







METHODS FOR NON-LINEAR LEAST SQUARES PROBLEMS(二)
2. 下降方法
所有非线性优化的方法都基于是迭代的。从一个起点
x
0
\pmb{x}_0
xxx0开始,该方法产生一系列的向量
x
1
,
x
2
,
.
.
.
,
\pmb{x}_1,\pmb{x}_2,...,
xxx1,xxx2,...,(希望能) 收敛到
x
∗
\pmb{x}^∗
xxx∗ ,即给定函数的局部最小值,见定义1.3.。大多数方法都有强制执行下降条件的措施
F
(
x
k
+
1
)
<
F
(
x
k
)
(2.1)
F(\pmb{x}_{k+1}) < F(\pmb{x}_k) \tag{2.1}
F(xxxk+1)<F(xxxk)(2.1)
这可以防止收敛到最大值,也使我们收敛到鞍点的概率降低。如果给定的函数有几个最小值,其结果将取决于起始点 x 0 \pmb{x}_0 xxx0。我们不知道哪一个最小值将被发现;它不一定是最接近 x 0 \pmb{x}_0 xxx0 的最小值。
在许多情况下,该方法产生的向量会在两个明显不同的阶段向最小值收敛。当
x
0
\pmb{x}_0
xxx0 离解很远时 我们希望该方法产生的迭代结果能稳定地朝向
x
∗
\pmb{x}^∗
xxx∗ 移动。在这个迭代的 “全局阶段”,除非是在最初的步骤中, 如果误差不增加,我们就满意了。即
∣
∣
e
k
+
1
∣
∣
<
∣
∣
e
k
∣
∣
f
o
r
k
>
K
||\pmb{e}_{k+1}|| < ||\pmb{e}_k|| \quad for \quad k>K
∣∣eeek+1∣∣<∣∣eeek∣∣fork>K
其中
e
k
\pmb{e}_k
eeek 表示当前的误差,
e
k
=
x
k
−
x
∗
(2.2)
\pmb{e}_k = \pmb{x}_k - \pmb{x}^* \tag{2.2}
eeek=xxxk−xxx∗(2.2)
在迭代的最后阶段,即当 x k \pmb{x}_k xxxk 接近 x ∗ \pmb{x}^∗ xxx∗ 时,我们希望更快的收敛。我们对以下情况进行区分
- 线性收敛:
∣ ∣ e k + 1 ∣ ∣ ≤ a ∣ ∣ e k ∣ ∣ w h e n ∣ ∣ e k ∣ ∣ i s s m a l l ; 0 < a < 1 , (2.3a) ||\pmb{e}_{k+1}|| \leq a||\pmb{e}_k|| \quad when \, ||\pmb{e}_k|| \, is \, small; \quad 0<a<1, \tag{2.3a} ∣∣eeek+1∣∣≤a∣∣eeek∣∣when∣∣eeek∣∣issmall;0<a<1,(2.3a) - 二次收敛:
∣ ∣ e k + 1 ∣ ∣ = O ( ∣ ∣ e k ∣ ∣ 2 ) w h e n ∣ ∣ e k ∣ ∣ i s s m a l l (2.3b) ||\pmb{e}_{k+1}||=\mathit{O}(||\pmb{e}_k||^2) \quad when \, ||e_k|| \, is \, small \tag{2.3b} ∣∣eeek+1∣∣=O(∣∣eeek∣∣2)when∣∣ek∣∣issmall(2.3b) - 超线性收敛:
∣ ∣ e k + 1 ∣ ∣ / ∣ ∣ e k ∣ ∣ → 0 f o r k → ∞ (2.3c) ||\pmb{e}_{k+1}||/||\pmb{e}_k||\to 0 \quad for \, k \to \infty \tag{2.3c} ∣∣eeek+1∣∣/∣∣eeek∣∣→0fork→∞(2.3c)
本讲义中介绍的方法是在迭代的每一步都满足下降条件(2.1)的下降方法。当前迭代的一步包括
- 找到一个下降方向 h d \pmb{h}_d hhhd(在下面讨论),并且
- 找到一个能很好地减少 F F F 值的步长。
因此,一个下降方法的概要是

考虑
F
F
F 值沿着以
x
\pmb{x}
xxx 为起点,以
h
\pmb{h}
hhh 为方向的的直线的变化情况。从泰勒展开(1.4a)中我们可以看到
F
(
x
+
α
h
)
=
F
(
x
)
+
α
h
T
F
˙
(
x
)
+
O
(
α
2
)
≈
F
(
x
)
+
α
h
T
F
˙
(
x
)
f
o
r
α
s
u
f
f
i
c
i
e
n
t
l
y
s
m
a
l
l
(2.5)
F(\pmb{x}+\alpha \pmb{h})=F(\pmb{x})+\alpha \pmb{h}^T \dot{F}(\pmb{x}) + \mathit{O}(\alpha^2) \\ \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \approx F(\pmb{x}) + \alpha \pmb{h}^T \dot{F}(\pmb{x}) \quad for \, \alpha \, sufficiently \, small \tag{2.5}
F(xxx+αhhh)=F(xxx)+αhhhTF˙(xxx)+O(α2)≈F(xxx)+αhhhTF˙(xxx)forαsufficientlysmall(2.5)
如果 F ( x + α h ) F(\pmb{x}+\alpha \pmb{h}) F(xxx+αhhh) 在 α = 1 \alpha=1 α=1 时是关于 α \alpha α 的递减函数,我们就说 h \pmb{h} hhh 是一个下降方向。 这引出了以下定义。
定义2.6. 下降方向
如果 h T F ( x ) < 0 \pmb{h}^TF(\pmb{x})<0 hhhTF(xxx)<0,则 h \pmb{h} hhh 是 F F F 在 x \pmb{x} xxx 处的下降方向。
如果不存在这样的
h
\pmb{h}
hhh,则
F
˙
(
x
)
=
0
\dot{F}(\pmb{x})=0
F˙(xxx)=0,表明在这种情况下
x
\pmb{x}
xxx 是驻点。否则,我们必须选择
α
\alpha
α,即我们应该在
h
d
\pmb{h}_d
hhhd 给定的方向上从
x
\pmb{x}
xxx 出发移动多远,以便得到目标函数值的减少。这样做的一个方法是找到(一个近似值)
α
e
=
a
r
g
m
i
n
α
>
0
{
F
(
x
+
α
h
)
}
(2.7)
\alpha_e = argmin_{\alpha > 0}\{F(\pmb{x}+\alpha \pmb{h})\} \tag{2.7}
αe=argminα>0{F(xxx+αhhh)}(2.7)
这个过程被称为线搜索,并将在第 2.3 节中讨论。然而,首先我们将介绍两种计算下降方向的方法。
2.1 最陡峭的下降方法
从(2.5)中我们可以看出,当我们执行一个具有正的
α
\alpha
α 值的步长
α
h
\alpha \pmb{h}
αhhh 时,那么 目标函数值的相对增益满足
lim
α
→
0
F
(
x
)
−
F
(
x
+
α
h
)
α
∣
∣
h
∣
∣
=
−
1
∣
∣
h
∣
∣
h
T
F
˙
(
x
)
=
−
∣
∣
F
˙
(
x
)
∣
∣
c
o
s
θ
\lim_{\alpha \to 0} \frac{F(\pmb{x}) - F(\pmb{x}+\alpha \pmb{h})}{\alpha ||\pmb{h}||} = - \frac{1}{||\pmb{h}||} \pmb{h}^T \dot{F}(\pmb{x}) = - ||\dot{F}(\pmb{x})||cos \theta
α→0limα∣∣hhh∣∣F(xxx)−F(xxx+αhhh)=−∣∣hhh∣∣1hhhTF˙(xxx)=−∣∣F˙(xxx)∣∣cosθ
其中
θ
\theta
θ 是向量
h
\pmb{h}
hhh 和
F
˙
(
x
)
\dot{F}(\pmb{x})
F˙(xxx) 之间的角度。这表明,如果
θ
=
0
\theta=0
θ=0,即如果我们使用由下式给出的最陡峭的下降方向
h
s
d
\pmb{h}_{sd}
hhhsd,我们可以得到最大的增益率
h
s
d
=
−
F
˙
(
x
)
(2.8)
\pmb{h}_{sd}=-\dot{F}(\pmb{x}) \tag{2.8}
hhhsd=−F˙(xxx)(2.8)
基于(2.8)的方法(即算法2.4中的 h d = h s d \pmb{h}_d = \pmb{h}_{sd} hhhd=hhhsd)被称为最陡峭下降法或梯度法。下降方向的选择是 “最好的”(局部),我们可以将其与精确的线搜索(2.7)相结合。像这样的方法会收敛,但最终的收敛性能是线性的,而且往往很慢。Frandsen et al (2004) 中的例子显示了使用精确的线搜索的最陡峭下降法在有限的计算机精度的情况下可能无法找到二阶多项式的最小化值。然而,对于许多问题。该方法在迭代过程的初始阶段具有相当好的性能。
诸如此类的考虑导致了所谓的混合方法,顾名思义,是基于两种不同的方法。一种是在初始阶段很好的,比如梯度法,而另一种方法则在最后阶段很好,比如牛顿法(见下一节)。混合方法的一个主要问题是找到在两种方法之间进行适当切换的机制。
2.2 牛顿法
我们可以从
x
∗
x^∗
x∗ 是一个驻点的条件推导出这种方法。根据定义1.6,它满足
F
˙
(
x
∗
)
=
0
\dot{F}(\pmb{x}^∗)=0
F˙(xxx∗)=0。这是一个非线性方程组,根据泰勒展开
F
˙
(
x
+
h
)
=
F
˙
(
x
)
+
F
¨
(
x
)
h
+
O
(
∣
∣
h
∣
∣
2
)
≈
F
˙
(
x
)
+
F
¨
(
x
)
h
f
o
r
∣
∣
h
∣
∣
s
u
f
f
i
c
i
e
n
t
l
y
s
m
a
l
l
\dot{F}(\pmb{x}+\pmb{h})= \dot{F}(\pmb{x})+\ddot{F}(\pmb{x})\pmb{h} + \mathit{O}(||\pmb{h}||^2) \\ \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \approx \dot{F}(\pmb{x}) + \ddot{F}(\pmb{x}) \pmb{h} \quad for \, ||\pmb{h}|| \, sufficiently \, small
F˙(xxx+hhh)=F˙(xxx)+F¨(xxx)hhh+O(∣∣hhh∣∣2)≈F˙(xxx)+F¨(xxx)hhhfor∣∣hhh∣∣sufficientlysmall
我们推导出牛顿法。找出
h
n
\pmb{h}_n
hhhn 的作为以下方程的解
H
h
n
=
−
F
˙
(
x
)
w
i
t
h
H
=
F
¨
(
x
)
(2.9a)
\pmb{H}\pmb{h}_n = - \dot{F}(\pmb{x}) \quad with \, \pmb{H}=\ddot{F}(\pmb{x}) \tag{2.9a}
HHHhhhn=−F˙(xxx)withHHH=F¨(xxx)(2.9a)
并通过以下方式计算下一次迭代
x
:
=
x
+
h
n
(2.9b)
\pmb{x}:=\pmb{x}+\pmb{h}_n \tag{2.9b}
xxx:=xxx+hhhn(2.9b)
假设
H
\pmb{H}
HHH 是正定的,那么它就是非奇异的(意味着(2.9a)有一个唯一的解),并且对于所有非零的
u
\pmb{u}
uuu,都满足
u
T
H
u
>
0
\pmb{u}^T\pmb{H}\pmb{u}> 0
uuuTHHHuuu>0。 因此在(2.9a)的两边都乘以
h
n
T
\pmb{h}_n^T
hhhnT,我们得到
0
<
h
n
T
H
h
n
=
−
h
n
F
˙
(
x
)
(2.10)
0<\pmb{h}_n^T\pmb{H}\pmb{h}_n = -\pmb{h}_n\dot{F}(\pmb{x}) \tag{2.10}
0<hhhnTHHHhhhn=−hhhnF˙(xxx)(2.10)
这个公式表明 h n h_n hn 是一个下降方向:它满足定义 2.6 的条件。
牛顿法在迭代的最后阶段的性能非常好,此时 x \pmb{x} xxx 接近于 x ∗ \pmb{x}^∗ xxx∗。我们可以证明(见 Frandsen等人(2004) ),如果海塞矩阵在 x ∗ \pmb{x}^* xxx∗ 处是正定的(满足定理1.8中的充分条件),并且我们在 x ∗ \pmb{x}^∗ xxx∗ 周围的 F ¨ ( x ) \ddot{F}(\pmb{x}) F¨(xxx) 是正定的区域内,则我们会得到二次收敛(定义见(2.3))。 另一方面,如果 x \pmb{x} xxx 位于 F ¨ ( x ) \ddot{F}(\pmb{x}) F¨(xxx) 为负定的区域内,并且那里有一个驻点,基础的牛顿方法(2.9)将向这个为最大值的驻点收敛(二次)。 我们可以通过要求所有的步骤都在下降方向来避免这种情况
我们可以建立一个混合方法,基于牛顿法和最速下降法。根据(2.10),如果
F
¨
(
x
)
\ddot{F}(\pmb{x})
F¨(xxx) 是正定的,则牛顿步长保证代价函数是下降的,所以这个混合算法的中心部分的概述可以是
i
f
F
¨
(
x
)
i
s
p
o
s
i
t
i
v
e
d
e
f
i
n
i
t
e
h
:
=
h
n
e
l
s
e
h
:
=
h
s
d
x
:
=
x
+
α
h
(2.11)
\begin{matrix} if \, \ddot{F}(\pmb{x}) \, is \, positive \, definite & \\ \quad \quad \quad \quad \quad \pmb{h}:=\pmb{h}_n \\ else \\ \quad \quad \quad \quad \quad \pmb{h}:=\pmb{h}_{sd} \\ \pmb{x}:=\pmb{x}+\alpha \pmb{h}\end{matrix} \tag{2.11}
ifF¨(xxx)ispositivedefinitehhh:=hhhnelsehhh:=hhhsdxxx:=xxx+αhhh(2.11)
这里, h s d \pmb{h}_{sd} hhhsd 是最陡峭的下降方向, α \alpha α 是通过线搜索找到的(见第2.3节)。检查矩阵的正定性的一个好工具是 Cholesky 方法(见附录A),当该方法成功时,也可用求解问题中的线性系统。因此,对正定性的检查是几乎是免费的。
在第2.4节中,我们介绍了一些方法,其中搜索方向 h d \pmb{h}_d hhhd 和步长 α \alpha α 的计算是同时进行的。并给出了一个没有线搜索的(2.11)的版本。这样的混合方法可能非常有效,但它们几乎没有被使用过。原因是它们需要 F ¨ ( x ) \ddot{F}(\pmb{x)} F¨(x)x)x) 的实现,而对于复杂的应用问题,这是不可能的。相反,我们可以使用一个所谓的准牛顿方法,它基于逐渐逼近 H ∗ = F ¨ ( x ∗ ) \pmb{H}^∗=\ddot{F}(\pmb{x}^*) HHH∗=F¨(xxx∗) 的一系列矩阵。在第3.4节我们介绍了这样的一种方法。也可以参考 Frandsen et al (2004) 的第5章。
2.3 线搜索
给定一个点
x
\pmb{x}
xxx 和一个下降方向
h
\pmb{h}
hhh。下一个迭代步骤是从
x
\pmb{x}
xxx 出发向
h
\pmb{h}
hhh 方向移动。为了找出该移动多远,我们研究了给定的函数沿着 从
x
\pmb{x}
xxx 出发沿着
h
\pmb{h}
hhh 方向的直线的变化,
φ
(
α
)
=
F
(
x
+
α
h
)
,
x
a
n
d
h
f
i
x
e
d
,
α
≥
0
(2.12)
\varphi(\alpha) = F(\pmb{x}+\alpha \pmb{h}), \quad \pmb{x}\, and \, \pmb{h} \, fixed, \, \alpha \geq 0 \tag{2.12}
φ(α)=F(xxx+αhhh),xxxandhhhfixed,α≥0(2.12)
图2.1显示了 φ ( α ) \varphi (\alpha) φ(α) 的函数示例。
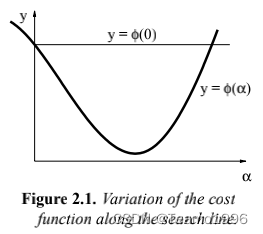
我们的
h
\pmb{h}
hhh 是一个下降方向,确保了
φ
˙
(
0
)
=
h
T
F
˙
(
x
)
<
0
\dot{\varphi}(0) = \pmb{h}^T\dot{F}(\pmb{x}) < 0
φ˙(0)=hhhTF˙(xxx)<0
这表明如果
α
\alpha
α 足够小,我们满足下降条件(2.1),它等价于
φ
(
α
)
<
φ
(
0
)
\varphi (\alpha) < \varphi (0)
φ(α)<φ(0)
通常,我们会对 α \alpha α 给一个初始猜测值,例如使用牛顿法的 α = 1 \alpha=1 α=1。图2.1说明了可能会出现的三种不同的情况
- α \alpha α 非常小,目标函数的值增益非常小。 α \alpha α 应该被增加。
- α \alpha α太大了: φ ( α ) ≥ φ ( 0 ) \varphi(\alpha) \geq \varphi(0) φ(α)≥φ(0)。应该降低 α \alpha α 以满足下降条件(2.1)。
-
α
\alpha
α 接近于
φ
(
α
)
\varphi(\alpha)
φ(α) 的最小值。接受此
α
\alpha
α 值。
更准确地说,是: φ \varphi φ 的最小的局部最小值。如果我们将 α \alpha α 增加到超过图 2.1 所示的区间之外,那么我们很可能会接近 F F F 的另一个局部最小值。
精确的线搜索是一个迭代过程,产生一系列
α
1
,
α
2
,
.
.
.
\alpha_1,\alpha_2,...
α1,α2,...。目的是找到(2.7)中定义的真正的最小值
α
e
\alpha_e
αe,当迭代
α
s
\alpha_s
αs 满足以下条件时,算法停止
∣
φ
(
α
s
)
˙
∣
≤
τ
∣
φ
(
0
)
˙
∣
|\dot{\varphi(\alpha_s)}| \leq \tau |\dot{\varphi(0)}|
∣φ(αs)˙∣≤τ∣φ(0)˙∣
其中
τ
\tau
τ 是一个很小的正数。在迭代中,我们可以使用基于以下的计算值的
φ
(
α
)
\varphi(\alpha)
φ(α) 的变化的近似
φ
(
α
k
)
=
F
(
x
+
α
k
h
)
a
n
d
φ
(
α
k
)
˙
=
h
T
F
˙
(
x
+
α
k
h
)
\varphi(\alpha_k)=F(\pmb{x}+\alpha_k \pmb{h})\quad and \quad \dot{\varphi(\alpha_k)}=\pmb{h}^T\dot{\pmb{F}}(\pmb{x}+\alpha_k \pmb{h})
φ(αk)=F(xxx+αkhhh)andφ(αk)˙=hhhTFFF˙(xxx+αkhhh)
详见 Frandsen et al (2004) 的第2.5-2.6节。
精确的线搜索可能会浪费大量的计算时间:当
x
\pmb{x}
xxx 远离
x
∗
\pmb{x}^∗
xxx∗ 时,搜索方向
h
\pmb{h}
hhh 可能远离方向
x
∗
−
x
\pmb{x}^∗−\pmb{x}
xxx∗−xxx,并且不需要非常准确地找到
φ
\varphi
φ 的真实的最小值。这是所谓的软线搜索的背景,当
α
\alpha
α 的值不属于上面列出的类别1或2,我们就接受这个
α
\alpha
α 值。我们使用下降条件(2.1)的更严格的版本,即
φ
(
α
s
)
≤
φ
(
0
)
+
γ
1
⋅
φ
˙
(
0
)
w
i
t
h
0
<
γ
1
<
1
(2.13a)
\varphi(\alpha_s) \leq \varphi(0) + \gamma_1 \cdot \dot{\varphi}(0) \quad with \, 0 < \gamma_1 < 1 \tag{2.13a}
φ(αs)≤φ(0)+γ1⋅φ˙(0)with0<γ1<1(2.13a)
这确保了我们不在类别2中。类别1对应于点
(
α
,
φ
(
α
)
)
(\alpha,\varphi(\alpha))
(α,φ(α)) 太接近起始切线,我们用以下条件进行补充
φ
˙
(
α
s
)
≥
γ
2
⋅
φ
˙
(
0
)
w
i
t
h
γ
1
<
γ
2
<
1
(2.13b)
\dot{\varphi}(\alpha_s) \geq \gamma_2 \cdot \dot{\varphi}(0) \quad with \, \gamma_1 < \gamma_2 < 1 \tag{2.13b}
φ˙(αs)≥γ2⋅φ˙(0)withγ1<γ2<1(2.13b)
注意:这里的 φ ˙ \dot{\varphi} φ˙是负数
如果对 α \alpha α 的初始猜测值满足这两个准则,那么我们接受它作为 α s \alpha_s αs。否则,我们必须使用对应的算法进行迭代,以进行精确的线搜索。详细信息见 Frandsen et al (2004) 的第2.5节。
2.4. 信赖域和阻尼方法
假设我们在当前迭代
x
\pmb{x}
xxx 的附近有一个
F
F
F 行为的模型
L
L
L,
F
(
x
+
h
)
≈
L
(
h
)
=
F
(
x
)
+
h
T
c
+
1
2
h
T
B
h
(2.14)
F(\pmb{x}+\pmb{h}) \approx L(\pmb{h}) = F(\pmb{x})+\pmb{h}^T c + \frac{1}{2}\pmb{h}^T\pmb{B}\pmb{h} \tag{2.14}
F(xxx+hhh)≈L(hhh)=F(xxx)+hhhTc+21hhhTBBBhhh(2.14)
其中 c ∈ R n \pmb{c} \in \mathbb{R}^n ccc∈Rn 并且矩阵 B ∈ R n × n \pmb{B} \in \mathbb{R}^{n \times n} BBB∈Rn×n 是对称的。本节的基本思想可以推广到其他形式的模型,但在本手册中,我们只需要在(2.14)中给出的 L L L 的形式。通常,该模型是 F F F 在 x \pmb{x} xxx 附近的二阶泰勒展开,就像公式(1.4a)的右边的前三项一样,或者 L ( h ) L(h) L(h) 可能是这个展开的近似。一般来说,只有当 h \pmb{h} hhh 足够小时,这个模型才是好的。我们将介绍两种包含这种思想的用于确定 h \pmb{h} hhh 的方法,其中 h \pmb{h} hhh 是一个下降方向,可以在算法 2.4 中当 α = 1 \alpha = 1 α=1 的情况下使用。
在信赖域方法中,我们假设我们知道一个正数 Δ \Delta Δ,这样模型在半径为 Δ \Delta Δ、以 x \pmb{x} xxx 为中心的球内足够精确,并确定步长为
h = h t r = a r g m i n ∣ ∣ h ∣ ∣ < Δ { L ( h ) } (2.15) \pmb{h} = \pmb{h}_{tr}=argmin_{||\pmb{h}||<\Delta}\{L(\pmb{h})\} \tag{2.15} hhh=hhhtr=argmin∣∣hhh∣∣<Δ{L(hhh)}(2.15)
在一种阻尼方法中,该步长由以下公式确定
h
=
h
d
m
=
a
r
g
m
i
n
h
{
L
(
h
)
+
1
2
μ
h
T
h
}
(2.16)
\pmb{h} = \pmb{h}_{dm} = argmin_{\pmb{h}} \{L(\pmb{h})+\frac{1}{2}\mu \pmb{h}^T\pmb{h}\} \tag{2.16}
hhh=hhhdm=argminhhh{L(hhh)+21μhhhThhh}(2.16)
其中,阻尼参数 μ ≥ 0 \mu \geq 0 μ≥0。项 1 2 μ h T h = 1 2 μ ∣ ∣ h ∣ ∣ 2 \frac{1}{2}\mu \pmb{h}^T\pmb{h} = \frac{1}{2} \mu ||\pmb{h}||^2 21μhhhThhh=21μ∣∣hhh∣∣2 用于惩罚大的步长。
基于这些方法之一的算法 2.4 的核心部分具有以下形式
C
o
m
p
u
t
e
h
b
y
(
2.15
)
o
r
(
2.16
)
i
f
F
(
x
+
h
)
<
F
(
x
)
x
:
=
x
+
h
U
p
d
a
t
e
Δ
o
r
μ
(2.17)
\begin{matrix} Compute \, h \, by \, (2.15) \, or \, (2.16) \\ if \, F(\pmb{x}+\pmb{h})<F(\pmb{x}) \\ \quad \quad \quad \pmb{x}:=\pmb{x}+\pmb{h} \\ Update \, \Delta \, or \, \mu\end{matrix} \tag{2.17}
Computehby(2.15)or(2.16)ifF(xxx+hhh)<F(xxx)xxx:=xxx+hhhUpdateΔorμ(2.17)
如果步长 h \pmb{h} hhh 满足下降条件(2.1),则这对应于 α = 1 \alpha = 1 α=1。否则, α = 0 \alpha=0 α=0,即我们不移动。然而,我们并没有停留在 x \pmb{x} xxx 上(除非 x = x ∗ \pmb{x}=\pmb{x}^∗ xxx=xxx∗):通过对 Δ \Delta Δ 或 μ \mu μ 的适当修改,我们的目标是在下一步迭代中获得更好的解。
这些方法有一些版本,它们包含适当的线搜索来找到具有较小 F F F 值的点 x + α h \pmb{x}+\alpha \pmb{h} xxx+αhhh,以及在线搜索过程中收集的信息用于更新 Δ \Delta Δ 或 μ \mu μ。对于许多问题,这样的版本使用更少的迭代步骤,但具有更大的累积下降的函数值。
由于假设 L ( h ) L(\pmb{h}) L(hhh) 是当 h \pmb{h} hhh 足够小时 F ( x + h ) F(\pmb{x}+\pmb{h}) F(xxx+hhh) 的一个很好的近似,所以这个步骤失败的原因是 h \pmb{h} hhh 太大了,应该被减少。此外,如果该步长被接受,则可以在新的迭代中使用更大的步长,从而减少在我们达到 x ∗ \pmb{x}^∗ xxx∗之前所需的迭代次数。
在之后的表述中针对 α h \alpha \pmb{h} αhhh 和 h \pmb{h} hhh 我们统一使用步长这一术语,不做区分,但根据上下文可以很容易明白具体的指代。
使用计算出来步长的模型的质量可以通过所谓的增益比来评估
℘
=
F
(
x
)
−
F
(
x
+
h
)
L
(
0
)
−
L
(
h
)
(2.18)
\wp = \frac{\pmb{F}(\pmb{x})-F(\pmb{x}+\pmb{h})}{L(0)-L(\pmb{h})} \tag{2.18}
℘=L(0)−L(hhh)FFF(xxx)−F(xxx+hhh)(2.18)
即函数值的实际下降和模型的预测下降之间的比率。通过构造,分母是正的,如果步长不是向下的,那么分子就是负的—它太大了,应该被减少。
在信赖域方法中,我们通过半径 Δ \Delta Δ 的大小来控制步长。以下的更新策略被广泛使用,
i f ℘ < 0.25 Δ : Δ / 2 e l s e i f ℘ > 0.75 Δ : m a x { Δ , 3 ∗ ∣ ∣ h ∣ ∣ } (2.19) \begin{matrix} if \, \wp < 0.25 \\ \quad \quad \quad \Delta:\Delta/2 \\ elseif \, \wp >0.75 \\ \quad \quad \quad \quad \quad \quad \quad \quad \Delta:max\{\Delta,3 * ||\pmb{h}||\}\end{matrix} \tag{2.19} if℘<0.25Δ:Δ/2elseif℘>0.75Δ:max{Δ,3∗∣∣hhh∣∣}(2.19)
因此,如果 ℘ < 0.25 \wp < 0.25 ℘<0.25,则我们决定使用较小的步长,而 ℘ > 0.75 \wp > 0.75 ℘>0.75 则表示可以使用较大的步长。信赖域算法对阈值 0.25 0.25 0.25 和 0.75 0.75 0.75、除数 p 1 = 2 p_1=2 p1=2 或因子 p 2 = 3 p_2=3 p2=3 的微小变化不敏感,但重要的是数字 p 1 p_1 p1 和 p 2 p_2 p2 的选择必须确保 Δ \Delta Δ 值不能振荡。
而在阻尼法中,小的 ℘ \wp ℘ 表示我们应该增加阻尼因子,从而增加大对大的步长的惩罚。较大的 ℘ \wp ℘ 表示对于计算得到的 h \pmb{h} hhh, L ( h ) L(\pmb{h}) L(hhh) 是 F ( x + h ) F(\pmb{x}+\pmb{h}) F(xxx+hhh) 的良好近似,并且阻尼参数可以减小。一种广泛使用的策略如下,它类似于(2.19),最初是由Marquardt(1963)提出的,
i f ℘ < 0.25 μ : = μ ∗ 2 e l s e i f ℘ > 0.75 μ : = μ / 3 (2.20) \begin{matrix} if \, \wp < 0.25 \\ \quad \quad \quad \mu:=\mu *2 \\ elseif \, \wp >0.75 \\ \quad \quad \mu:= \mu/3\end{matrix} \tag{2.20} if℘<0.25μ:=μ∗2elseif℘>0.75μ:=μ/3(2.20)
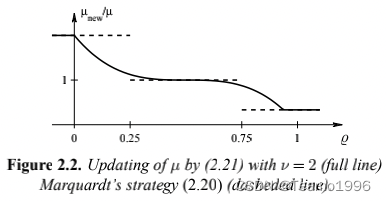
同样,该方法对阈值 0.25 0.25 0.25 和 0.75 0.75 0.75 或数字 p 1 = 2 p_1=2 p1=2 和 p 2 = 3 p_2=3 p2=3 的微小变化不敏感,但重要的数字 p 1 p_1 p1 和 p 2 p_2 p2 的选择必须确确保 μ \mu μ 值不能振荡。经验表明,穿越阈值 0.25 0.25 0.25 和 0.75 0.75 0.75 时 μ \mu μ 值的不连续变化会导致“颤振”(如例 3.7 所示),从而减慢收敛速度,我们在Nielsen(1999)中证明,以下策略总体上优于(2.20),
i f ℘ > 0 μ : = μ ∗ m a x { 1 3 , 1 − ( 2 ℘ − 1 ) 3 } ; v : = 2 e l s e μ : = μ ∗ v ; v : = 2 ∗ v (2.21) \begin{matrix} if \, \wp > 0 \\ \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \mu:=\mu*max\{\frac{1}{3},1-(2\wp -1)^3\}; \quad v:=2 \\ else\\ \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \mu:= \mu*v; \quad v:=2*v\end{matrix} \tag{2.21} if℘>0μ:=μ∗max{31,1−(2℘−1)3};v:=2elseμ:=μ∗v;v:=2∗v(2.21)
因子
ν
ν
ν 被初始化为
ν
=
2
ν=2
ν=2。请注意,一系列连续的失败结果会导致
μ
\mu
μ 值的快速增加。这两个更新公式的行为如下图所示。
2.4.1. 步长的计算
在阻尼方法中,步长被计算为以下函数的一个驻点
ψ
μ
(
h
)
=
L
(
h
)
+
1
2
μ
h
T
h
\psi_{\mu}(\pmb{h}) = L(\pmb{h}) + \frac{1}{2} \mu \pmb{h}^T\pmb{h}
ψμ(hhh)=L(hhh)+21μhhhThhh
这意味着 h d m \pmb{h}_{dm} hhhdm 是以下方程的解
ψ ˙ μ ( h ) = L ˙ ( h ) + μ h = 0 \dot{\psi}_{\mu}(\pmb{h}) = \dot{L}(\pmb{h})+\mu \pmb{h} = 0 ψ˙μ(hhh)=L˙(hhh)+μhhh=0
从(2.14)中的
L
(
h
)
L(\pmb{h})
L(hhh) 的定义中我们可以看出,以上方程等价于
(
B
+
μ
I
)
h
d
m
=
−
c
(2.22)
(\pmb{B}+\mu \pmb{I})\pmb{h}_{dm}= -c \tag{2.22}
(BBB+μIII)hhhdm=−c(2.22)
其中, I \pmb{I} III 是单位矩阵。如果 μ \mu μ 足够大,对称矩阵 B + μ I \pmb{B}+\mu \pmb{I} BBB+μIII 是正定的(见附录A),然后从定理 1.8 得出, h d m h_{dm} hdm 是 L L L 的最小值。
示例 2.1.
在阻尼牛顿法中,模型
L
(
h
)
L(\pmb{h})
L(hhh) 由
c
=
F
˙
(
x
)
c=\dot{F}(\pmb{x})
c=F˙(xxx) 和
B
=
F
¨
(
x
)
B=\ddot{F}(\pmb{x})
B=F¨(xxx) 给出,则(2.22)具有以下形式
(
F
¨
(
x
)
+
μ
I
)
h
d
n
=
−
F
˙
(
x
)
(\ddot{F}(\pmb{x})+\mu \pmb{I})\pmb{h}_{dn}=-\dot{F}(\pmb{x})
(F¨(xxx)+μIII)hhhdn=−F˙(xxx)
h
d
n
h_{dn}
hdn 是所谓的阻尼牛顿步长。如果
μ
\mu
μ 很大,则
h
d
n
≈
−
1
μ
F
˙
(
x
)
\pmb{h}_{dn} \approx - \frac{1}{\mu} \dot{F}(\pmb{x})
hhhdn≈−μ1F˙(xxx)
即向接近最陡下降方向走的一小步。另一方面,如果 μ \mu μ 非常小,那么 h d n \pmb{h}_{dn} hhhdn 就接近牛顿步长 h n \pmb{h}_n hhhn。因此,我们可以认为阻尼牛顿法是最陡下降法和牛顿法的混合方法。
我们在 3.2 节中重新回到阻尼方法。
在信赖域方法中,步长
h
t
r
\pmb{h}_{tr}
hhhtr 是一个带约束优化问题的解,
m
i
n
i
m
i
z
e
L
(
h
)
s
u
b
j
e
c
t
t
o
h
T
h
≤
Δ
2
(2.23)
\begin{matrix} minimize \quad L(\pmb{h}) \\ subject \, to \quad \pmb{h}^T\pmb{h} \leq \Delta^2 \end{matrix} \tag{2.23}
minimizeL(hhh)subjecttohhhThhh≤Δ2(2.23)
详细讨论这个问题不在本手册的范围之内(见 Madsen et al (2004) 或 Nocedal and Wright (1999) 的第4.1节)。我们只想提到一些属性。
如果(2.14)中的矩阵
B
\pmb{B}
BBB 是正定的,则
L
L
L 的无约束最小值是以下方程的解
B
h
=
−
c
\pmb{B}\pmb{h} = -\pmb{c}
BBBhhh=−ccc
如果这足够小(如果它满足 h T h ≤ Δ 2 \pmb{h}^T\pmb{h} \leq \Delta^2 hhhThhh≤Δ2),那么这是期望的步长 h t r \pmb{h}_{tr} hhhtr。否则,约束是被激活的的,问题就更加复杂。使用与我们在线搜索中使用的类似的论证,我们可以看到我们不需要计算(2.23)的真正解,并且在第 3.3 和 3.4 节中,我们提出了两种计算 h t r \pmb{h}_{tr} hhhtr 近似解的方法。
最后,我们指出两个在
B
\pmb{B}
BBB 是正定的情况下阻尼方法和信赖域法的相似之处:如果无约束最小值在信赖域之外,可以证明(Madsen et al (2004) 中的定理 2.11)存在一个
λ
>
0
\lambda > 0
λ>0 满足
B
h
t
r
+
c
=
−
λ
h
t
r
(2.24 a)
\pmb{B}\pmb{h}_{tr}+\pmb{c} = - \lambda \pmb{h}_{tr} \tag{2.24 a}
BBBhhhtr+ccc=−λhhhtr(2.24 a)
通过对该方程进行重新排列并与(2.22)进行比较,我们发现
h
t
r
\pmb{h}_{tr}
hhhtr 与用阻尼参数
μ
=
λ
\mu = \lambda
μ=λ 计算的阻尼步长
h
d
m
\pmb{h}_{dm}
hhhdm 是相同的。另一方面,我们也可以证明( Frandsen et al (2004) 中的定理 5.11 ),如果我们为给定的
μ
≥
0
\mu \geq 0
μ≥0 计算
h
d
m
\pmb{h}_{dm}
hhhdm,那么
h
d
m
=
a
r
g
m
i
n
∣
∣
h
∣
∣
≤
∣
∣
h
d
m
∣
∣
{
L
(
h
)
}
(2.24 b)
\pmb{h}_{dm}=argmin_{||\pmb{h}|| \leq ||\pmb{h}_{dm}||} \{L(\pmb{h})\} \tag{2.24 b}
hhhdm=argmin∣∣hhh∣∣≤∣∣hhhdm∣∣{L(hhh)}(2.24 b)
也就是说 h d m \pmb{h}_{dm} hhhdm 等于信赖域半径 Δ = ∣ ∣ h d m ∣ ∣ \Delta = ||\pmb{h}_{dm}|| Δ=∣∣hhhdm∣∣ 的 h t r \pmb{h}_{tr} hhhtr。因此,这两类方法是密切相关的,但是没有一个简单的公式来说明 Δ \Delta Δ 值和 μ \mu μ 值之间的关系,从而给出相同的步长。














 3011
3011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









