







原文链接:https://arxiv.org/pdf/2108.09640.pdf
Abstract
TNT的方法是需要预先输入大概的target的,而DenseTNT不需要,是完全anchor free的方法。
Introduction

左图的以前的做法是根据lane定义一些anchor再regress和classify获得最终的位置,之后还要通过NMS的筛选法选出最后的轨迹。右侧的为现在的方法,通过密集地采点避免了定义anchor,同时也避免了使用NMS等规则来筛选。
意图测中非常重要的一个问题是ground truth只有一个,而对于多意图的预测来说,多个方向的预测都是允许的,这导致了label中有很多都是无效的,因为gt只包含了一个意图下的结果。此处设计了一个offline的model来提供多个意图下的label。这个model使用了一个优化算法从goal的分布里取出了一个set作为online model的label。
Method
地图采用vector化后的encode的结果。然后用dense goal encoder生成这些goal的概率分布。用这些概率分布获得一个goal set。在训练过程中使用优化算法制造伪的label。
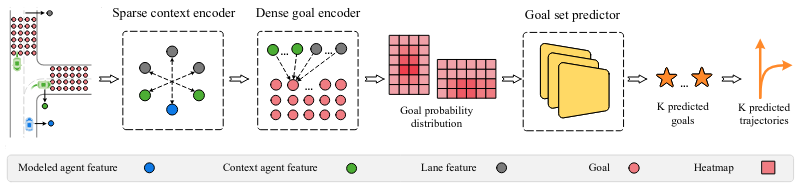
Sparse context encoding
本文使用VectorNet来提取地图的feature。(没有的高精地图的话也可使用CNN)。输出为2D矩阵 L L L,每个row表示地图上的元素(lane,agent)的feature。
Dense goal probability estimation
TNT对于一个goal只预测一条轨迹的概率是有问题的:一个goal只有一条预测(可能通向这个goal的别的预测概率很高),一个goal获取的feature不够丰富(goal附近的点的信息也用上会更好)。
我们使用了dense goal encoder。它以一定的采样频率获取了地图上在道路上的的所有点。然后预测了这些密集点的概率分布。
Lane scoring
为了减少需要sample的点,我们先预测goal落在不同lane上的概率,这样能过滤掉明显不在candidate lane附近的点,提升运算速度。
这是一个二分类问题。因此使用了二分类的交叉熵计算loss。对于label,使用离gt的goal最近的lane作为1,别的lane为0.对于别的lane
l
l
l,假设gt的goal是
y
g
t
y_{gt}
ygt,定义一个distance
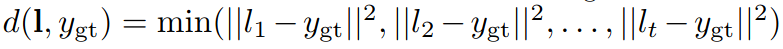
直觉上就是gt的goal到这条lane的最短距离的平方。
Probability estimation
获得概率分布的做法是self-attention。首先agent的feature经过两次MLP。然后把goal的feature
F
F
F作为需要query的的变量,从地图上所有元素(lane,agent)的feature中去查找索引对应的键和值。目的就是建立goal的feature与地图上所有元素的联系。直观上,这一步是把agent的未来状态(goal)表示成由历史的信息作为变量的函数,这个函数采用的是self-attention的做法。
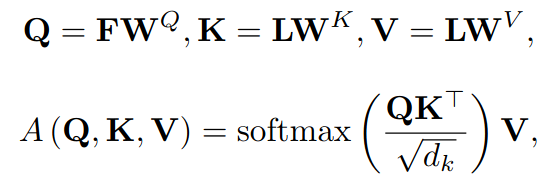
这一步之后的结果是goal新的feature F F F。再通过两次MLP,即下图中的 g ( . ) g(.) g(.).用softmax中的方法获得每个goal的概率。将所有goal在地图上表示出来的话就是一个概率分布heatmap。
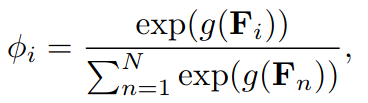
对于Loss的计算,离gt的goal最近的goal的label定为1,其余都为0.采取二分类交叉熵的算法。
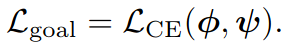
Goal set prediction
对于多意图的预测,像TNT等预先设定好target的做法采用而是NMS(靠的近或概率低的过滤掉)。而DenseTNT的上一步获得是heatmap,因此不能简单使用NMS,因为用于筛选的阈值比较难定。这是因为TNT中采用的是从高到低排序概率,而DenseTNT中的概率分布是针对于整个鸟瞰图的,一旦意图的可能性变多了,平均分布到每一个意图的概率就低了(对于概率分布,所有的点的概率加起来需要为1)。
 因此,我们再加一个预测的任务。它的输入是heatmap,输出是goal set,这个有点像目标检测的框生成。但和目标检测不同,对于一个输入,我们的label只有一个,即gt。这样的话可能会有别的意图的结果在训练中被忽略。为此,设计了一个offline model来制造这些label。它和online model的区别就在这一步中。没有使用goal set predictor而是采用了优化算法。
因此,我们再加一个预测的任务。它的输入是heatmap,输出是goal set,这个有点像目标检测的框生成。但和目标检测不同,对于一个输入,我们的label只有一个,即gt。这样的话可能会有别的意图的结果在训练中被忽略。为此,设计了一个offline model来制造这些label。它和online model的区别就在这一步中。没有使用goal set predictor而是采用了优化算法。

Optimization (offline)
上一步heatmap的输出,实际上是对于地图上众多goal每个点的一个函数。设定
C
=
{
c
1
,
c
2
,
.
.
.
,
c
m
}
C=\{c_1,c_2,...,c_m\}
C={c1,c2,...,cm}为所有dense goal的candidate,heatmap就把
C
C
C映射到一个0到1的的集合,写成
h
(
c
i
)
h(c_i)
h(ci),这也是每个goal的概率。
接下来定义一个目标函数
E
[
d
(
y
^
,
Y
)
]
=
∑
i
=
1
m
h
(
c
i
)
d
(
y
^
,
c
i
)
E[d(\hat{y},Y)]=\sum_{i=1}^m h(c_i)d(\hat{y},c_i)
E[d(y^,Y)]=i=1∑mh(ci)d(y^,ci)
其中
d
(
y
^
,
c
i
)
=
min
y
j
∈
y
^
∣
∣
y
j
−
y
c
i
∣
∣
d(\hat{y},c_i)=\min_{y_j\in\hat{y}}||y_j-y_{c_i}||
d(y^,ci)=yj∈y^min∣∣yj−yci∣∣
从直观上讲,目标是有M个goal(大池子),要从中选取K个靠谱的goal(小池子)。
d
d
d是针对于大池子的,对于大池子里所有candidate都有一个
d
d
d。这每个candidate都与小池子中的goal计算距离,取最近的作为
d
d
d,即寻找小池子中离candidate最近的点。对于所有的
d
d
d,用概率加权计算期望。总体的话在收敛情况,大池子中的所有goal到距离自己最近的小池子中的goal乘上概率加权应当达到最小。以下是这个优化算法的实现。

翻译成中文:
- 初始化K个goal,从M个goal的大池子里随机选
- 小池子里的每个goal做随机扰动,变为别的goal
- 计算原来的和现在的小池子的d的期望e和e’
- 如果现在的小池子d的期望更小,则使用现在的小池子。否则以1%的概率采用现在的小池子。(避免局部最优)
- 不停循环2-4直到步数达到阈值(或时间太长)
优化算法之后得到的就是全局最优的选中的小池子。这个小池子里的结果能作为训练online模型的伪label。
Goal set predictor (online)
模型采用了encode+decode的办法。encoder部分是一层self-attention加上max pooling,decoder部分是2层MLP,输入是heatmap,输出是2K+1个值,分别对应K个2维坐标(goal set)和一个当前goal set的confidence。
考虑到heatmap的概率分布比较散,可以采用N头同时运算。即N个goal set predictor输出N个2K+1的值,从当中选取confidence最高的那个goal set预测。为了运算效率的提升,这N头使用相同的self-attention层,但是不同的2个MLP。
在训练过程中,采用了offline模型的伪label作为监督。上述offline中讲到的初始选定的小池子,在这里采用的是online模型的K个goal的set的预测。然后经过L次随机扰动(即不停随机选取邻居点,L=100),选取当中expected error(offline里的期望项)最小的那个set作为伪label。
标记
y
˙
\dot{y}
y˙为预测结果,
y
^
\hat{y}
y^为伪label,则loss的计算如下。即一一对应后的L1距离之和。
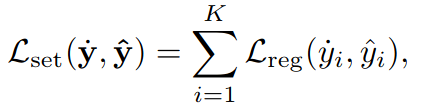
再考虑到采用了N头预测,这部分的loss将采用二分类的交叉熵。其中
μ
\mu
μ为所有head的confidence,
ν
\nu
ν为label,只有expected error最低的label为1,别的为0.
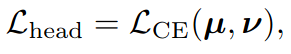
Trajectory completion
这一步和TNT做法类似。类似于dense goal encoding(2层MLP后过self-attention)最后过2层MLP来decode得到整条预测轨迹的state。采用teacher forcing技巧(因为只有一条gt)训练时只用gt的goal来算这条预测轨迹。Loss的算法和TNT一样,用的是点点之间的Huber loss。
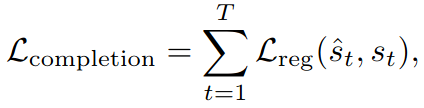
Learning
训练分为两个stage。第一个stage使用gt轨迹训练除了goal set predictor的部分。即把dense的goal输入。获得大量的轨迹。
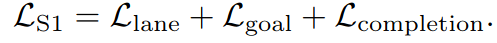
第二个stage主要负责goal set predictor的部分。
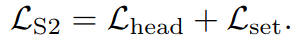















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









