







论文名:Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition
中文名:脉冲卷积神经网络做高效的目标识别
摘要
深度神经网络(如CNN)已经在处理复杂的视觉问题(如目标识别)上展示了巨大的潜力。基于SNN的结构展示了使用基于脉冲的神经形态硬件实现低功耗的巨大潜力,这项工作描述了一种将CNN转换为SNN的新方法——可以将CNN映射到基于脉冲的硬件结构上,我们的方法首先裁剪了CNN结构以试它满足SNN的需求,然后以训练未裁剪之前的CNN结构的方法对裁剪后的网络进行训练,最后将学习到的网络权重直接应用到有裁剪后的CNN推出来的SNN结构上。我们在公开可用的DARPA(Defense Advanced Research Projects Agency)Neovision2 Tower 和 CIFAR-10 数据集上做了测试,展现出了和原始CNN结构类似的目标识别精度。我们的SNN实现可以直接映射到基于脉冲的神经形态硬件上,比如正在开发的DARPA SyNAPSE Program。我们的硬件映射分析表明基于脉冲的SNN硬件实现能效要比传统的基于FPGA的CNN实现高两个数量级。
1. Introduction
本篇论文按照如下方式组织,Sect. 2首先在2.1节由CNN结构的概述引出了我们的方法,然后2.2节讨论了目前基于发射率的CNN转换为基于脉冲实现的问题和挑战,紧跟着通过我们提出的方法克服了这些挑战(2.3节);Sect. 3描述了将SNN应用在Neovision2和CIFAR-10数据集上的实验结果;Sect. 4描述了将SNN映射到基于脉冲的硬件后的能效分析;Sect. 5和6描述了发现和结论。
2. Method
2.1 传统的CNN结构
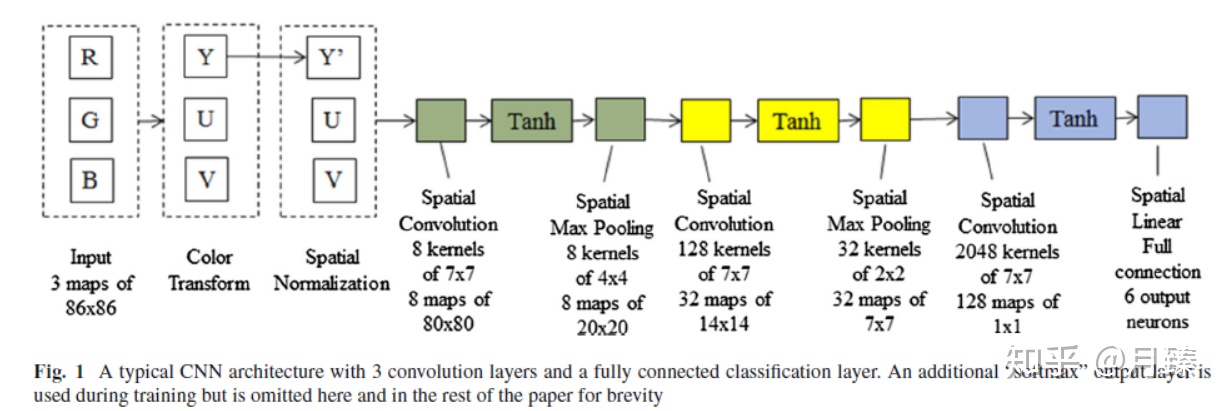
CNN的网络结构如上图所示,由三个卷积块组成,每一块又包括三个层,第一个层是由一系列卷积核组成的空间卷积层,第二个层一般是tanh(),第三个层是最大池化层;需要注意的是,最后一个块的最后一层没有使用池化层,而是选择了一个全连接层。整个网络使用标准的反向传播算法训练,训练CNN的目标就是调整系统参数。
2.2 实现脉冲型CNN的挑战
对于Sect. 1节提出的结构,我们希望将已有的CNN结构设计转换为SNN,最终映射为低功耗的神经形态硬件。将CNN转换为SNN有两种方法,第一种就是直接训练类似CNN结构的SNN,尽管存在一些像STDP的脉冲学习规则以一种自组织、无监督的方式训练SNN,在这方面的研究目前还处于起步阶段,并且还不清楚如何高效训练SNN来实现更高层次的功能;第二个方法就是训练原始的CNN,然后将学习到的权重应用到和训练的CNN结构类似的SNN中。主要的挑战就是在将CNN转换为SNN时分类任务有不可接受的精度损失。事实上,我们观察到转换Fig. 1所示的CNN结构时有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6169
6169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









