









代码:https://github.com/KaiyangZhou/ROI-Selection
论文:https://uk.mathworks.com/help/matlab/ref/colormap.html
Abstract
我们解决了RGB-D数据中行人检测的问题,我们利用深度信息开发了一个感兴趣区域(ROI)选择方法,该方法为彩色和深度两种CNNs提供了建议。为了结合两个CNN产生的检测结果,我们提出了一种基于深度图像特征的新型融合方法。 我们还提出了一种新的深度编码方案,它不仅可以将深度图像编码为三个通道,还可以增强分类信息。我们对公共可用的RGB-D人数据集进行了实验,并证明我们的方法优于仅使用RGB数据的基线模型。
1 Introduction
RGB-D图像通过提供深度和颜色值来封装更丰富的信息。在RGB-D行人检测中,深度信息通常用于减少搜索空间[1]。例如,Jafari等[2]使用深度像素通过将每个像素分类为三个类别中的一个来提取感兴趣区域(ROI):地平面,ROI(对象)和非ROI(建筑物和墙壁)。张等人[3]去除地平面和天花板,然后根据沿深度维度的密度分布提出ROI。在本文中,我们还利用深度信息来移除地平面,但我们通过利用深度特征进一步约束ROI。
卷积神经网络(CNNs)在彩色图像领域显示出特有的辨别力[4],已成功应用于行人检测。 Angelova等人[5]提出了一个级联框架,包括几个用于行人检测的CNN,其中通过密集的滑动窗口获得建议。但是每个级联阶段中的每个CNN都会重复应用于每个提案,而不会在卷积上共享计算。我们还使用CNN进行提案分类,但是在整个图像上只进行一次卷积,这是由Girshick [6]提出的ROI池实现的。 ROI池化为最后一组卷积特征图中的每个ROI窗口提取固定大小的特征向量,并将这些特征向量转发到(Forwards)完全连接的层,这实际上需要固定大小的输入。
CNN也已应用于RGB-D图像以进行行人检测,例如[7,8]。然而,在[7]中,深度没有被包括在分类中。梅斯等人 [8]开发了一种CNN混合物,可以从不同的模态(包括颜色,深度和运动)中独立提取特征,并使用选通(Gating)网络对其进行融合以进一步分类。然而,他们使用传统的滑动窗口方法来生成提案,忽略了 the potential of depth for ROI selection。在本文中,我们分别应用两个CNN来学习颜色和深度图像的特征。它们分别对每种模态的ROI进行人工检测,然后将这些结果融合在一起,以获得更可靠的检测。
我们在本文中的贡献是:(a)我们开发了一种基于深度的快速ROI选择方法以减少搜索空间,(b)我们提出了一种基于CNN的RGB-D行人检测器,我们设计了一种新的融合方法。从RGB和深度图像的切片,(c)我们提出了一种快速深度编码方法,它可以产生三通道深度图像,在信息显着性方面接近彩色图像。这允许CNN通过传递预先学习(pre-learnt)的颜色特征来更有效地部署深度信息。
2 Proposed Approach
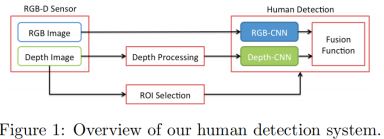
图1给出了行人检测系统的简要概述。 ROI选择模块利用深度信息,以减少搜索空间和生成一组候选提案。 深度处理模块使用均值滤波器填充深度图像中的孔,然后对填充的图像进行编码进入三个通道。 这两个网络,RGB-CNN和深度-CNN,在人体检测模块中,分别处理RGB和深度编码图像,为候选提议产生概率分数。对于每个提案,由两个概率分数产生两个网络由融合函数进行融合,导致更强的概率表明是否该提案包含一个人(上身)。最后,保留了具有高概率的提案然后通过非最大抑制NMS,最终得到的非重叠窗口列表。
2.1 Depth Processing
一个好的深度编码方法需要满足三个标准:(i)它应该尽可能多地保留原始深度中包含的信息,例如形状,(ii)它应该在计算上cheap,并且(iii)它应该产生一个具有与彩色图像相匹配的特征的图像,特别是在范围range和对比度contrast方面。基于这些,我们评估了现有的三种方法,即[9]中的①深灰色(DG)和②颜色深度(CD)以及来自[10]的③对比度增强深度灰色(CE),并提出了一种新的方案工作。特别是,④DG将深度像素标准化为具有0到255之间的值,然后将它们复制到三个通道。 CD通过反转喷射色图将每个标准化像素映射到三个通道,其中得到的颜色值范围从红色(近)到绿色到蓝色(远)(红橙黄绿青蓝紫)。 CE类似于DG,除了它在归一化之后和复制到三个通道之前执行直方图均衡。我们进一步提出了一种称为对比度增强色深度(CECD)的新深度编码方案,该方案在将像素映射到反转喷射色图之前执行直方图均衡。这四个方案在第3节进行了比较。
2.2 ROI Selection
ROI选择过程由三个阶段组成,如下所述(outlined below),它们共同产生候选提案。
地平面检测(GPD)——我们使用已知的深度相机内部参数将深度像素投影到全球3D世界(参见图2a)。为了在存在大量异常值(outliers)的情况下准确地确定地平面,我们将3D世界采样为10*10个单元的网格(参见图2b)。由于地面通常位于场景的下半部分,我们只从图像的下半部分采样点。对于每个箱(bin),我们计算跨越该区域(VSTD)的垂直列中的点的标准偏差。 VSTD值大于经验阈值的箱子(bin)被移除,其余的点被馈送到基于RANSAC的平面拟合算法[11]。这是基于以下观察结果:在垂直方向上主要分布的点的区域将包含较少的地面像素,因此应该被过滤掉。最后,靠近平面的像素对应于非ROI,并且其余像素被选择用于进一步的ROI选择。 Jafari等在[2]中检测地平面之前,还要使用outlier-reduction method。然而,他们移除了具有高密度点的箱,这可能导致移除可能包含在靠近相机的位置处属于地平面的像素的箱(在这种情况下,点非常紧凑)。
规模信息ROI搜索(SIS)----我们在剩余像素上滑动窗口。 每个像素的窗口宽度由深度值动态确定,这有利于避免耗时的多尺度搜索。 特别地,特定像素处的窗口宽度λ由下式确定,其中f是深度相机的焦距,W是一个普通人的大致宽度(我们用的0.6m),Z是深度值(单位m),我们只检测人的上半身,所以检测框是方形的。
候选提案过滤(CPF)---- 为了进一步减少提案(Proposals)数量,我们放弃那些主要包含由反射性能差poor reflective properties的对象产生的无效像素(无深度值)的提案。 为了有效地计算边界框中有效像素的数量,我们采用了积分图像 integral images的概念[12]。 仅当有效像素的部分大于阈值时才选择提议,例如三分之一。 该过程可以与SIS阶段并行执行,以保持计算快速。 图2c示出了有效(绿色)和无效(红色)提议的示例。

2.3 Human Detection with CNNs
我们系统的架构如图3所示。蓝色流网络(RGB-CNN)处理RGB图像,而绿色流网络(Depth-CNN)处理深度图像。它们在架构上是相同的,但不共享参数。我们使用CaffeNet[13]但是用双向分类层改变1000路分类层以适应我们的目的。 CaféfeNet本质上是AlexNet [4]的变体,其中池化和归一化层的顺序被调换。我们用ROI池化层替换第5个卷积层之后的最大池层[6]。 此外,我们遵循[6]通过截断的SVD重构FC6和FC7层,从而导致尺寸减小的重量参数,这有助于提高处理速度。 我们在测试时应用多尺度检测[6]。

RGB和深度检测的融合 --- 两个网络在每个域中独立工作,以对每个提案进行评分。 对于每个提议,RGB-CNN产生概率并且Depth-CNN产生概率,其中y = 1表示窗口包含人(上身),并且 Xc和Xd分别代表RGB和深度图像中的提议区域。 这两个概率被融合以推导出最终概率,这是对该提议进行分类的更有力的证据。 我们计算融合概率为
![]()
其中L(*|*)是对数似然,ω是依赖于提议深度的自适应权重,定义为
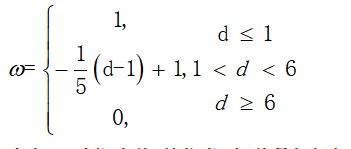 (2)
(2)
式中:d式深度值(单位米),阈值是根据经验设定的。在Eq(1),如果建议靠近摄像机,我们会给予深度信息更多的权重,而如果建议远离摄像机,我们更多地依赖于RGB信息。 这是因为大多数深度传感器的性能随着距离的增加而降低。 在深度图像中也容易观察到,距离相机较近的人比远处的人具有更清晰的形状(参见例如图2c)。
3 Experiments
数据集 - 对于训练数据,我们收集SPHERE [14]提供的正样本训练数据和NUYD2数据集[15]的负样本训练数据。这导致3271个正样本和7574个负样本。我们选择RGBD行人据集[16](数据集见文献16)来评估我们的方法。该数据集包含三个视频,每个视频包含1000多个RGB-D图像。我们发现这个子集中缺少一些标注,因此我们手动添加了任何缺失的标注.
网络训练 - 我们使用Caffe [13]用SGD算法训练和测试我们的网络(学习率0.001,动量0.9和权重衰减0.0005)。除了使用高斯分布初始化的新的双向分类层之外,所有网络都使用ImageNet权重进行初始化。微调应用于RGB-CNN(仅用于fc层)3个epochs,其中学习速率在2个epochs之后降低1/10。深度-CNN经过微调,具有不同的设置。对于每种深度编码方案(参见第2.1节),选择与RGB-CNN组合时产生最佳结果的方案用于以后的比较.
评估方法 - 为了评估,我们确定平均精度与平均召回率。我们采用“无奖励 - 无惩罚”规则[16],在50%重叠时进行正面检测,并对同一个人的重复检测进行处罚。我们使用三个模型作为基线:RCNN [17] +我们的ROI方法,我们的RGB-CNN +我们的ROI方法,以及我们的RGB-CNN +选择性搜索[18]。我们在RCNN中禁用了边界框回归,因为我们发现我们的提议方法对本地化错误不太敏感。我们通过将每个建议的高度设置为宽度来定制SelectiveSearch,特别是上身检测,仅保留细长建议的方形上部,并丢弃宽度<50像素的建议。前两个基线让我们评估了检测阶段使用深度信息的优势,以及我们提出的颜色和深度融合方法。与[17]中使用的SelectiveSearch相比,第三个基线允许评估我们的ROI方法。

4 Conclusion and Future Work
随着RGB-D摄像机的渗透以及视觉社区中基于CNN的快速和强大解决方案的潜力,人们需要解决人们在CNN中检测RGB-D数据的问题。 在本文中,我们提出了(1)纯粹基于深度的有效ROI选择方法,(2)深度编码方法和(3)用于人检测的双流CNN框架,包括新颖的颜色深度融合方法。 我们通过结合颜色和深度检测证明了我们的模型优于RGB基线。 将来,从数据中学习融合函数参数会很有趣,这将使我们能够在两个网络上进行端到端的训练。















 3654
3654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









