






 该博客介绍了如何利用Python的Pandas库中的read_html函数方便快捷地从网页中抓取表格数据。通过指定url和设置header参数,可以将网页表格直接转换为DataFrame,并将第一行作为列名。适用于需要定期更新网站数据的情况。
该博客介绍了如何利用Python的Pandas库中的read_html函数方便快捷地从网页中抓取表格数据。通过指定url和设置header参数,可以将网页表格直接转换为DataFrame,并将第一行作为列名。适用于需要定期更新网站数据的情况。
想要每天获取网站表格的数据又懒得每天复制做表统计
使用pandas 的 read_html(),简单好用。
可以应用的场景为数据为表格,打开网站,使用开发者工具,点开element,然后搜索表格里的一个名词,就可找到表格数据所在位置。会有一个明显的table,数据格式非常整齐。
记录一下read_html()的参数,
1.io,io=url就可以了
2.header,header可以是int,也可以是list,header默认是等于None的,读取出来的table的columns name就是0,1,2,3这样的。
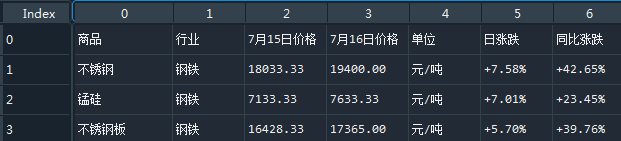
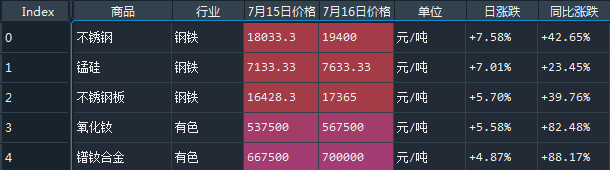
想使用第一行作为columns name,header=0,
df = pd.read_html(io=url,header=0)效果:
reference:https://www.cnblogs.com/litufu/articles/8721207.html

















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









