s ) − P s , a ) ( I − γ P π ∗ ) R ⩽ 0 ∣ R ∣ ⩽ R max \begin{array}{l} \max _{\boldsymbol{R}}\left[\min _{\boldsymbol{a}}\left\{\left(P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}-\boldsymbol{P}_{\boldsymbol{s}, \boldsymbol{a}}\right)\left(\boldsymbol{I}-\gamma \boldsymbol{P}_{\boldsymbol{\pi}^{*}}\right)^{-1} \boldsymbol{R}\right\}-\lambda|\boldsymbol{R}|\right] \\ \text { s.t. } \quad-\left(P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}-\boldsymbol{P}_{\boldsymbol{s}, \boldsymbol{a}}\right)\left(\boldsymbol{I}-\gamma \boldsymbol{P}_{\pi^{*}}\right) \boldsymbol{R} \leqslant 0 \\ |\boldsymbol{R}| \leqslant \boldsymbol{R}_{\max } \end{array} maxR[mina{(Ps,π∗(s)−Ps,a)(I−γPπ∗)−1R}−λ∣R∣] s.t. −(Ps,π∗(s)−Ps,a)(I−γPπ∗)R⩽0∣R∣⩽Rmax
之后我们去求解上述规划问题即可。可参考代码:Inverse-Reinforcement-Learning。
无限状态下的求解
在无线状态空间下,奖励函数可以看作是一个从状态到回报的映射函数:
Reward ( s ) = w T ϕ ( s ) \text{Reward}(s)=w^{T}\phi(s) Reward(s)=wTϕ(s)
其中 ϕ ( s ) \phi(s) ϕ(s)是将状态映射到低维空间。于是问题就变成了求解参数 w w w来确定回报函数,这里设定奖励函数为线性函数也是为了之后方便计算。如果状态被映射到一个 d d d维的向量上,那么求解回报就相当于进行如下计算:
R ( s ) = w 1 ϕ 1 ( s ) + w 2 ϕ 2 ( s ) + ⋯ + w d ϕ d ( s ) R(s)=w_{1} \phi_{1}(s)+w_{2} \phi_{2}(s)+\cdots+w_{d} \phi_{d}(s) R(s)=w1ϕ1(s)+w2ϕ2(s)+⋯+wdϕd(s)
值函数的计算方式可表示为:
V π ( s ) = ∑ t = 0 ∞ γ t ∑ i = 1 d w i ϕ i ( s ) = ∑ i = 1 d ∑ t = 0 ∞ γ t w i ϕ i ( s ) = ∑ i = 1 d w i ∑ t = 0 ∞ γ t ϕ i ( s ) = ∑ i = 1 d w i V i n ( s ) \begin{aligned} V^{\pi}(s) &=\sum_{t=0}^{\infty} \gamma^{t} \sum_{i=1}^{d} w_{i} \phi_{i}(s) \\ &=\sum_{i=1}^{d} \sum_{t=0}^{\infty} \gamma^{t} w_{i} \phi_{i}(s) \\ &=\sum_{i=1}^{d} w_{i} \sum_{t=0}^{\infty} \gamma^{t} \phi_{i}(s) \\ &=\sum_{i=1}^{d} w_{i} V_{i}^{n}(s) \end{aligned} Vπ(s)=t=0∑∞γti=1∑dwiϕi(s)=i=1∑dt=0∑∞γtwiϕi(s)=i=1∑dwit=0∑∞γtϕi(s)=i=1∑dwiVin(s)
其中 V i π ( s ) V_{i}^{\pi}(s) Viπ(s)表示某一维映射特征的累计值。最终目标同样是希望找到最佳的回报函数,使最优策略的价值最大化:
E s ′ ∼ P s , π ∗ ( s ) [ V π ( s ′ ) ] ⩾ E s ′ ∼ P s , a [ V π ( s ′ ) ] ∑ i = 1 d w i ( E s ′ ∼ P s , π ∗ ( s ) [ V i π ( s ′ ) ] − E s ′ ∼ P s , a [ V i π ( s ′ ) ] ) ⩾ 0 \begin{array}{l} E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}}\left[V^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right] \geqslant E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s}, \boldsymbol{a}}}\left[V^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right] \\ \sum_{i=1}^{d} w_{i}\left(E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}}\left[V_{i}^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right]-E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s}, \boldsymbol{a}}}\left[V_{i}^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right]\right) \geqslant 0 \end{array} Es′∼Ps,π∗(s)[Vπ(s′)]⩾Es′∼Ps,a[Vπ(s′)]∑i=1dwi(Es′∼Ps,π∗(s)[Viπ(s′)]−Es′∼Ps,a[Viπ(s′)])⩾0
最终的求解目标为:
maximize ∑ s ∈ S 0 min a ∈ { a 2 , … a k } { p ( ∑ i = 1 d w i ( E s ′ ∼ P s , π ∗ ( s ) [ V i π ( s ′ ) ] − E s ′ ∼ P s a [ V i π ( s ′ ) ] ) ) } s.t. ∣ w i ∣ ⩽ 1 , i = 1 , … , d \begin{aligned} &\text { maximize } \sum_{\boldsymbol{s} \in \boldsymbol{S}_{0}} \min _{\boldsymbol{a} \in\left\{\boldsymbol{a}_{2}, \ldots a_{k}\right\}}\left\{p\left(\sum_{i=1}^{d} w_{i}\left(E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s}, \pi^{*}(\boldsymbol{s})}}\left[V_{i}^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right]-E_{\boldsymbol{s}^{\prime} \sim P_{\boldsymbol{s a}}}\left[V_{i}^{\pi}\left(\boldsymbol{s}^{\prime}\right)\right]\right)\right)\right\}\\ &\text { s.t. } \quad\left|w_{i}\right| \leqslant 1, i=1, \ldots, d \end{aligned} maximize s∈S0∑a∈{a2,…ak}min{p(i=1∑dwi(Es′∼Ps,π∗(s)[Viπ(s′)]−Es′∼Psa[Viπ(s′)]))} s.t. ∣wi∣⩽1,i=1,…,d
与之前有限状态下的求解有些许不同的地方在于:
- 这里我们无法考虑所有的状态,只考虑有限个状态。
- 这里不是对回报函数做约束,而是对回报函数的参数大小进行约束,类似
L1范数。 - 由于函数式模型可变量有限,所以并不能保证完美你和真实的回报函数。一旦无法完美拟合,模型就有可能违背约束条件的情形,因此我们需要将约束项转变成惩罚项。
具体实现可参考/irl/linear_irl.py中的large_irl函数。
最大熵逆强化学习
最大熵逆强化学习(Max Entropy Inverse Reinforcement Learning),它能够从多个满足限定条件的策略中寻找一个更合理的策略。
- 论文:Maximum entropy inverse reinforcement learning
期望利用专家的行动轨迹 ζ = { s i , a i } N \zeta=\left\{s_{i}, a_{i}\right\}_{N} ζ={si,ai}N学一个回报函数 r ( f s j ; θ ) r\left(f_{s_{j}} ; \theta\right) r(fsj;θ),其中 f s j f_{s_{j}} fsj是状态的特征抽取, θ \theta θ是回报函数的参数,如果回报函数与特征之间是线性关系,则可表示为如下形式:
r ( f s j ) = θ T f s j = ∑ i θ i f i r\left(\boldsymbol{f}_{\boldsymbol{s}_{j}}\right)=\theta^{\mathrm{T}} \boldsymbol{f}_{\boldsymbol{s}_{j}}=\sum_{i} \theta_{i} \boldsymbol{f}_{i} r(fsj)=θTfsj=i∑θifi
此时某条轨迹 ζ \zeta ζ的累计回报可以写作:
r ( f ζ ) = ∑ s j ∈ ζ θ T f s j = θ T ∑ s j ∈ ζ f s j = θ T f ζ r\left(f_{\zeta}\right)=\sum_{s_{j} \in \zeta} \theta^{\mathrm{T}} f_{s_{j}}=\theta^{\mathrm{T}} \sum_{s_{j} \in \zeta} f_{s_{j}}=\theta^{\mathrm{T}} f_{\zeta} r(fζ)=sj∈ζ∑θTfsj=θTsj∈ζ∑fsj=θTfζ
假设所有的轨迹起始于同一个状态,将每一条轨迹 ζ ~ \tilde{\boldsymbol{\zeta}} ζ~ 聚合起来,就可以用这些轨迹得到价值期望的估计:
v ( f ) = E ζ ~ i [ r ( f ξ ~ i ) ] ≃ 1 m ∑ i θ T f ξ i = θ T 1 m ∑ i f ζ ~ i = θ T f ~ v(\boldsymbol{f})=E_{\tilde{\boldsymbol{\zeta}}_{\boldsymbol{i}}}\left[r\left(f_{\tilde{\boldsymbol{\xi}}_{\boldsymbol{i}}}\right)\right] \simeq \frac{1}{m} \sum_{\boldsymbol{i}} \theta^{\mathrm{T}} \boldsymbol{f}_{\boldsymbol{\xi}_{\boldsymbol{i}}}=\theta^{\mathrm{T}} \frac{1}{m} \sum_{\boldsymbol{i}} f_{\tilde{\boldsymbol{\zeta}}_{\boldsymbol{i}}}=\theta^{\mathrm{T}} \tilde{\boldsymbol{f}} v(f)=Eζ~i[r(fξ~i)]≃m1i∑θTfξi=θTm1i∑fζ~i=θTf~
假定策略模型为 P π ( ζ i ) P_{\pi}\left(\zeta_{i}\right) Pπ(ζi),我们希望策略模型交互得到的轨迹的累计回报等于专家轨迹的累计回报:
E ζ i ∼ π [ r ( f ζ ) ] = θ T ∑ i P π ( ζ i ) f ζ i = θ T f ~ E_{\zeta_{i} \sim \pi}\left[r\left(f_{\zeta}\right)\right]=\theta^{\mathrm{T}} \sum_{i} P_{\pi}\left(\zeta_{i}\right) f_{\zeta_{i}}=\theta^{\mathrm{T}} \tilde{f} Eζi∼π[r(fζ)]=θTi∑Pπ(ζi)fζi=θTf~
由于等式两边 θ \theta θ相同,可以得到:
∑ i P π ( ζ i ) f ζ i = 1 m ∑ i f ζ ~ i \sum_{i} P_{\pi}\left(\zeta_{i}\right) f_{\zeta_{i}}=\frac{1}{m} \sum_{i} f_{\tilde{\zeta}_{i}} i∑Pπ(ζi)fζi=m1i∑fζ~i
上述这个约束条件并不是很强的一个约束,满足这个约束的策略模型 P π ( ζ i ) P_{\pi}\left(\zeta_{i}\right) Pπ(ζi)可能有很多,而这些策略在完整的问题空间中可能各有优劣,因此在完整的问题空间中仍然可能得到一个较差模型。
- 最大熵约束:
这里就引入另外一个约束,最大熵约束。如果轨迹获得的累计回报 θ T f ζ \theta^{\mathrm{T}} f_{\zeta} θTfζ比较高,那么策略应该以较高的概率出现这条轨迹,再依据最大熵模型可以将轨迹的概率可表示为:
P ( ζ i ∣ θ ) = 1 Z ( θ ) e θ T f ζ i = 1 Z ( θ ) e θ T ∑ s j ∈ ζ i f s j P\left(\zeta_{i} \mid \theta\right)=\frac{1}{Z(\theta)} \mathrm{e}^{\theta^{\mathrm{T}} f_{\zeta_{i}}}=\frac{1}{Z(\theta)} \mathrm{e}^{\theta^{\mathrm{T}} \sum_{s_{j} \in \zeta_{i}} f_{s_{j}}} P(ζi∣θ)=Z(θ)1eθTfζi=Z(θ)1eθT∑sj∈ζifsj
其中 Z ( θ ) = ∑ i e θ T f ζ Z(\theta)=\sum_{i} \mathrm{e}^{\theta^{\mathrm{T}} f_{\zeta}} Z(θ)=∑ieθTfζ。令动作序列为 o o o,则 P T ( ζ ∣ o ) P_{T}(\zeta|o) PT(ζ∣o)表示当行动序列确定时,状态最终转换成序列 ζ \zeta ζ的概率为:
P ( ζ ∣ θ , T ) = ∑ o ∈ O P T ( ζ ∣ o ) e θ T f ζ Z ( θ , o ) I ζ ∈ o P(\zeta \mid \theta, T)=\sum_{o \in O} P_{T}(\zeta \mid o) \frac{\mathrm{e}^{\theta^{\mathrm{T}} f_{\zeta}}}{Z(\theta, o)} I_{\zeta \in \mathrm{o}} P(ζ∣θ,T)=o∈O∑PT(ζ∣o)Z(θ,o)eθTfζIζ∈o
其中
I
ζ
∈
o
I_{\zeta \in \mathrm{o}}
Iζ∈o表示轨迹是否可以通过某一条行动序列生成,当这个值等于1时,表示轨迹可以通过行动序列生成,反之无法生成。将其近似为一个可解的形式:
P ( ζ ∣ θ , T ) ≃ e θ T f ζ Z ( θ , o ) ∏ s t + 1 , a t , s t ∈ ζ P T ( s t + 1 ∣ a t , s t ) P(\zeta \mid \theta, T) \simeq \frac{\mathrm{e}^{\theta^{\mathrm{T}} f_{\zeta}}}{Z(\theta, \mathbf{o})} \prod_{s_{t+1}, a_{t}, s_{t} \in \zeta} P_{T}\left(s_{t+1} \mid a_{t}, s_{t}\right) P(ζ∣θ,T)≃Z(θ,o)eθTfζst+1,at,st∈ζ∏PT(st+1∣at,st)
- 最大似然法求解
由此得到了模型对轨迹的概率,采用最大似然法进行优化,假定问题是确定的MDP,对应的目标函数为:
θ ∗ = argmax θ L ( θ ) = argmax ∑ ζ log p ( ζ ∣ θ , T ) \theta^{*}=\operatorname{argmax}_{\theta} L(\theta)=\operatorname{argmax} \sum_{\zeta} \log p(\boldsymbol{\zeta} \mid \theta, T) θ∗=argmaxθL(θ)=argmaxζ∑logp(ζ∣θ,T)
与最大熵模型求解类似,先构建拉格朗日函数,然后求导令,得到参数梯度的计算公式:
∇ L ( θ ) = f ~ − ∑ ζ p ( ζ ∣ θ , T ) f ζ \nabla L(\theta)=\tilde{f}-\sum_{\zeta} p(\zeta \mid \theta, T) f_{\zeta} ∇L(θ)=f~−ζ∑p(ζ∣θ,T)fζ
其中
p
(
ζ
∣
θ
,
T
)
p(\zeta \mid \theta, T)
p(ζ∣θ,T)和
f
ζ
f_{\zeta}
fζ这两项都显得有些复杂。考虑确定MDP的问题,即行动可以直接决定下一时刻的状态。这样当初始状态、策略和回报函数确定时,未来的轨迹也就确定下来。所以将每一条轨迹的状态分别列出来,再将其中重复状态合并,将这些状态的概率与状态对应的特征相乘,得到的结果也是一样的:
∇ L ( θ ) = f ~ − ∑ s i D s i f s i \nabla L(\theta)=\tilde{f}-\sum_{s_{i}} D_{s_{i}} f_{s_{i}} ∇L(θ)=f~−si∑Dsifsi
其中
D
s
i
D_{si}
Dsi称为状态访问频率期望(Expected State Visitation Frequency),根据策略和确定的状态转移概率推演,可以得到任意一个时刻状态出现的概率,之后将每一个时刻状态出现的概率加起来,即可得到
D
s
i
D_{s_{i}}
Dsi。
- 前向后向计算方法:
先通过反向计算求出策略模型,再进行前向计算得到状态访问频率期望:
设定在最后一刻 T T T所有状态的出现值为1,就可以计算 T − 1 T-1 T−1时刻某个状态下执行某个动作的概率 P T − 1 ( a i , j ∣ s i ) P_{T-1}(a_{i,j}|s_{i}) PT−1(ai,j∣si)可以得到:
P T − 1 ( a i , j ∣ s i ) = P ( s i , a i , j ) P ( s i ) = ∑ k P ( s i , a i , j , s k ) ∑ a i , j ∑ k P ( s i , a i , j , s k ) = ∑ k P ( a i , j ∣ s i ) p ( s k ∣ s i , a i , j ) ∑ a i , j ∑ k P ( a i , j ∣ s i ) p ( s k ∣ s i , a i , j ) \begin{aligned} P_{T-1}\left(\boldsymbol{a}_{i, j} \mid \boldsymbol{s}_{i}\right) &=\frac{P\left(\boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right)}{P\left(\boldsymbol{s}_{i}\right)} \\ &=\frac{\sum_{k} P\left(\boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}, \boldsymbol{s}_{k}\right)}{\sum_{a_{i, j}} \sum_{k} P\left(s_{i}, \boldsymbol{a}_{i, j}, s_{k}\right)} \\ &=\frac{\sum_{k} P\left(\boldsymbol{a}_{i, j} \mid \boldsymbol{s}_{i}\right) p\left(s_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right)}{\sum_{a_{i, j}} \sum_{k} P\left(\boldsymbol{a}_{i, j} \mid \boldsymbol{s}_{i}\right) p\left(s_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right)} \end{aligned} PT−1(ai,j∣si)=P(si)P(si,ai,j)=∑ai,j∑kP(si,ai,j,sk)∑kP(si,ai,j,sk)=∑ai,j∑kP(ai,j∣si)p(sk∣si,ai,j)∑kP(ai,j∣si)p(sk∣si,ai,j)
之前提到轨迹出现的概率和回报成正相关,于是可以使用回报替代概率值,得到:
= ∑ k e r e w a r d ( s i ∣ θ ) p ( s k ∣ s i , a i , j ) ∑ a i , j ∑ k e r e w a r d ( s i ) ∣ θ p ( s k ∣ s i , a i , j ) =\frac{\sum_{k} \mathrm{e}^{\mathrm{reward}\left(\boldsymbol{s}_{i} \mid \theta\right)} p\left(\boldsymbol{s}_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right)}{\sum_{a_{i, j}} \sum_{k} \mathrm{e}^{\mathrm{reward}\left(\boldsymbol{s}_{i}\right) \mid \theta} p\left(\boldsymbol{s}_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right)} =∑ai,j∑kereward(si)∣θp(sk∣si,ai,j)∑kereward(si∣θ)p(sk∣si,ai,j)
令 Z a i , j = ∑ k e r e w a r d ( s i ∣ θ ) p ( s k ∣ s i , a i , j ) Z_{\boldsymbol{a}_{i, j}}=\sum_{k} \mathrm{e}^{\mathrm{reward}\left(\boldsymbol{s}_{i} \mid \theta\right)} p\left(s_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right) Zai,j=∑kereward(si∣θ)p(sk∣si,ai,j),公式就可以变为:
= Z a i , j ∑ a i , j Z a i , j =\frac{Z_{a_{i, j}}}{\sum_{a_{i, j}} Z_{a_{i, j}}} =∑ai,jZai,jZai,j
当时刻转到 T − 2 T-2 T−2时,我么可以得到类似的结果:
P T − 2 ( a i , j ∣ s i ) = ∑ k e r e w a r d ( s i ∣ θ ) p ( s k ∣ s i , a i , j ) Z s k ∑ a i , j ∑ k e r e w a r d ( s i ) ∣ θ p ( s k ∣ s i , a i , j ) Z s k P_{T-2}\left(\boldsymbol{a}_{i, j} \mid \boldsymbol{s}_{i}\right)=\frac{\sum_{k} \mathrm{e}^{\mathrm{reward}\left(\boldsymbol{s}_{i} \mid \theta\right)} p\left(\boldsymbol{s}_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right) Z_{\boldsymbol{s}_{k}}}{\sum_{\boldsymbol{a}_{i, j}} \sum_{k} \mathrm{e}^{\mathrm{reward}\left(\boldsymbol{s}_{i}\right) \mid \theta} p\left(\boldsymbol{s}_{k} \mid \boldsymbol{s}_{i}, \boldsymbol{a}_{i, j}\right) Z_{\boldsymbol{s}_{k}}} PT−2(ai,j∣si)=∑ai,j∑kereward(si)∣θp(sk∣si,ai,j)Zsk∑kereward(si∣θ)p(sk∣si,ai,j)Zsk
这样就得到了一个迭代公式,随着迭代轮数不断增加,策略估计值会变得越来越稳定,越来越接近真实的策略,这样就可以完成策略的计算。拿到策略之后可以进行前向计算,得到每个时刻的访问频率。


Max Entropy Inverse Reinforcement Learning中还介绍了深度最大熵逆强化学习,主要改进是将其中的模型换成了深层模型。
参考
[1] Apprenticeship learning via inverse reinforcement learning (2004年 学徒学习)
[2] Maximum Margin Planning (2006年 最大边际规划)
[3] Inverse reinforcement learning through structured classification(2012年 结构化分类)
[4] Neural inverse reinforcement learning in autonomous navigation(2016年 神经逆向强化学习)















 4910
4910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









