







最小二乘非线性优化整理
泰勒展开
在整理非线性最小二乘问题之前,先整理一个预备知识,泰勒展开。
这里直接放上一个很不错的学习视频,看完这个我就开始在B站学数学了。
泰勒级数
这是一位博主对该视频做了一个简单的总结: 泰勒级数博客
泰勒展开的公式如下:
f
(
x
)
=
f
(
a
)
0
!
+
f
′
(
a
)
1
!
(
x
−
a
)
+
f
′
′
(
a
)
2
!
(
x
−
a
)
2
+
.
.
.
+
f
(
n
)
(
a
)
n
!
(
x
−
a
)
n
+
R
n
(
x
)
f(x) = \frac{f(a)}{0!} + \frac{f'(a)}{1!}(x-a) + \frac{f''(a)}{2!}(x-a)^2 + ...+ \frac{f^{(n)}(a)}{n!}(x-a)^n +R_n(x)
f(x)=0!f(a)+1!f′(a)(x−a)+2!f′′(a)(x−a)2+...+n!f(n)(a)(x−a)n+Rn(x)
从视频中我们可以知道,泰勒展开其实就是用一系列的多项式来在a点附近拟合一个复杂的函数。本质上就是让多项式与原函数的各级导数保持一致,从而在a点附近保持比较高的一致性。
接下来的内容则是从一篇文章中截取的:
METHODS FOR NON-LINEAR LEASTSQUARES PROBLEMS
最小二乘问题与非线性优化
问题定义:

这个问题定义可能看着不是很明朗,但带上数据拟合的例子就比较清楚了。
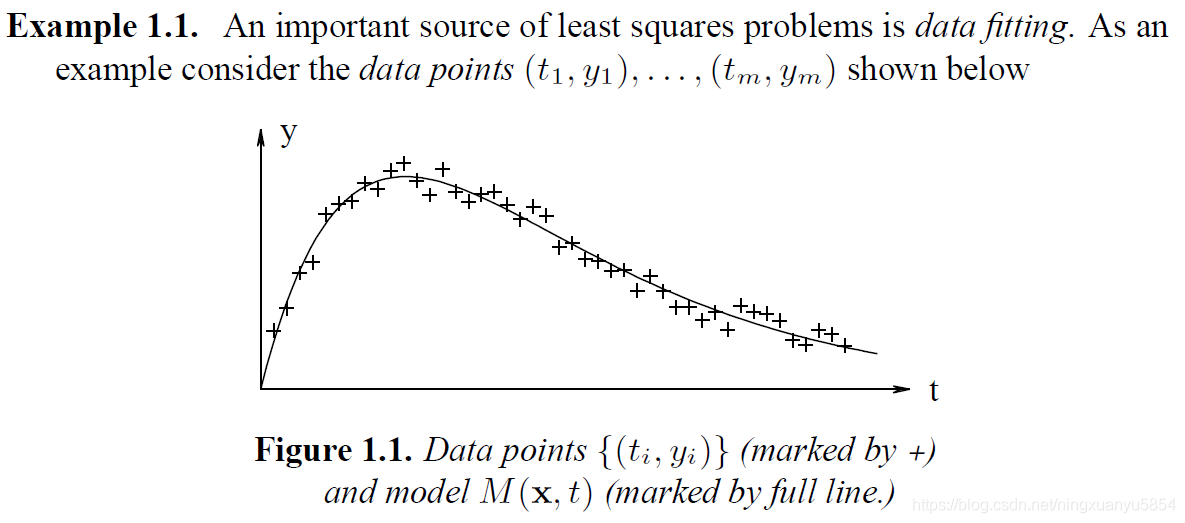
数据点与待拟合模型之间总是有误差的,设拟合模型为
M
(
x
,
t
)
=
x
3
e
x
1
t
+
x
4
e
x
2
t
M(x,t) = x_3e^{x_1t}+ x_4e^{x_2t}
M(x,t)=x3ex1t+x4ex2t
该模型的系数为
x
=
[
x
1
,
x
2
,
x
3
,
x
4
]
T
x = [x_1, x_2, x_3, x_4]^T
x=[x1,x2,x3,x4]T,这是待求的。那么最小二乘的的目的就是计算一个最优的
x
′
x'
x′, 使
y
i
y_i
yi 与
M
(
x
′
,
t
i
)
M(x',ti)
M(x′,ti)的误差之和最小。与公式1.1对应,也就是
F
(
x
)
=
1
2
∑
i
=
1
m
(
y
i
−
M
(
x
,
t
i
)
)
2
F(x) = \frac{1}{2}\sum\limits_{i = 1}^m (y_i - M(x,ti))^2
F(x)=21i=1∑m(yi−M(x,ti))2
【m表示数据点的个数,其中
f
(
x
i
)
=
(
y
i
−
M
(
x
,
t
i
)
)
f(x_i) = (y_i - M(x,ti))
f(xi)=(yi−M(x,ti)) 被称为cost function】
求取全局最优解是很复杂的。在后面的解释中,我们只给出一个较为简单的解决方案,也就是求取局部最优解。问题定义为:

这也是非线性最优化问题的基本解题思路,寻找
F
(
x
)
F(x)
F(x) 的下降方向,持续迭代直至该函数无法再下降。【从定义1.1可以看出
F
(
x
)
F(x)
F(x) 总是大于等于0 的。只要 F(x) 不断减小,那么就拟合的越好。在ICP匹配中,就是使用最小二乘,不断迭代来找到使总体匹配误差最小的情况,从而求得位移矩阵及旋转矩阵。】

原泰勒公式描述的是复杂函数在a点的拟合公式,那么对于a+h,其泰勒公式为
f
(
a
+
h
)
=
f
(
a
)
0
!
+
f
′
(
a
)
1
!
(
h
)
+
f
′
′
(
a
)
2
!
(
h
)
2
+
.
.
.
+
f
(
n
)
(
a
)
n
!
(
h
)
n
+
R
n
(
a
+
h
)
f(a+h) = \frac{f(a)}{0!} + \frac{f'(a)}{1!}(h) + \frac{f''(a)}{2!}(h)^2 + ...+ \frac{f^{(n)}(a)}{n!}(h)^n +R_n(a+h)
f(a+h)=0!f(a)+1!f′(a)(h)+2!f′′(a)(h)2+...+n!f(n)(a)(h)n+Rn(a+h)
然后用x来替换a,就可以得到1.4a的公式。
后面是两个定理。如果一个点,其一次导数等于0,附近的二次导数是正定的,那么该点就是局部最小点。二次导数正定意味着一次导数是递增的,也就意味着该点附近的一次导数,左边小于0,右边大于0。也就是该点左边是递减的,右边是递增的。那么显然该点是一个局部最小点。


总之,最小二乘的目标就是找到一个点,使总误差最小。而为了达到这个目标,所有的非线性优化方法都是通过迭代来完成的。每次迭代都需要满足
F
(
x
k
+
1
)
<
F
(
x
k
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(
2.1
)
F(x_{k+1}) < F(x_k) ...............................(2.1)
F(xk+1)<F(xk)...............................(2.1)


那么第一个方法也就呼之欲出了。
h
T
h^T
hT就是我们想要求的迭代增量。下面介绍非线性优化的常用方法。
下降法 (Descent methods)
最速下降法 (The Steepest Descent method)
最速下降法也叫梯度法,此方法只需要计算原函数的一次导数,故计算速度比较快。从前面的定义2.6也可以大概看出,要想满足该条件,那么显然
h
T
=
−
F
′
(
x
)
h^T = -F'(x)
hT=−F′(x)。具体的推导见下。【注意,
c
o
s
(
θ
)
cos(\theta)
cos(θ)中的
θ
\theta
θ指的是
h
h
h 与
F
′
(
x
)
F'(x)
F′(x)的夹角】

从几何角度来看,最速下降法的下降方向就是与该点切线方向(一次导数)相反的方向。该方法的优势在于计算速度快,对初始位置要求低,但在最终的收敛阶段会比较慢,容易陷入局部最优。
牛顿法(Newton’s Method)
最速下降法只利用了一次导数的信息,并没有关注一次导数的变化趋势。只关注表面,而不掌握其背后的规律,这样肯定会被迷惑,栽跟头。比如当迭代到某一处,其附近的一次导数都为0时,最速下降法就停止迭代了,而这个点可算不上局部最优点(原文中称之为Stationary point, 驻点)。而牛顿法则更聪明一点,它还考虑了二次导数的信息。一次导数反映的函数值的变化趋势,而二次导数反映的则是一次导数的变化趋势。

牛顿法得到的结果可以确保是局部最优,其同时满足定理 1.5 和 1.8。但代价是较慢的下降速度与较复杂的计算(二次导数的计算)。那么很自然的,就会有人提出一种混合的方法。在初始阶段,使用最速下降法。在收敛阶段,使用牛顿法。

如果该点二次导数是正定的(初始阶段),使用最速下降法的下降方向。如果该点不是正定的(收敛阶段),那就使用牛顿法的下降方向。
该章节后面还介绍了怎么选取步长 α \alpha α,这不是我所关注的,有兴趣的可自己去看看原文。同样,后面还有对信赖域法和阻尼法的介绍。
非线性最小二乘问题(NON-LINEAR LEAST SQUARES PROBLEMS)
问题定义
下面的定义其实与前面的最小二乘问题是一样的,区别在于用 Jacobian Matrix 代替了一次导数, 用 Hessian Matrix 代替了 二次导数。关于线性代数,再次推荐B站学习视频:线性代数的本质 - 系列合集


高斯牛顿法(The Gauss–Newton Method)
3.7a 公式是用
l
(
h
)
l(h)
l(h) 来表示
f
(
x
+
h
)
f(x+h)
f(x+h)。 后面虽然看着复杂,其实也就是一些符号变换,比如用 f 表示 f(x), 用 J 表示 J(x) , 为了将问题说的更清楚。涉及一些线性代数的知识。这里的转置是为了维度匹配,简单理解可以直接看成是乘法就好。比如
f
T
f
f^Tf
fTf 直接看成
f
2
f^2
f2 即可。而此处得到的结果 3.9,你会发现跟 2.9a 是一样的。 知道怎么求每次的下降方向,也就解决了问题了。


然而,一般牛顿高斯法只是一个引子,真正高效常用的方法是 LM 方法,一种带阻尼的高斯牛顿法。通过阻尼来混合使用高斯牛顿法和最速下降法。
The Levenberg–Marquardt Method
LM算法与 高斯牛顿法的区别在于其加入了一个阻尼因子,从而将 公式 3.11 中的 J T J J^T J JTJ 变成了 J T J + μ I J^T J + \mu I JTJ+μI, 得到下面的 3.13 式。这个 μ \mu μ 虽然看着不起眼,但作用巨大。
- 确保了二次导数是正定的,这意味着在未到达最优点之前,求得的增量肯定是下降的。
- 当 μ \mu μ 比较大时, LM算法类似于最速下降法,这意味着该算法对初始迭代点要求不高。
- 当 μ \mu μ 较小时,LM 算法类似于高斯牛顿法,有利于收敛到最优解。
- 与前面方法相比,此动态步长更加灵活高效。
后面描述了
μ
\mu
μ 的初始值选取以及如何更新的。
μ
\mu
μ 的更新取决于一个更新比公式。该公式分子部分是原函数在某个点的增量,分母部分是近似函数在该点的增量。根据此增量比来更新
μ
\mu
μ 。


下面是 LM 算法的伪代码。总体架构和前面的一样。

最后放上一篇论文,使用 FPGA 对非线性优化最小二乘问题做加速。【虽然非线性优化需要求解高维矩阵的逆,但评估发现其运算很快,只有几十us。】
Pang Y, Wang S, Peng Y, et al. A microcoded kernel recursive least squares processor using fpga technology[J]. ACM Transactions on Reconfigurable Technology and Systems (TRETS), 2016, 10(1): 1-22.
如果有什么地方写的有问题,欢迎大佬们批评指正。

















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









