






文章目录
- 一、什么是DSSM召回
- 二、为什么我们需要双塔召回
- 三、样本方面优化
- 2, Airbnb: Real-time Personalization using Embeddings for Search Ranking at Airbnb
- 3, Baidu: MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search
- 4, Google:Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations
- 5, [58 同城:向量化召回上的深度学习实践](https://www.6aiq.com/article/1618011600160)
- 6, [闲鱼搜索召回升级:向量召回&个性化召回](https://mp.weixin.qq.com/s/bXGWnXiIOYYFaXbghZNKUA)
- 7, 实际效果
- 四、 热度打压
- 五、Loss优化
- 六、网络结构优化
- 七、其他优化点
- 八、离线评估方式
- 实验效果
- 其他相关链接
一、什么是DSSM召回
DSSM又称双塔召回, 起源自微软的搜索算法文章,现在是推广搜算法最通用的向量召回算法之一。
作为深度学习算法之一, 它将将用户侧和物料侧特征组成的稀疏向量通过层层深度网络压缩到低维向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出代表用户和物料在高维空间语义相似度模型。
上线预测时利用训练完的用户向量ANN检索物料向量返回TopK近似物料。

二、为什么我们需要双塔召回
- 传统召回如协同过滤,swing需要多用户和物料共现,对低频用户覆盖度很低。
- 基于规则的召回大多基于用户的个别强特征,缺少其他各类强弱特征和他们的深度交叉。
使用DSSM深度召回模型基于用户物料特征分别进行深度交叉后返回物料, 并且因为是基于特征推理得到的向量,所以一般能覆盖度100%用户。
双塔召回虽然作为U2I向量召回早起典范, 年代比较久远,但是因为其模型简单通用,上线预测快速,所以有很多优化点,因此下面我们从样本,loss,网络结构等阐述它的诸多变种。
三、样本方面优化
石塔西大佬在著名的负样本为王:评Facebook的向量化召回算法 写到排序是特征的艺术而,召回是样本的艺术。
在漏斗形的推荐算法中, 排序大多数情况无疑正样本用真实曝光且互动(或时长点击), 负样本是真实曝光且无互动。 但是对于召回,如果负样本直接用真实曝光且无互动会造成下面两个问题。

- 真实曝光且无互动是经过召回和粗排,算是比较靠谱的样本,没有让召回模型开眼界
- 训练与预测分布不一致。 训练是排序排在比较前面的样本, 但是召回需要面临海量的物料库
DSSM 原文中的采样方法使用(Q,D+) 来表示一个(Query,Doc)对,其中 D+ 表示这个Doc是被点击过的。 使用D+和四个随机选取没有被点击过的Doc来近似全部文档集合D ,其中{D−(j) ;j=1,…,4}表示负样本
但是业界这个负样本,正样本到底怎么得出来的呢。 业界主要有两种做法, 一种是batch内负采样,一个batch全是用户-物料对正样本, 负样本由用户和batch内其他样本的物料构建。这种方式的好处是实现比较简单,而且效果也比较容易出, 之后说的第二种全局负采样很容易构建成easy negative sample模型难以学到有益信息。而batch内负采样将其他正样本物料作为自己负样本物料可视为hard negative sample。具体实现方式可以看这篇文章batch内负采样
第二种方法是全局负采样,负样本从全局物料库随机采样。因为线上召回时,候选库里大多数的物料是与用户无关的,随机抽样能够很好地模拟这一分布 。但是简单的随机采样并不能带来什么效果,只有增加 hard negative样本才能提高召回效果,接下去介绍业界几家公司是如何做困难样本负采样的。
1, Facebook: Embedding-based Retrieval in Facebook Search
这篇文章是facebook发表在KDD2020上的一篇关于社交网络中的搜索中的embedding 检索问题, 包括了特征、样本、模型、全链路等各种细节知识。
文中实验论证了使用曝光且无点击的负样本比随机抽样效果差很多,并提出了负采样的几种方式:
- Online hard negative sampling:在线一般是batch内其他用户的正例当作负例池随机采
样
- Offine hard negative sampling:在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。 在此基础上, 拿上一版召回模型排在第100到500位置的item作为负样本的hard sampling。因为前100可能是正例, 而500之后算easy sample了
- Hard positive sampling: 有一部分没有点击但通过分析日志也可以算为正样本
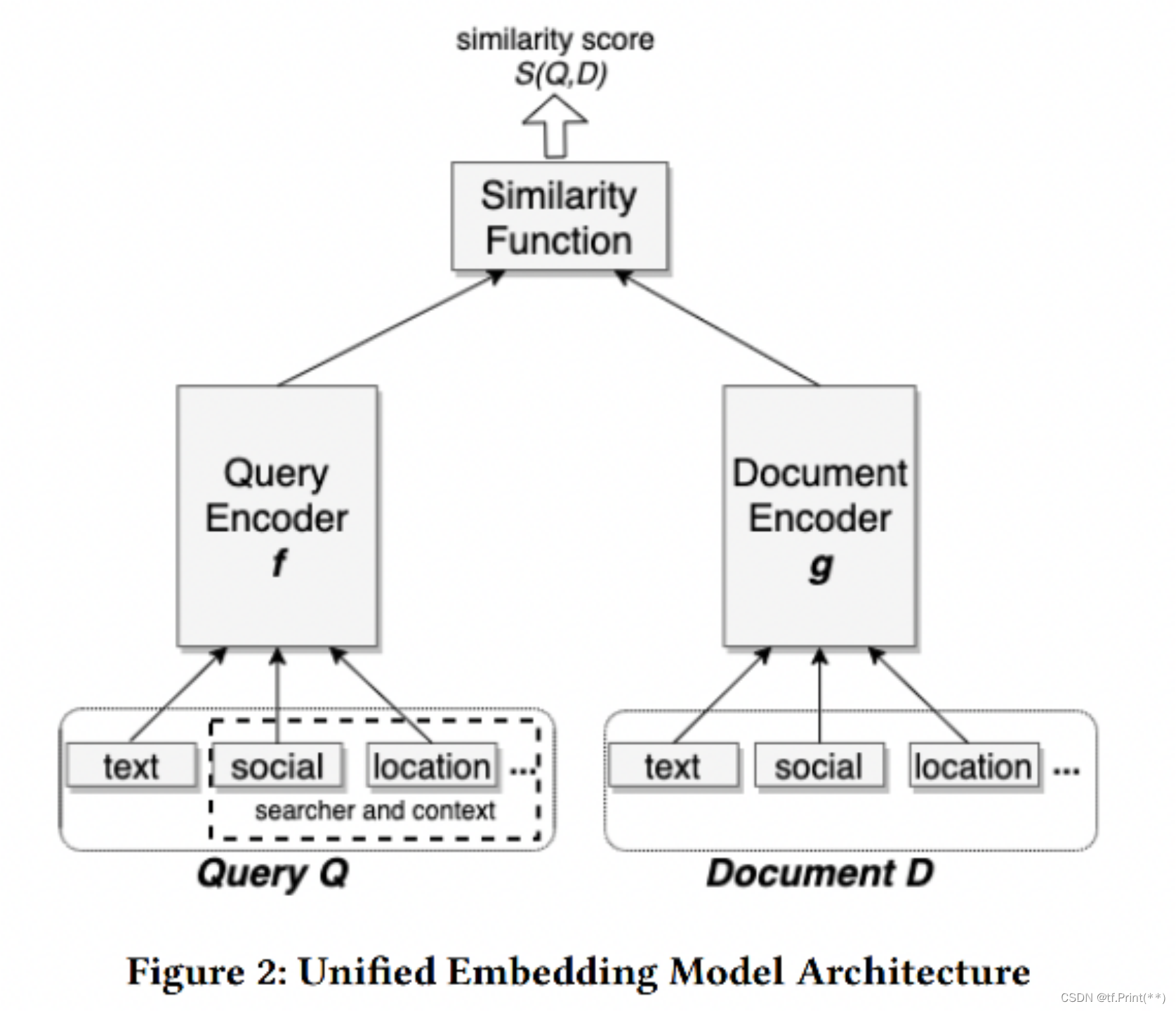
2, Airbnb: Real-time Personalization using Embeddings for Search Ranking at Airbnb
这篇文章是Airbnb关于搜索的session数据来生成房源和用户embedding并应用的文章,embedding学习过程将搜索session中数据看作类似序列信息,并通过类似word2vec的方式学习出每个房源id的embedding值。
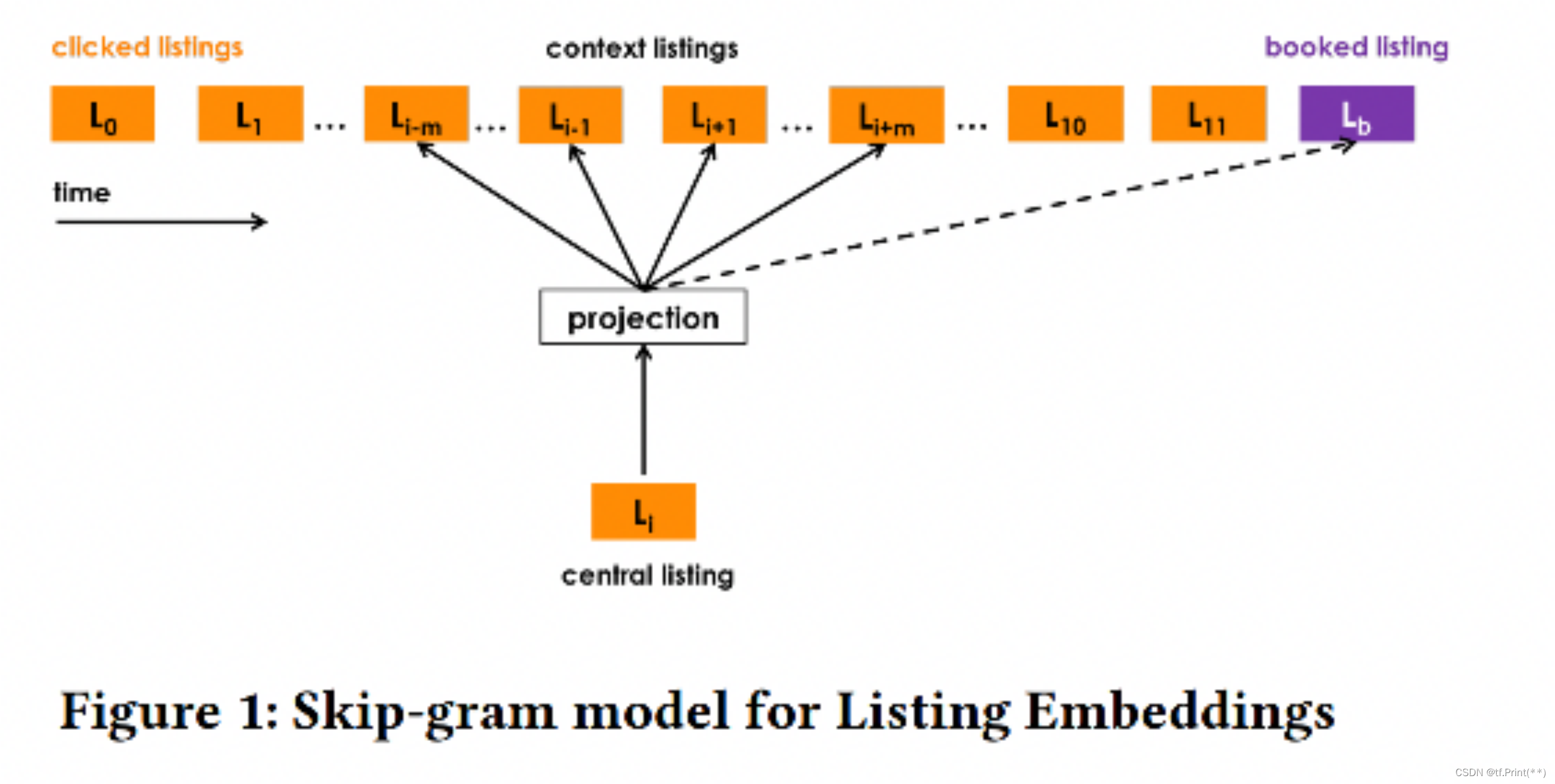
- 负样本也是从语料库(所有房源的集合中)随机选取一个房源作为负样本, 但不是完全随机的
- 增加“与正样本同城的房间”作为负样本,增强了正负样本在地域上的相似性
- 增加“被房主拒绝”作为负样本,由于房东可以拒绝消费者入住,因此,为了减少预定拒绝率,把房东的拒绝也考虑到负样本中, 这也增强了正负样本在“匹配用户兴趣爱好”上的相似性, 加大了模型的学习难度
3, Baidu: MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search
- 百度凤巢一篇广告推荐相关的论文,本文提出了一种新的架构来统一之前召回和rank分开的架构。
- 将召回和排序合并为一个系统,避免传统漏斗形推荐系统中召回和排序优化目标不一致,需要协同的问题
- 但是合并到一起后,面临长尾问题,模型容易预估出高ctr但相关性很差的结果
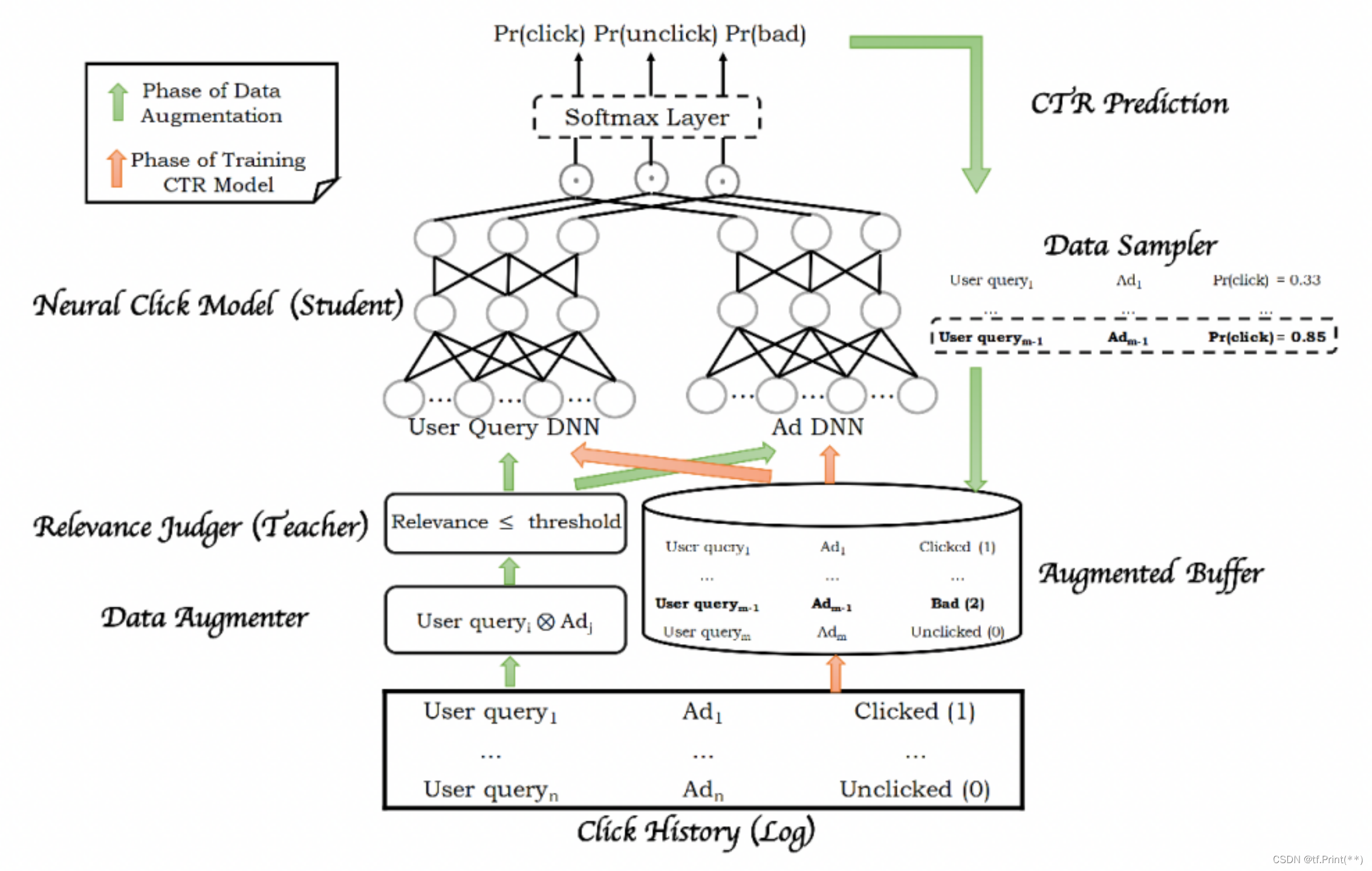
- 较早提出hard negative sampling的概念
- 用已经训练好的相关性模型对每一个生成数据对进行相关性预测,同时设定一个阈值,将小于阈值的数据对取出,送给点击模型预测CTR ,就得到了低相关性但是高ctr 作为hard negative sample
- 与Facebook那篇同理 取 100-500 位召回结果 异曲同工
4, Google:Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations
- 谷歌的文章提出了混合负采样Mix Negative Sampling方法(MNS)方法:batch内负采样+物料池中全局均匀采样。 batch内负采样贴合物品出现频率的采样,节省了计算资源但是存在偏差问题,负样本不包含长尾中item;因此引入了物料池中均匀采样,一方面解决冷启动问题,一方面引入全局分布避免batch size太小导致的分布剧变。
- 测试了不同的training batch size和 全局均匀负采样size 给出了一个不错的组合方式
5, 58 同城:向量化召回上的深度学习实践
- 文中提出可以从负样本中筛选同城帖子为困难负样本。
- 因此同样可以在负样本中筛选同兴趣标签的为困难负样本。
6, 闲鱼搜索召回升级:向量召回&个性化召回
文中提出构建负样本的多种方式:
- Baseline随机构造负样本:为增加随机性,该部分实现可在训练时使用同Batch中其他样本做负样本,同时也可以引入经典的Batch Level Hard Sample机制。
- 同父类目的邻居子类目负采样。
- 高曝光低点击类目样本:同一个Query搜索下,根据全局点击商品的类目分布,取相对超低频类目样本作为负样本。
- 充足曝光情况下,低于相应Query平均曝光点击率一定百分比的样本做负样本。
- 基于Query核心Term替换构造负样本:如,对于“品牌A+品类”结构的Query,使用“品牌B+品类”结构的Query做其负样本。
除了上述论文,还有不少优秀的文章阐述了召回负样本生成的工作
链接1: 推荐系统之—正负样本构造trick_Ricky-程序员宅基地_推荐系统负采样
链接2: 召回和粗排负样本构造问题
链接3: 召回模型中的负样本构造
链接4: 推荐系统正负样本的划分和采样,如何做更合理?
链接5: 推荐系统论文阅读(三十三)-百度:谈谈召回任务中负样本的选取优化
链接6: 召回负样本选取梳理
链接7: 双塔召回模型的前世今生(上篇)
链接8: 负样本为王:评Facebook的向量化召回算法
链接9: 借Youtube论文,谈谈双塔模型的八大精髓问题
7, 实际效果
我司在场景中实测batch内负采样较方法全局采样个性化效果提升明显。 因为后者很容易构建成easy negative sample模型难以学到有益信息。而前者将其他正样本物料作为自己负样本物料可视为hard negative sample。
四、 热度打压
1, 相关理论
热度打压同样是在处理召回正负样本的时候常规操作,在大多数推荐系统里少数热门物料占据了绝大多数的曝光与点击。 这样一来,正样本被少数热门物料所绑架,导致所有人的召回结果都集中于少数热门物料,完全失去了个性化。因此:
- 热门物料做正样本时, 需要降采样,减少对正样本集的绑架。
某物料成为正样本的概率为
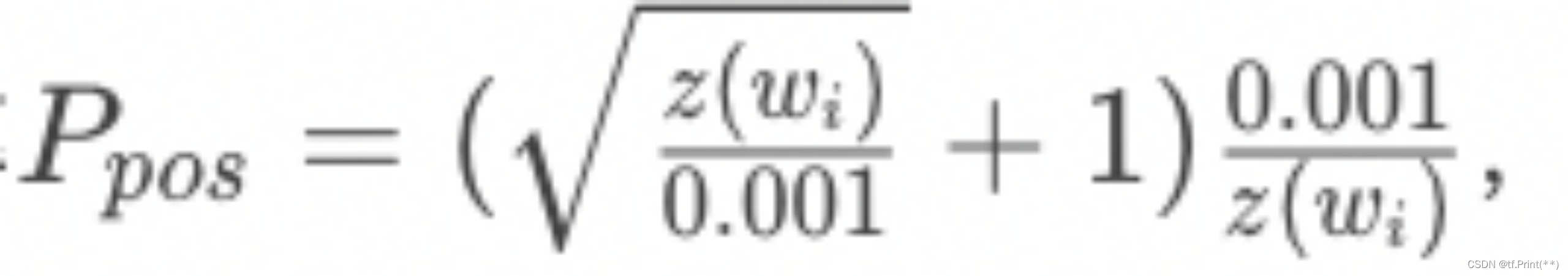
其中 z(w)是第i个物料的曝光或点击占比
- 热门物料做负样本时, 需要适当过采样, 抵销热门物料对正样本集的绑架;同时,也要保证冷门物料在负样本集中有出现的机会。
某物料成为负样本的概率
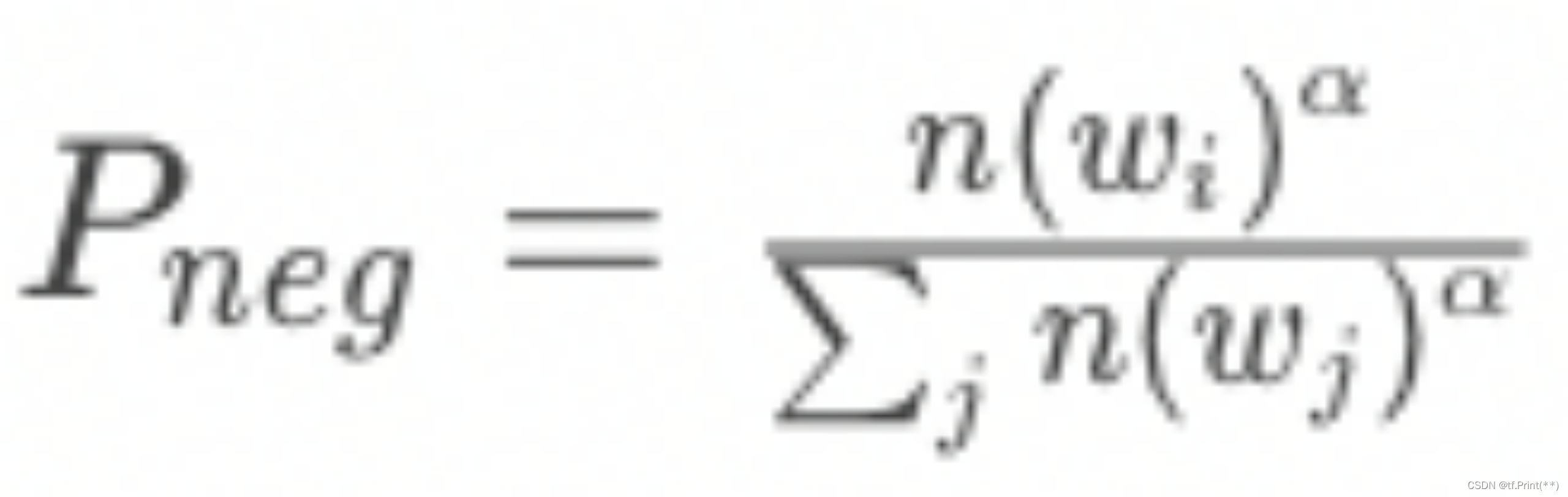
其中n(w)是第i个物料的出现次数,而 α一般取0.75。
之前提过的样本链接中也有对于热门打压相关的描述:
链接1: 负样本为王:评Facebook的向量化召回算法
链接2: 推荐系统论文阅读(三十三)-百度:谈谈召回任务中负样本的选取优化 。此文中对样本根据一定曝光频率来采集,本身也是热度打压的一种。
2, 实际效果
在我司场景中,实测不对正样本热度打压时, 召回返回基本时全是全站Topk高热物料,缺乏个性化。加入打压后,个性化明显。
五、Loss优化
首先, 有一篇我觉得非常好的文章 【辩难】DSSM 损失函数是 Pointwise Loss 吗?很清晰的阐述了DSSM loss的本质, 属于pairwise+ loss的一种。相比纯粹的pairwise loss, 它计算单个 loss 时会用到多个负样本。
1, pointwise loss
在我们的开发历程中, 因为排序的惯性思维并且追求快速上线,一开始使用pointwise loss的形式, 仅从单条用户-物料样本的分类角度来计算,没有考虑同一用户对不同物料的相对顺序。 比如我使用了评估binary cross entropy , 它评估了单个样本真实标签的预测准确度,总误差既包括正样本带来的误差,也包括负样本带来的误差。但是结果是效果很差, 召回基本没有个性化。
2, DSSM 原生loss
看了上面那篇文章后, 使用DSSM原生的pairwise+ loss, 使用batch内负采样,给每一个正样本用户-正样本物料配上4个负样本物料![]() 。 然后Softmax计算正样本概率
。 然后Softmax计算正样本概率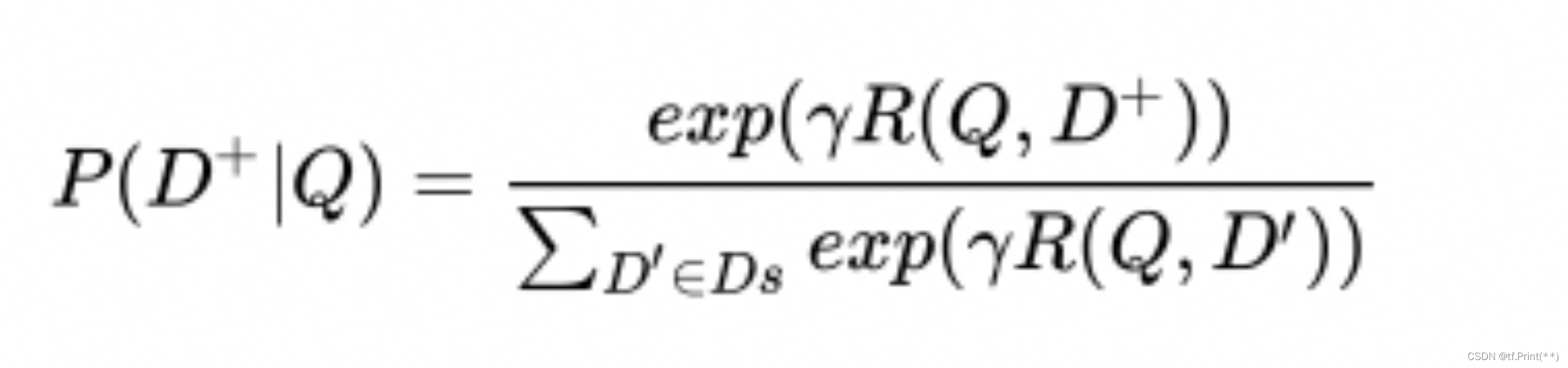
随后只基于正样本用极大似然估计得到 DSSM 的损失函数为: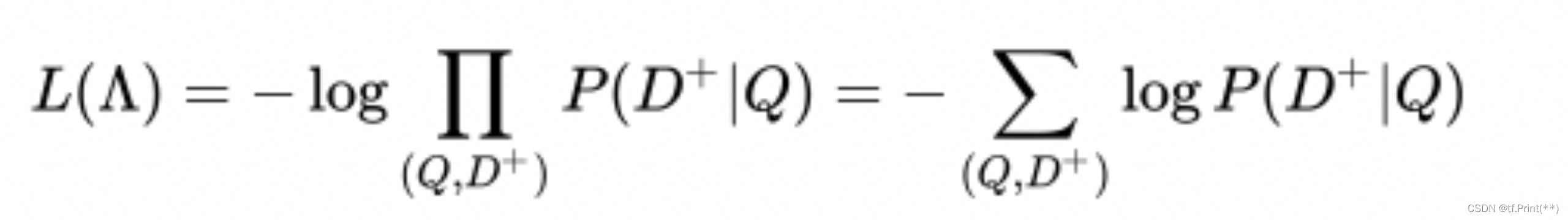
代码实验如这个链接 batch内负采样。 最终实验结果是远远优于binary cross entropy loss的
相关代码实现如下
user_emb,item_emb,neg_sampling = inputs
user_emb = tf.nn.l2_normalize(user_emb,-1)
item_emb = tf.nn.l2_normalize(item_emb,-1)
x = tf.keras.layers.dot([user_emb,item_emb],axes=-1)
NEG = 4
batchSize = 1024
item_y = item_emb
item_y_temp = item_emb
user_y = user_emb
#temperature = 0.1
for i in range(NEG):
rand = int((random.random() + i) * batchSize / NEG)
item_y = tf.concat([item_y,tf.slice(item_y_temp, [rand, 0], [batchSize - rand, -1]),tf.slice(item_y_temp, [0, 0], [rand, -1])], 0)
prod_raw = tf.reduce_sum(tf.multiply(tf.tile(user_y, [NEG + 1, 1]), item_y), 1, True)
prod = tf.transpose(tf.reshape(tf.transpose(prod_raw), [NEG + 1, batchSize]))
# prod = tf.transpose(tf.reshape(tf.transpose(prod_raw), [NEG + 1, batchSize])) / temperature
# 转化为softmax概率矩阵。
prob = tf.nn.softmax(prod)
# 只取第一列,即正样本列概率。
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
x = hit_prob
return x
model.compile(optimizer=opt.optimizer, loss="binary_crossentropy")
3, Infocse loss和Triplet loss
除了DSSM原生loss不少博客下面推荐 Infocse loss和Triplet loss这种纯pairwise loss,因为对于召回来说这种loss很适合尽可能拉近用户和正样本物料在高维空间的距离而拉远用户与负样本物料的距离, 而且他们关注困难负样本和困难负样本配合起来用会更好。
InfoNCE Loss

我个人理解下来就是DSSM原生loss加上一个温度系数, 会给和正样本相似度更高的负样本比较高的惩罚,我们 实验了多种温度系数没有明显的效果.
Triplet loss
Triplet loss可分为三类, easy triplets, hard triplets和semi-hard triplets
具体可以看链接中的原理知识

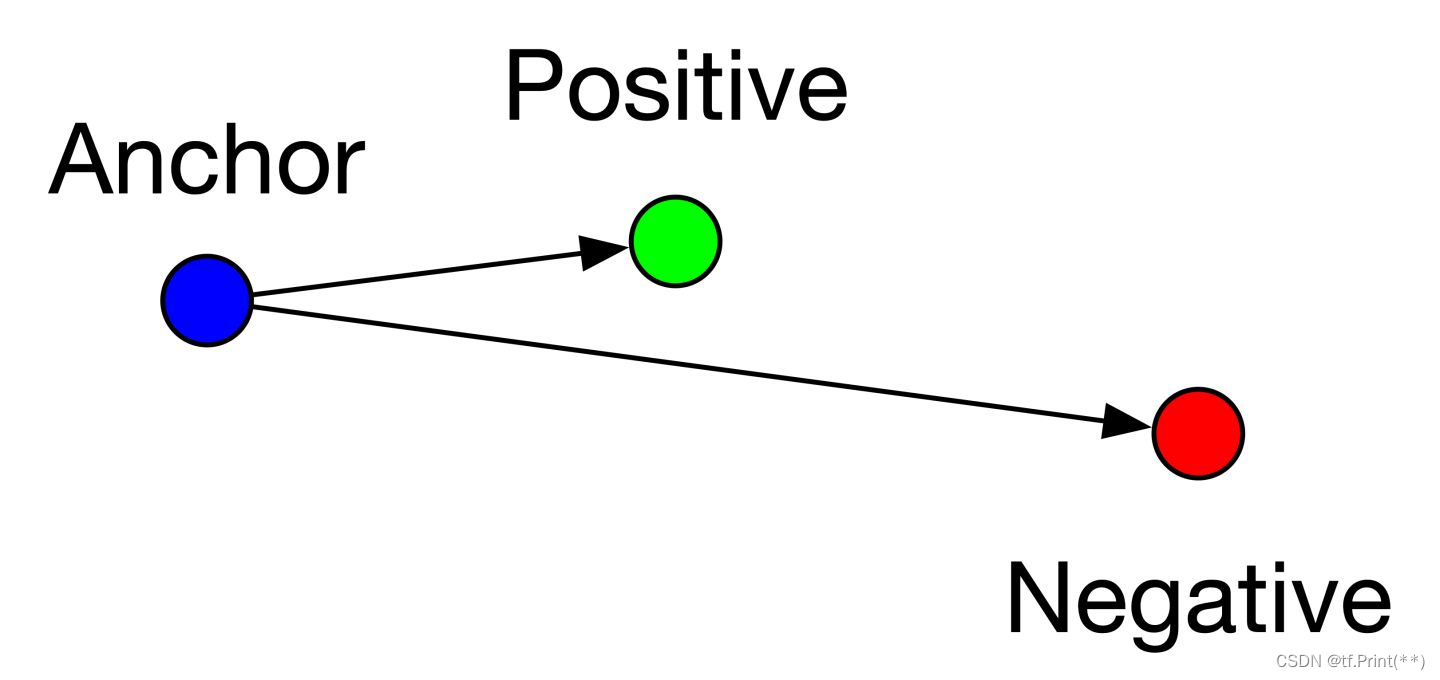
具体实验中, 这个loss中有margin需要设置,负样本越偏向困难负样本越需要设置大一点。具体实验中尝试了triplet loss, 指标提升了一些但是不是很明显,可能其中参数margin值需要调参。
闲鱼搜索召回升级:向量召回&个性化召回 提出了triplet loss和online hard negative mining匹配用,即在mini-batch内,每个正样本对之间互为负样本,选择其中最难的样本作为负样本(相似度打分最高的样本对)。
相关代码实现:
user_emb,item_emb,neg_sampling = inputs
user_emb = tf.nn.l2_normalize(user_emb,-1)
item_emb = tf.nn.l2_normalize(item_emb,-1)
NEG = 4
batchSize = 1024
item_y = item_emb
item_y_temp = item_emb
user_y = user_emb
# shape为[batchSize, emb_size]
for i in range(NEG):
rand = int((random.random() + i) * batchSize / NEG)
item_tmp = tf.concat([tf.slice(item_y_temp, [rand, 0], [batchSize - rand, -1]),tf.slice(item_y_temp, [0, 0], [rand, -1])], 0)
item_y = tf.concat([item_y,item_tmp], 1)
x = tf.concat([user_y, item_y],1)
return x
model.compile(optimizer=opt.optimizer, loss=triplet_loss)
def triplet_loss(y_true, y_pred):
emb_size = 32
alpha = 1.0
anchor, positive, negative1, negative2, negative3, negative4 = y_pred[:,:emb_size], y_pred[:,emb_size:2*emb_size], y_pred[:,2*emb_size:3*emb_size], y_pred[:,3*emb_size:4*emb_size], y_pred[:,4*emb_size:5*emb_size], y_pred[:,5*emb_size:]
positive_dist = tf.reduce_mean(tf.square(anchor - positive), axis=1)
negative_dist1 = tf.reduce_mean(tf.square(anchor - negative1), axis=1)
negative_dist2 = tf.reduce_mean(tf.square(anchor - negative2), axis=1)
negative_dist3 = tf.reduce_mean(tf.square(anchor - negative3), axis=1)
negative_dist4 = tf.reduce_mean(tf.square(anchor - negative4), axis=1)
negative_dist = tf.concat([negative_dist1, negative_dist2, negative_dist3, negative_dist4], 0)
positive_dist_final = tf.tile(positive_dist, [4, ])
return tf.maximum(positive_dist_final - negative_dist + alpha, 0.)
4, BPR loss
据说BPR loss效果比triplet loss好,而且它没有需要调参的地方。没有ma rain,鼓励用户和正样本物料相对和负样本物料距离拉的越远越好。可以之后尝试一下。

5, Weighted Hinge Loss
在模型化召回在陌陌社交推荐的应用和探索
中提到Weighted-Hinge-Loss,更适合ANN检索,可以一试。
其他相关链接:
链接1: 排序主要的三种损失函数(pointwise、pairwise、listwise)
链接2: 【推荐】pairwise、pointwise 、 listwise算法是什么?怎么理解?主要区别是什么?
六、网络结构优化
DSSM 是召回的经典模型虽然比较简单古老但正因为简单所以上线方便快捷,因此有很多改进空间。
1, SENet
其中第一个是张俊林老师提出的将SENet运用在 双塔模型, 具体可以参考文章SENet双塔模型:在推荐领域召回粗排的应用及其它

众所周知,DSSM双塔的优势就是用户侧和物料侧特征解藕,两个塔分别输出一个向量, 然后线上用Faiss这种工具做实时ANN检索, 对召回面向海量物料需要预测的情况下能够有毫秒级别反馈。
但是这种优点也是缺点, 用户特征和物料特征分别经过层层DNN压缩成低维向量,最后才在Cos层交叉, 相比排序模型或者FM召回 用户侧特征和物料侧特征在浅层网络就进行交叉相比显得为时已晚而且丢失了很多信息再交叉。
而SENet换了种思维解决这一问题, 对User侧和Item侧的特征,动态学习特征权重,强化那些重要特征,弱化甚至清除掉不重要的特征。 这样就算只在最后一层交叉, 也尽可能让重要信息进行交叉。
SENet原文里面,对每个特征embedding压缩是使用CNN的二维卷积核进行Max操作, 而张俊林老师的知乎里面是使用平均迟化。 而我这里是使用一个MLP网络把原来32维的向量映射8再到1,作为乘到原始向量上的权重值。
代码实现如下:
# SE-BLOCK
user_profile_emb_reshape = tf.reshape(user_profile_emb,(-1, user_feature_len, embedding_size), name='user_profile_emb_reshape') # (?,1152)->(?,36, 32)
item_profile_emb_reshape = tf.reshape(item_profile_emb,(-1, item_feature_len, embedding_size), name='item_profile_emb_reshape') # (?,2880)->(?,90, 32)
user_profile_emb_excitation = Dense(embedding_size//4, activation='sigmoid', use_bias=False, name='user_profile_emb_excitation_0')(user_profile_emb_reshape) # (?,36, 32) ->(?,36, 8)
item_profile_emb_excitation = Dense(embedding_size//4, activation='sigmoid', use_bias=False, name='item_profile_emb_excitation_0')(item_profile_emb_reshape) # (?,90, 32) ->(?,36, 8)
user_profile_emb_excitation = Dense(1, activation='sigmoid', use_bias=False, name='user_profile_emb_excitation_1')(user_profile_emb_excitation) # (?,36, 8) ->(?,36, 1)
item_profile_emb_excitation = Dense(1, activation='sigmoid', use_bias=False, name='item_profile_emb_excitation_1')(item_profile_emb_excitation) # (?,90, 8) ->(?,36, 1)
user_profile_emb_senet = multiply([user_profile_emb_reshape,user_profile_emb_excitation], name='user_profile_emb_senet') # (?,36, 32) ->(?,36, 32)
item_profile_emb_senet = multiply([item_profile_emb_reshape,item_profile_emb_excitation], name='item_profile_emb_senet') # (?,90, 32) ->(?,90, 32)
user_profile_emb_senet_final = tf.reshape(user_profile_emb_senet, (-1, user_feature_len*embedding_size), name='user_profile_emb_senet_final') # (?,36, 32) ->(?,1152)
item_profile_emb_senet_final = tf.reshape(item_profile_emb_senet, (-1, item_feature_len*embedding_size), name='item_profile_emb_senet_final') #(?,90, 32) ->(?,2880)
2, 多任务学习
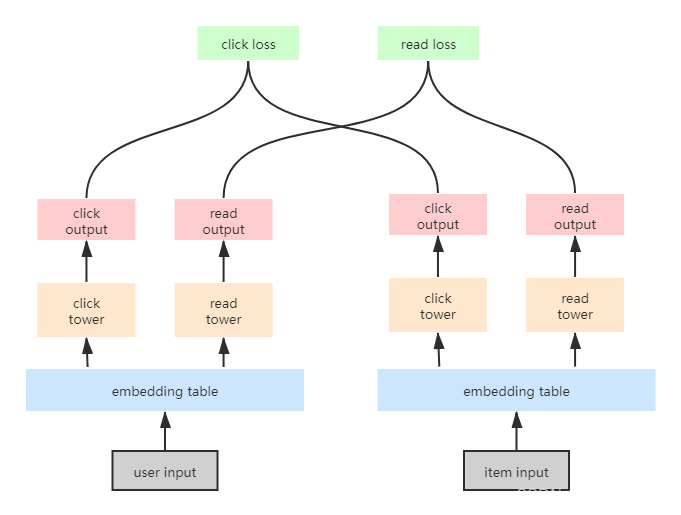
曾经做排序的时候做过一段时间多任务学习MMOE,PLE等, 多任务学习主要解决的任务第一是满足业务上的同时多个指标, 第二就是解决某个任务数据稀疏的问题,用一个辅助任务去帮助主要任务去训练(比如点击正样本比较多帮助互动正样本少的任务训练)
召回也有多任务学习, 在这边还没有具体尝试,先放上链接和图片。
QQ浏览器:小说召回中的DSSM模型优化实践 https://www.sohu.com/a/447529493_187948
3, Dynamic Weight & Debias
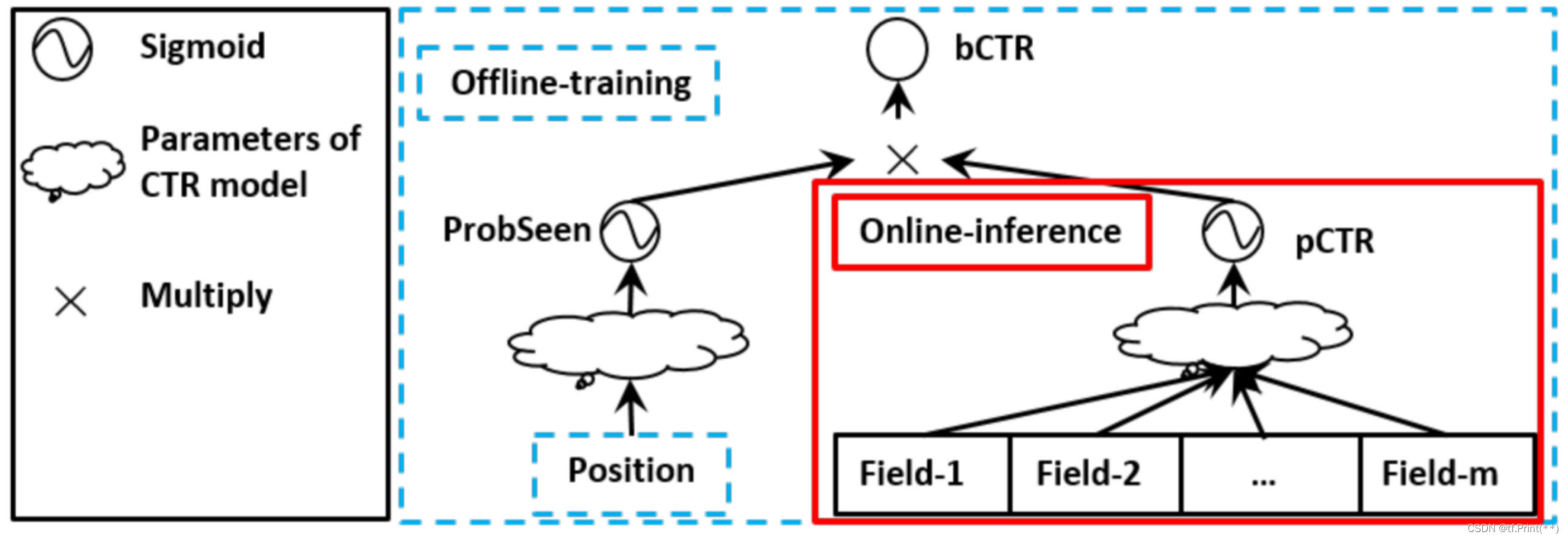
现实业务中有一些重要的特征,比如用户活跃度,物料出现在列表里的位置,可以像阿里position bias的想法一样, 把这些强特征单独经过一个网络(通过一个LR或一层fully connection)和和主DNN最后的输出再拼接起来。 在排序中是将这两部分的logits 加和在一起,召回双塔模型中我认为可以组成两部分向量后concentrate在一起。
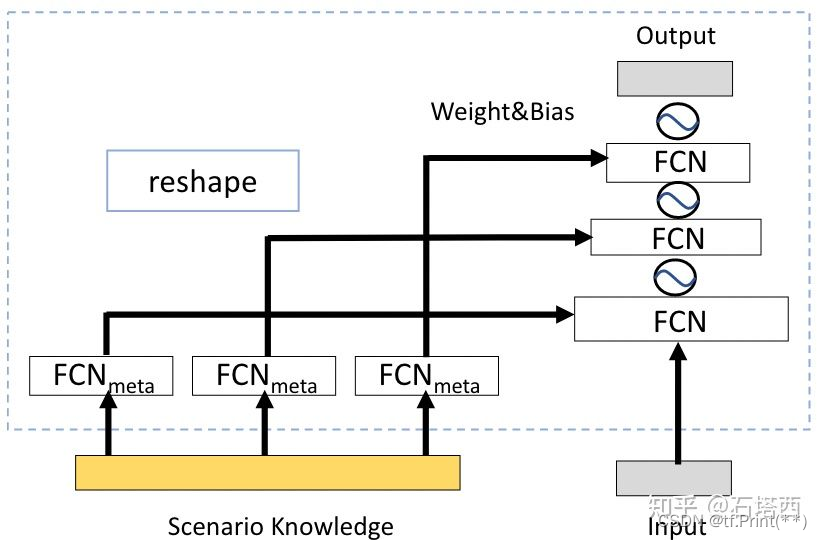
另一种更高级的做法,就是石塔西前辈提到的动态权重 动态权重:推荐算法的新范式
。 将强特征输出后的向量reshape成一个三层网络Dynamic Weighted Network(DWN)后拼接在双塔DNN上,这种方式我觉得对于DSSM更合适,值得一试。
相关链接:
链接1: 动态权重:推荐算法的新范式
链接2: 初来乍到:帮助新用户冷启的算法技巧
链接3: 推荐系统中的debias算法
4, 对比学习
对比学习是这几年比较火热的点, 也可以运用在双塔上。 但是这其中的难点在于辅助任务构建data augumentation上。具体可以看石塔西和张俊林两位前辈的文章。目前还没来得及在业务上尝试。
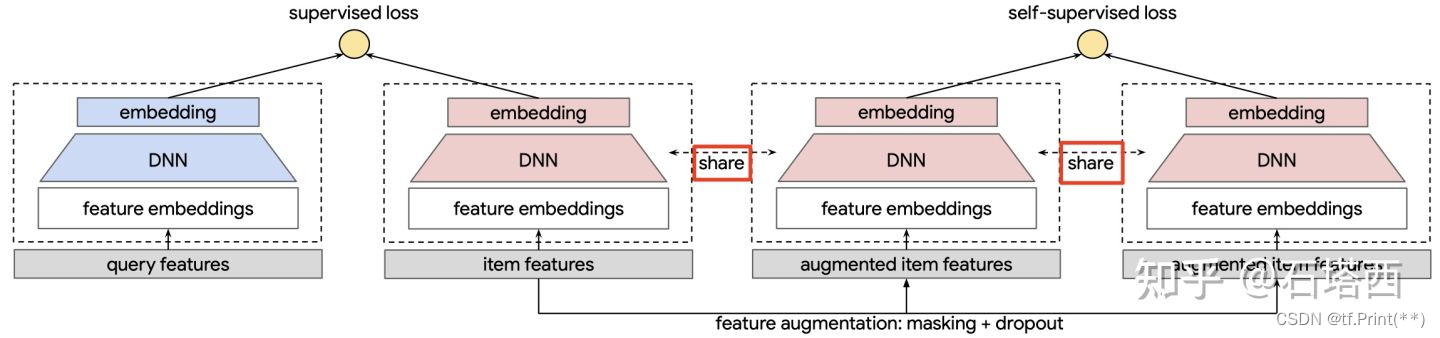
链接2: 少数派报告:谈推荐场景下的对比学习
七、其他优化点
其他优化方式还有很多就不一一展开了,其中特征常规操作可以加上用户序列类特征,博主/up主id特征, 用户id,物料id。
另外就是改变label是影响线上效果最直接的方式,比如你的目标是提升DAU,UV,可以尝试互动, 点击,时长的各种组合。而且, 对label设定进行reweight其实也是改变训练样本分布的一种, 这里有很多文章可以参考。这里给出蘑菇街的一篇文章蘑菇街首页推荐多目标优化之reweight实践:一把双刃剑?
八、离线评估方式
评估的方式最好的肯定是ab线上评估,不过受制于流量有限或者其他因素,线上评估是比较慢的。
排序的离线评估无疑首选是AUC,但是对于召回来说不一定, 实际上好的召回可能auc低一些,但是会召回出更符合真实分布的内容,实际工作中auc当作参考就好。
最适合的还是模拟召回这一过程, 拿Faiss召回后的TopK结果与用户实际点击做交集并计算precision/recall, 我在实际运用中计算得到召回率和命中率,其中召回率是有多少用户点击物料实际被TopK召回了, 比如用户日志里点击了5条物料,有3条出现在Faiss召回TopK中那么召回率便为0.6。 另外, 假如5条全中那么命中率就为1。 最后求所有用户平均值。
当然对于召回来说还有用肉眼去观察效果。
链接1: 召回模型中的负样本构造
链接2: 「召回层」如何评估召回效果?
实验效果
其他相关链接
1, 推荐粗排(召回)工程实践之双塔DNN模型
https://mp.weixin.qq.com/s/w-J_hz1Qf3Y-Kc8ywx9kUg
2, 干货篇 | 58 同城:向量化召回上的深度学习实践
https://www.6aiq.com/article/1618011600160
负采样筛选同城的帖子为负样本, 同样可以筛选同兴趣标签的为负样本。
用户点击标签的标签embedding lookup table和 标签embedding lookup table可以share,但应该实验可能不在一个空间
3, 小米收音机如何提高内容分发效率?DSSM召回模型做到了!
https://mp.weixin.qq.com/s/bDIrbA7GmLxgPFYzA1uijg
4, 【推荐系统】DSSM双塔召回
https://blog.csdn.net/weixin_31866177/article/details/115941316
序列特征attention
5, 借Youtube论文,谈谈双塔模型的八大精髓问题
https://zhuanlan.zhihu.com/p/369152684
6, 双塔召回模型的前世今生(上篇)
https://zhuanlan.zhihu.com/p/430503952
7,双塔召回模型的前世今生(下篇)
https://zhuanlan.zhihu.com/p/441597009
8,模型化召回在陌陌社交推荐的应用和探索
https://mp.weixin.qq.com/s/tZOcfz9u3c_Z8SU1EhTDUg
weighted-hinge-loss
9, QQ音乐推荐召回算法的探索与实践
https://mp.weixin.qq.com/s/I2ZOsh63-ApXDgK5hbQ1yQ
10, 闲鱼搜索召回升级:向量召回&个性化召回
https://mp.weixin.qq.com/s/bXGWnXiIOYYFaXbghZNKUA














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









