







Authors
Ross Girshick /Jeff Donahue/Trevor Darrell /Jitendra Malik

Ross Girshick
Abstract
R-CNN:Regions with CNN features. It combines two key insights:
1. apply cnns to bottom-up region proposals
2. supervised pre-training for an anuxiliary task(fine-tuning)
1 Introduction
1.1 from hog->cnns
The last decade of progress on various visual recognition tasks has been based on SIFT and HOG,which we could associate them with complex cells in V1, but they still perform poorly. we need more multi-stage processes for computing features.
Fukushinma–neocognitron– lacked a supervised training algorithm
LeCun et al. – SGD+backpropagation was effective for training CNNs
CNNs saw heavy use in 1990s, but then fell out of fashion with the rise of SVM, Krizhevsky et al. rekindled interest in CNNs,in ILSVRC 2012(rectifying non-linearities and “dropout” regularization) .
This paper is the first to show that a cnns can lead to dramatically higher object detection performance on PASCAL VOC than HOG-like features.
1.2 two problems
this paper focused on two problems: localizing objects with a deep network and training a high-capacity model with a small quantity of annotated data.
1. localization mathod
- as a regression problem
- sliding-window (loss precision) (overFeat)
2. fine-tuning
1.3 efficient
1.4 dominant error mode
a simple bounding-box regression method significantly reduce mislocalizations
2 Object detection with R-CNN
this system consists of three modules.
1. generates category-independent region proposals
2. extracts a fixed-length feature vector from region using cnn
3. linear SVMs
2.1 module design
2.1.1 region proposals
some examples: 1objectness, 2selective search, 3category-independent object proposals,4consitrained parametric min-cuts(CPMC),5multi-scale combinatorial grouping, 6ciresan….
we use selective search to enable a controlled comparsion with prior detection work.
J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders.Selective search for object recognition. IJCV, 2013.2.1.2 Feature extraction
Warp all pixels in a tight bounding box around it to the required size(227x227), prior to warping ,we dilate the box p(16) pixels.
2.2 test-time detection
This paper run selective search on the test image to extract around 2000 region proposals(fast mode), Given all scored regions (SVM) in an image, we apply a greedy non-maximum suppression that reject a region if it has an intersection over union**(IoU)** overlap with a higher socring selected region larger than a learned threshold.
2.2.1 run-time analysis
- cnn share parameters across all categories( and easier for different num_category)
- feature vectors computed by cnn are lower dimensional
13s/image on a gpu, 53s/image on a cup
feature matrix is 2000x4096, svm weight maxtrix is 4096xnumber of classes.
2.3 training
2.3.1 supervised pre-treining
caffe cnn library (nearly matches the performance of Krizhevsk et al.)
2.3.2 domain-specific fine-tuning
replacing the 1000way classification layer with a randomly initialized (N+1)-way classification layer.(plus 1 for background)
We treat all region proposals with >=0.5 IoU overlap with a ground-truth box as positives .
we start SGD at a learning rate of 0.001(1/10th of theinitial pre-training rate, not clobbering the initialization )
In each SGD iteration, we uniformly sample 32 positive windows + 96 background windows to construct a mini-batch of size 128.
2.3.2 Object category classifiers
for a background region, it is easy
but how to label a region taht partially overlaps a car. We resolve this issue with an IoU overlap threshold 0.3 (grid search over 0,0.1,0.2,…0.5, and defined differently in fine-tuning),below are defined as negatives.
Since the training data is too large to fit in memory, we adopt the standard hard negative mining method.
2.4 Results on PASCAL VOC 2010-2012
2010 53.7% 5011-2012 53.3% mAP
UVA same region proposal algorithm + four level spatial pyramid SIFT +nonlinear kernel svm–>35.1%
2.5 Results on ILSVRC2013
31.4%
OverFeat 24.3%
3 Visualization,ablation,and modes of error
3.1 Visualizing learned features
The idea is to single out a particular unit (feature) in the network and ust it as if it were an object detector in its own right.
The follow picture showing top regions for six pool5 units. each pool5 unit has a recptive field of 195x195.

3.2 Ablation studies
3.2.1 Performance layer-by-layer, without fine-tuning.
- Features from fc7 generalize worse than features from fc6, this means 29% of the parameters can be removed without degrading mAP.
- Pool4 features are computed using only6% parameters, but it can produces quite good results.
- 1,2–> Much of the CNN’s representational power comes from its convlutional layers .
- 3—> this finding suggests potential utility in computing a dense feature map (HOG-like) by using only the convolutional layers of CNN. This representaion would enable exprimentation with sliding-window detectors on top of pool5 features.
3.2.2 Performance layer-by-layer, with fine-tuning.
- The boost from fine-tuning is much larger for fc6 and fc7.
- 1–>suggests that the pool5 features learned from Image Net are general and that most of the imporvement is gained from l**earning domain-specific non-linear classifiers on top of them.**
3.2.3 comparision to recent feature learning methods
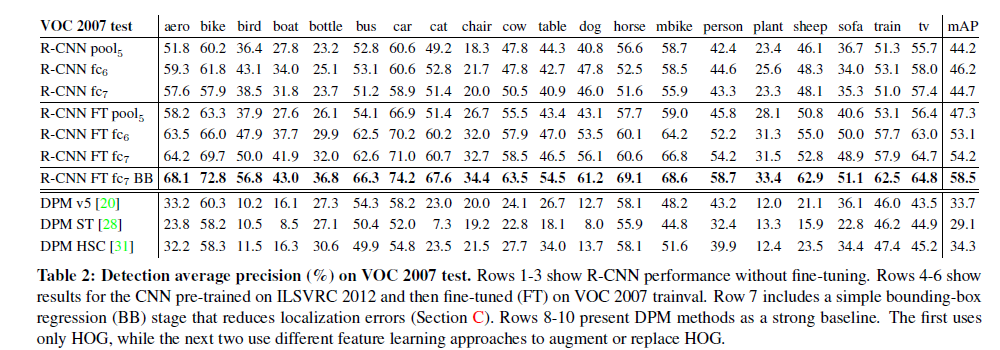
table2 rows8-10
3.3 Network architectures
We have found that the choice of architecure has a large effect on R-CNN detection performance.
1. O-net (13layers of 3x3 convs and 5 pooling layers) outperforms T-net
2. a considerable drawback :7 times longer (forward) than T-net
3.4 Detection error analysis
CNN features are much more discriminative than HOG, loose loaclization likely resluts from our use of bottom-up region proposals and the positional invariance learned from pre-training the CNN for whole-image calssification.

D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error
in object detectors. In 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









