








论文:https://arxiv.org/abs/1407.5736
Abstract
在本文中,我们使用语义丰富的图像和深度特征研究RGB-D图像的物体检测问题。我们提出了一种新的地心嵌入geocentric embedding?用于深度图像,除了水平差异之外,还为每个像素编码高于地面的高度和重力角度。我们证明这种地心嵌入?比使用原始深度图像更好地学习使用卷积神经网络的特征表示。我们的最终物体检测系统的平均精度达到37.3%,相对于现有方法的相对改进率为56%。然后,我们将重点放在实例分割的任务上,其中我们标记属于我们的检测器找到的对象实例的像素。对于此任务,我们提出了一种决策森林方法,它使用查询形状query shape和地心姿势特征 geocentric pose features.的一元和二元测试族将检测窗口中的像素分类为前景或背景。最后,我们使用现有超像素分类框架中的对象检测器的输出进行语义场景分割,并对我们研究的对象类别的当前最新技术实现24%的相对改进。我们相信本文所代表的进展将有助于在机器人领域使用感知。
1 Introduction
我们设计并实现了一个集成系统(图1),用于从RGB-D图像中进行场景理解。 整体架构是目前最先进的RGB图像中物体检测系统的概括,R-CNN [16],我们设计每个模块以有效利用RGB-D图像中的附加信号, 即像素深度。 我们通过为单个对象(如桌椅)提供像素级support maps以及场景表面(如墙壁和地板)的像素级标签来go beyond对象检测。 因此,我们的系统包含了传统上不同的对象检测和语义分割问题。 我们的方法总结如下(源代码可在http://www.cs.berkeley.edu/~sgupta/eccv14/获得)。

RGB-D轮廓检测和2.5D区域建议:RGB-D图像可以计算深度和正常梯度 normal gradients[18],我们将其与[9]中的结构化学习方法相结合,以产生明显的改善的轮廓。 然后,我们使用这些RGB-D轮廓通过计算深度和彩色图像上的特征来获得2.5D区域候选,以用于Arbelaz等人[1]的多尺度组合分组(MCG)框架Multiscale Combinatorial Grouping (MCG) framework。 该模块是 RGB-D proposal generation的最新技术。
RGB-D物体检测:在RGB图像上训练的卷积神经网络(CNN)是检测和分割的最先进技术[16]。 我们展示了可以调整在RGB图像上预训练的大型CNN,以生成深度图像的丰富特征。 我们建议通过三个通道(水平视差,地面高度和重力角度)来表示深度图像,并且表明该表示允许CNN学习比仅使用视差(或深度)更强的特征。 与现有方法相比,我们在改进的R-CNN框架中使用这些在我们的2.5D区域候选者上计算的特征,以获得RGB-D对象检测的56%相对改进。
实例分割:除了边界框对象检测,我们还推断了像素级物体掩模。 我们将此作为前景标记任务构建,并显示相对于基线方法的改进。
语义分割:最后,我们通过在[18]中提出的语义分割系统中使用对象检测来计算超像素的附加特征,从而提高语义分割性能(使用类别标记所有像素但不区分实例的任务)。 这种方法也为该任务获得了最先进的结果。
1.1 Related Work
关于RGB-D感知的大多数先前工作集中于语义分割[3,18,24,31,34],即为每个像素分配类别标签的任务。而
这是一个有趣的问题,许多实际应用需要更深入了解场景。值得注意的是,这样的输出中缺少对象实例的概念。相比之下,RGB-D图像中的物体检测[21,23,26,36,39]侧重于实例,但典型的输出是边界框。正如Hariharan等人。 [20]观察到,这些任务都不会产生令人信服的输出compelling output表示。机器人知道图像中存在大量“瓶子”像素这样是不够的。同样地,单个瓶子的粗略定位的边界框可能太不精确以至于机器人无法抓住它。因此,我们提出了一个框架,用于解决[20,37]提出的实例分割问题(描绘对应于每个检测的对象上的像素)。
最近,卷积神经网络[27]被证明对标准RGB视觉任务很有用,如图像分类[25],物体检测[16],语义分割[13]和细粒度分类[11]。自然地,最近关于RGB-D感知的工作已经考虑了将深度图像学习表示的神经网络用上[4,6,35]。 Couprie等人[6]适应Farabet等人[13]提出的多尺度语义分割系统,直接操作来自NYUD2数据集的四通道RGB-D图像。 Socher等[35]和Bo等人[4]查看RGB-D图像中的物体检测,但检测在受控实验室设置中成像的小型道具物体。在这项工作中,我们像NYUD2数据集一样处理不受控制的混乱环境。更重要的是,我们不是直接使用RGB-D图像,而是引入了一种新的编码方式,可以捕捉图像中像素的地心中心姿态,并表明它比天然使用深度通道产生了实质性的改进。
2 2.5D Region Proposals
在本节中,我们将描述如何扩展多尺度组合分组(MCG)[1]以有效利用深度线索来获得2.5D区域提议。
RGB-D轮廓检测是一项经过充分研究的任务[9,18,30,34]。在这里,我们结合了两种主要方法的思想[9]和我们过去在[18]中的工作。
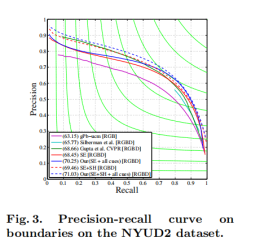
在[18]中,我们使用gPb-ucm [2]并提出了被称为NG-,NG+和DG的局部几何梯度来捕获凸,凹法线梯度convex, concave normal gradients和深度梯度。在[9]中,Doll'ar等人。提出了一种基于结构化随机森林的新型学习方法,将像素直接分类为轮廓像素。他们的方法将深度信息视为另一个图像,而不是根据地心数量对其进行编码,如NG-。虽然这两种方法在NYUD2轮廓检测任务(图3中的红色和蓝色曲线中的最大F测量点)上的表现相当,但任何一种方法产生的轮廓类型都存在差异。 [9]产生更好的局部轮廓,捕捉细节,但往往会错过[18]容易发现的正常不连续(例如,考虑图像左侧部分的墙壁和天花板之间的轮廓)。我们提出了一个综合的将[18]的特征与[9]的学习框架相结合的两种方法。具体来说,我们添加以下功能。
















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









