










论文:https://arxiv.org/pdf/1707.05733v1.pdf
Abstract
对象检测是在动态和变化的环境中运行的自动机器人的基本任务。机器人应该能够在存在传感器噪声的情况下也能检测物体,这些噪声可以通过改变摄像机的照明条件和范围传感器(尤其是RGB-D摄像机)的错误深度读数来引起。为了应对这些挑战,我们提出了一种用于物体检测的新型自适应融合方法,该方法以在线方式学习加权weighting不同传感器模态的预测。我们的方法基于卷积神经网络(CNN)专家的混合mixture,并结合了多种模态,包括外观,深度和运动。我们在广泛的机器人实验中测试我们的方法,其中我们在RGB-D数据的室内和室外组合场景中检测人,并且我们证明我们的方法可以适应严酷的光照变化和严重的相机运动模糊。此外,我们还提供了一个新的RGB-D数据集,用于在混合室内和室外环境中进行人体检测,并使用移动机器人进行记录。
1 Introduction
大多数在复杂环境中运行的自动机器人都配备了不同的传感器来感知周围环境perceive their surroundings。为了在对象检测任务的上下文中利用整个传感器信息,感知系统需要自适应地融合不同传感器模态的原始数据。这种传感器融合对物体检测具有挑战性,因为传感器噪声通常主要取决于环境条件,甚至可能正在改变。改变环境的示例场景是配备RGB-D传感器的机器人,其必须在一天中的不同时间或者在不同的天气条件下在室内和室外的黑暗场景中操作,例如自动驾驶汽车。我们的目标是使机器人的感知系统具有在没有人为干预的情况下自主适应当前条件的能力。例如,在黑暗的室内场景中,可以预期来自RGB-D设备的深度信息比视觉外观更可靠more reliable than。另外,在具有远离机器人的物体的阳光户外场景中,深度流不会提供非常丰富的信息。在本文中,我们证明了这些先验信息可以从原始数据中学习,而不需要任何手工制作的功能。因此,如何最好地结合不同的模态进行稳健的物体检测是我们要解决的主要问题。我们做出以下贡献:
- 我们基于深层网络专家experts的混合,引入了一种新的物体检测融合方案。
- 我们使用CNN学习自适应融合,CNN经过训练,可以根据从专家网络中提取的高级特征对专家分类器输出进行加权,而无需使用先验信息。
- 我们在广泛的实际实验中评估我们的方法,并证明它在变化的环境中比纯视觉purely vision-based或其他多模式融合方法other multimodal fusion approaches更强大 。

尽管我们的方法适用于任意数量的对象类,但在本工作中,我们主要报告了RGB-D域中行人检测的二分类问题的结果。首先,我们的实验结果显示,与公开提供的RGB-D People Unihall数据集[18]报告的其他融合方法相比show an increased performance of our method,我们的方法性能有所提高。其次,我们在更具挑战性的检测方案中评估我们的方法。我们记录了移动机器人的RGB-D序列,这些人在室内和室外的光照条件下突然变化。与先前记录的移动机器人数据集相比,序列显示机器人在不良照明的室内环境中移动,然后在短时间内进行非常明亮的室外场景。在本文中,当谈到变化或动态环境时,我们的意思是环境的基本条件(光照条件、室内室外)正在发生变化。潜在条件 underlying conditions的例子是
- 照明变化,
- 深度传感器超出范围读数,
- 反射材料会在RGB-D传感器的深度通道中产生传感器噪声
- 运动模糊。
2 RELATED WORK
在不断变化的环境中进行稳健物体检测的传感器融合是许多机器人应用的核心。在过去,大部分工作都集中在人类和一般物体检测的背景下。 Yebes等人[24]结合外观和深度数据的特征结合DPM检测器来识别道路场景中的物体。通过对3D感知的HOG描述器建模,以通道融合方式合并这些特征。与他们的方法相比,我们的方法旨在在最后阶段结合特征 combine features。 Enzweiler等[6]引入了一种专家混合方法,使用三种输入方式进行人体检测,即外观,运动和深度。与我们的方法相比,专家的权重是恒定的constant,因此不具有适应性no adaptive。 Premebida等[16]训练了具有手动设计特征的后期融合SVM,以从RGB和深度模态执行检测器融合。在我们的工作中,我们不使用任何先验信息来学习融合的权重,尽管可以将我们的方法与手动设计的融合特征结合使用。 Spinello等[19]提出了一种hierarchical mixture of experts approach,其中各个探测器的输出基于传感器模态中的缺失信息进行加权。与他们的方法相比,我们的加权函数直接从原始输入数据的特征表示中学习。最近,后期融合网络架构已经证明非常适用于视觉任务,例如多模态行人检测[17],[22],RGB-D物体识别[5]和RGB-D物体检测[8]。因此,我们将测试类似的后期融合网络架构作为基线,以便与我们的方法进行比较。
我们的工作还涉及多模式行人检测领域,重点是配备RGB-D传感器的移动平台。 Hosseini等[10]提出了一种多模式方法,该方法结合了基于深度的近距离上身检测器和基于地面HOG特征的同时基于外观的全身检测器。两种模态的检测被馈送到基于多假设EKF的跟踪模块。与随时间过滤相比,我们的方法在每帧的基础上执行融合。为了进一步比较,我们将读者引用到Spinello等人的工作中[18],穆纳罗等[14]和Linder等人[13]。
在视觉社区中有大量针对行人检测的研究[21],[15]。有关行人检测的简要概述,我们refer to参考 Benenson等人最近的讨论[2]。他们得出结论,改进的检测性能已经表现为由更好的功能设计驱动,但也辅以额外的数据,如图像上下文和运动。为了证明由卷积神经网络学习的特征的质量,Hosang等人[9]报告使用预先训练的现成CNN改善了行人检测结果。最近Angelova等人[1]提出了一种卷积网络架构,可处理RGB输入图像的较大区域并同时检测多个行人,从而在测试时显着加速。但是,这些方法都没有使用多种模态。
3 MIXTURE OF DEEP NETWORKS ARCHITECTURE
我们的检测方法基于深层网络专家(MoDE)的混合,并融合在一个额外的网络中,我们将进一步表示为门控网络gating network。 整体架构如图2所示,是专家混合方法[11]的扩展,它在门控网络的建模方面有所不同。 它将从每个专家网络的层次结构中的提取较高级别的特征表示作为输入,而不是使用原始方法中呈现的原始像素输入。 然后,门控网络根据其输入决定如何对每个专家的输出进行加权以产生最终分类器输出。设![]() 是训练样本,其中
是训练样本,其中![]() 表示一系列矩阵,描述M个不同along with的输入模态门控网络g。 输出类别标签编码的被定义为one-shot编码中的C维向量
表示一系列矩阵,描述M个不同along with的输入模态门控网络g。 输出类别标签编码的被定义为one-shot编码中的C维向量![]() 。
。

3.1 Fusion via mixture of experts
我们组合了i=1,..,M的专家分类器输出![]() --每个模态一个--通过门控函数
--每个模态一个--通过门控函数![]() 和
和![]() .设h表示由最后一个池化层生成的特征映射每个专家CNN(Let h denote a feature map produced by the last pooling layer of each expert CNN)。它可以被描述为尺寸为Nh*Hh*Wh(滤波器的数量,高度,宽度)的三维阵列。由此产生的连接特征映射
.设h表示由最后一个池化层生成的特征映射每个专家CNN(Let h denote a feature map produced by the last pooling layer of each expert CNN)。它可以被描述为尺寸为Nh*Hh*Wh(滤波器的数量,高度,宽度)的三维阵列。由此产生的连接特征映射![]() M专家是一个大小(Nh*M)*Hh *Wh阵列。
M专家是一个大小(Nh*M)*Hh *Wh阵列。 ![]() 的展平表示表示为 r(x),其是大小为1的一维数组1*(Nh* M* Hh* Wh)。
的展平表示表示为 r(x),其是大小为1的一维数组1*(Nh* M* Hh* Wh)。
因此,门控函数仅通过 representation表示 r(x)依赖于输入x,这显着地最小化了门控网络的输入维度。 每个分类器输出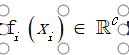 将原始像素输入映射到C输出 c = 1 ,..., C 然后可以将融合分类器输出写为
将原始像素输入映射到C输出 c = 1 ,..., C 然后可以将融合分类器输出写为
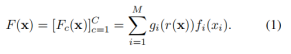
这可以表示为概率模型
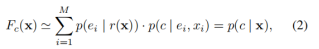
其中![]() 表示专家 i 选择的概率和
表示专家 i 选择的概率和![]() 表示单个专家对最终概率的贡献在整个类别 p(c|X)。 选通网络的最后一个内积层inner product layer的第i个输出表示为,softmax函数表示为
表示单个专家对最终概率的贡献在整个类别 p(c|X)。 选通网络的最后一个内积层inner product layer的第i个输出表示为,softmax函数表示为![]() 。 我们训练组合门控网络,并且使用交叉熵损失的架构定义为:
。 我们训练组合门控网络,并且使用交叉熵损失的架构定义为:

我们模型的最终架构如图2所示。对于以下检测任务,我们定义C = 2,表示背景和人类两个类。
3.2 Training a mixture of experts
我们使用两阶段方法训练我们的模型,在第一阶段,我们使用随机梯度下降(SGD)以端到端的方式训练各个专家网络。在本文中,我们使用了几种专家架构,一种标准的三层卷积神经网络作为基线,以及一种基于Google inception架构的更加深化的深度网络[20]。三层卷积神经网络是一个小型网络,旨在解决CIFAR-10分类问题并将进一步描述为CifarNet。 Hosang等人[9]也提出过这个问题作为行人检测的良好基线 good baseline。在实验环节中,我们考虑采用下采样的Google inception架构,描述为GoogLeNet-xxs。对于我们在实验环节中的第一个实验,CifarNet基线已经优于以前报告的方法。为了通过传感器融合留出改进空间,我们使用CifarNet作为单一专家的架构和专家网络的混合报告结果。在我们的第二个实验中,我们表明通过用初始架构替换网络,可以实现对CifarNet基线的进一步改进。对于GoogLeNet-xxs网络,我们仅使用原始网络的层到第一个softmax分类器(“softmax0”)。为了训练网络,我们使用Fast R-CNN [7],包括感兴趣区域池化和用于边界框回归的多任务Loss。该框架包含Caffe库的修改版本[12]。所有专家都使用标准参数进行训练,在第一阶段,我们仅在全连接层中应用dropout作为正则化器。此外,RGB模态的网络使用Caffe库[12]提供的预训练模型进行微调fine-tuned,而其他领域的专家the experts for the other domains则从头开始训练。在第二个训练阶段,门控网络在另一个验证集上进行训练。我们使用SGD优化门控网络的权重,并通过将所有层的学习率设置为零来保持各个专家的权重。虽然专家的权重没有改变,但我们对专家层进行了修改,以便对门控网络进行training。在所有专家层中,我们现在应用dropout作为数据增强的特例,以提高门控网络的性能。为了生成网络的感兴趣区域提议,我们实现了密集的多尺度滑动窗口方法a dense multiscale sliding window approach。在整篇论文中,我们使用不同的输入模式来提前通过网络。我们主要使用以下模式的组合:RGB,深度和光流(用于表示运动)。对于光流计算,我们使用Brox等人提出的方法的OpenCV实现[3]。
4 EXPERIMENTS
4.1 RGB-D People Unihall Dataset
我们在Spinello等人提供的公开可用的RGB-D People Unihall数据集上[18]评估我们的方法。该数据集包含超过3,000帧的人通过三个垂直安装的Kinect摄像机在大学走廊。作为评估指标,我们计算平均精度(AP)和均等错误率(EER)。我们将等误差率定义为精度 - 召回曲线中精度和召回值相等的点。采用他们的无奖励 - 无惩罚政策,当检测与部分被遮挡的人的标注相匹配时,我们不计算真正的true positives或false positives。对于训练,我们从三个Kinect摄像机中随机选择700帧,并从显示完全可见人物的标注候选者中提取正样本。为了评估,我们使用三个Kinect中的每一个的剩余300帧。为了设置学习过程的超参数,我们评估训练集上的所有训练模型,选择性能最佳的模型进行评估。此外,数据集不提供预定义的训练/测试分裂。因此,我们创建了五个随机训练/测试分裂,以训练和评估我们的检测器。我们获得了0.8 EER的标准偏差,显示了所选分裂的小影响。对于一些实验,由于文献中使用的评估指标不同,我们使用0.4和0.6的交叉联合(IoU)报告结果。除非另有说明,否则我们使用0.6的IoU进行评估,这是预测的边界框和带注释的地面实况框之间重叠的区域。
4.2 InOutDoor RGB-D People Dataset

Fig. 3. The dataset will be available online at http://www2.informatik.uni-freiburg.de/~eitel/InOutDoorPeople.html.

5 CONCLUSION
在本文中,我们考虑了多模态自适应传感器融合在变化环境中进行目标检测的问题。 我们提出了一种新的深度网络专家方法的混合,它自动学习一种自适应策略,用于从原始输入数据中加权多个基于域的分类器。 在广泛的实验中,我们证明了我们的多模态方法优于基于视觉的检测基线和其他融合技术。 此外,我们在从包含突然光照变化和严重运动模糊的移动机器人记录的序列中显示出改进的检测性能。 最后,我们的系统优于以前报告的公共可用RGB-D People数据集上基于深度的行人检测方法。















 2400
2400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









