







论文名称:Spatial As Deep: Spatial CNN for Traffic Scene Understanding
论文下载地址:https://arxiv.org/abs/1712.06080
GitHub代码地址: https://github.com/XingangPan/SCNN
0 前言
空间卷积神经网络(SCNN)是香港中文大学联合商 汤科技集团有限公司在2017年发表在AAAI2018上的论文《Spatial As Deep: Spatial CNN for Traffic Scene Understanding》中提出的。空间CNN主要是用来处理自动驾驶领域中感知任务中的车道线检测任务。论文实现的代码主要是从resnet修改而来。所以需要对resnet有基本的认识。SCNN可以在同一层CNN的神经元之间实现显式有效的空间信息传播。它在物体具有强形状先验的情况下非常有效,比如车道线的长而细的连续属性。SCNN有很强的的鲁棒性。在正常的、拥挤的、晚上、没有车道线、有影子、箭头、炫光、曲线和十字路场景下都对车道线实现了很高的识别正确度。
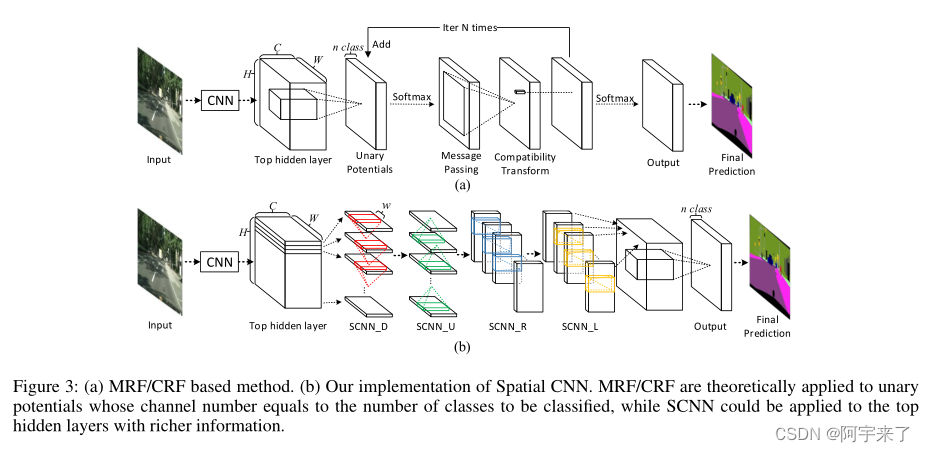
原论文表3展示了传统CNN和SCNN的区别:
其中(a)是传统的模型、(b)是SCNN模型
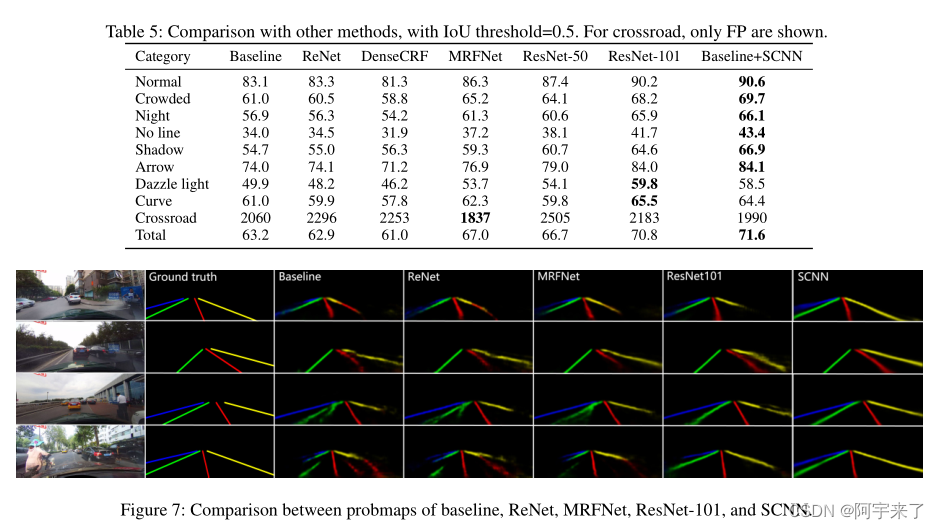
各种场景下的各种车道线检测模型的检测对比:
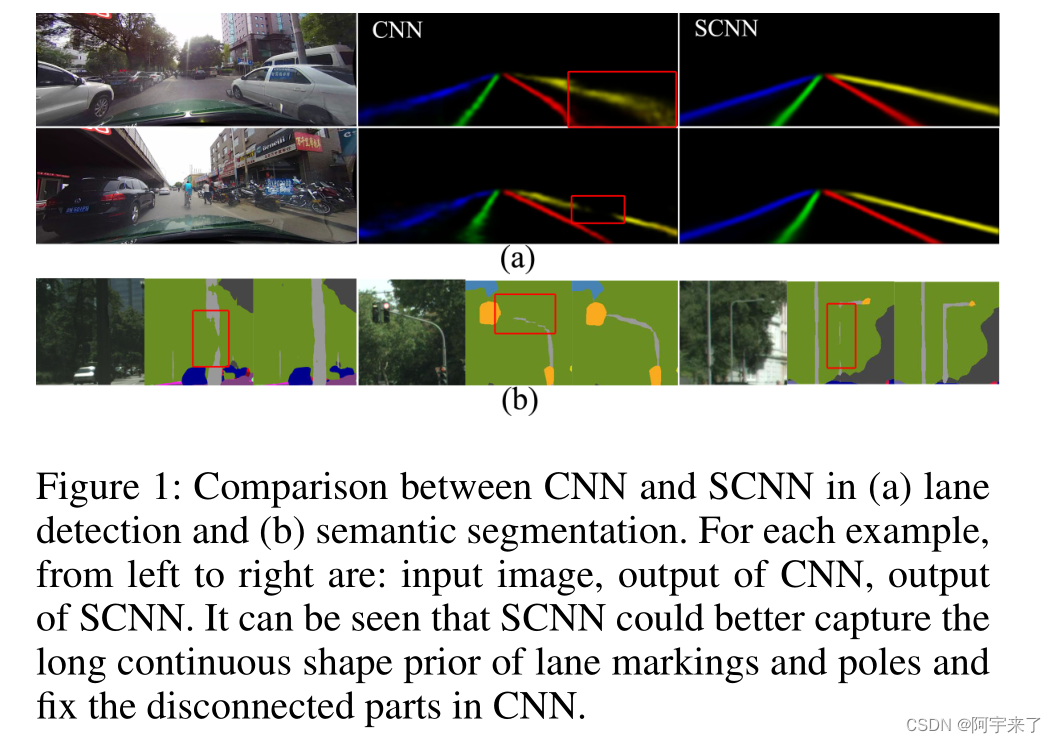
1 问题驱动
近年来,自动驾驶在学术界和工业界都受到了很大的关注。自动驾驶最具挑战性的任务之一是交通场景理解,其中包括车道检测和语义分割等计算机视觉任务。1.车道检测有助于引导车辆,并可用于驾驶辅助系统 (Urmson et al. 2008) .2.而语义分割提供了有关车辆或行人等周围物体的更详细的位置。
问题1:在实际应用中,考虑到许多严酷的场景,包括恶劣的天气条件、昏暗或眩光等,这些任务可能非常具有挑战性。现有的传统的CNN网络不能很好地处理这些极端的场景,而且对于图像中遮蔽的强形状先验但弱外观内聚的语义对象的检测精确度不高。比如遮蔽的车道线、电杆等。他们都是典型的强形状先验但弱外观内聚(其形状有着很强大的先验知识,我们有很强的的先验假设其形状,但是他的颜色、纹理等没有很强的内聚性)。对于人眼和大脑而言,根据图像中的对象的先验知识以及上下文信息很容易辨别出这些对象,但现有的算法还没有达到工业认可标准。
问题2交通场景理解的另一个挑战是,对于上下坡时的车道线检测场景检测结果表现不佳。
解决方案:
为了解决上面的问题1,该论文提出了 空 间 CNN(Spatial CNN ,SCNN) ,这是一种深度卷积神经网络到丰富空间层次的推广。在逐层 CNN 中,卷积层接收前一层的输入,应用卷积运算和非线性激活,并将结果发送给下一层。这个过程是按顺序完成的。同样, SCNN 将特征图的行或列视为层,依次进行卷积、非线性激活和和操作,形成深度神经网络。通过这种方式,信息可以在同层的神经元之间传播。它对于结构化对象特别有用,如车道、极点或有遮挡的卡车,因为空间信息可以通过层间传播来加强。在 对象不连续或混乱的情况下,SCNN 可以很好地保持车道线和线杆的光滑和连续性。
2 相关工作
对于车道道检测,现有的大多数算法都是基于手工构造的底层特征 (Aly 2008;Son et al. 2015;Jung 、Youn 和 Sull 2016) ,限制了应对恶劣条件的能力。只有 Huval 等人 (2015) 首次尝试在车道检测中采用深度学习,但没有一个大型和通用的数据集。而在语义分割方面,基于 CNN 的方法已经成为主流并取得了巨大的成功 (Long,Shel- hamer, and Darrell 2015;Chen et al. 2017) 。
还有一些其他的尝试在神经网络中利用空间信息。 Visin等 (2015) 和 Bell 等 (2016) 使用循环神经网络沿着每一行或每列传递信息,因此在一个 RNN 层中,每个像素位置只能接收来自同一行或同列的信息。 Liang 等人 (2016a;2016b)提出了 LSTM 的变体来利用语义对象解析中的上下文信息,但这种模型的计算成本很高。研究人员还尝试将 CNN 与MRF 或 CRF 等图形模型相结合,其中消息传递通过与大核的卷积实现 (Liu et al. 2015;Tompson et al. 2014;Chu et al.2016) 。与上述方法相比, SCNN 具有以下 3 个优点 :
(1) 与传统的密集 MRF/CRF 相比, SCNN 采用顺序消息传递的方式大大提高了计算效率 ;(应对传统的模型)
(2) 以残差的形式传递消息 ,使SCNN 易于训练 。(应对LSTM 的变体模型)
OS:就是了解前人工作的思维方式和问题处理方案,找出其研究不能解决的问题,引出本论文问题的解决方案。
3 本文贡献(创新点)
3.1 Lane Detection Dataset(车道线检测数据集)
In this paper, we present a large scale challenging dataset for traffic lane detection. Besides, none of these datasets annotates the lane markings that are occluded or are unseen because of abrasion,while such lane marking scan be inferred by human and is of high value in real applications.
在该文中,提出了一个用于交通车道检测的大规模具有挑战性的数据集。当前数据集要么数据量太小,要么场景单一,流量小的路段,都是容易出现模型欠拟合,路段封闭的场景。
Fig. 2 (a) shows some examples, which comprises urban, rural, and highway scenes. As one of the largest and most crowded cities in the world, Beijing provides many challenging traffic scenarios for lane detection.
图 2 (a) 显示了一些例子,其中包括城市、农村和高速公路场景。北京作为世界上最大、最拥挤的城市之一,为车道检测提供了许多具有挑战性的交通场景。

For each frame, we manually annotate the traffic lanes
with cubic splines. As mentioned earlier, in many cases lane
markings are occluded by vehicles or are unseen. In real ap-
plications it is important that lane detection algorithms could
estimate lane positions from the context even in these chal-
lenging scenarios that occur frequently. Therefore, for these
cases we still annotate the lanes according to the context, as
shown in Fig. 2 (a) (2)(4). We also hope that our algorithm
could distinguish barriers on the road, like the one in Fig. 2
(a) (1). Thus the lanes on the other side of the barrier are not
annotated. In this paper we focus our attention on the detec-
tion of four lane markings, which are paid most attention to
in real applications. Other lane markings are not annotated.
对于每一帧,我们用三次样条手工标注了交通车道。如前所述,在很多情况下,车道标记会被车辆遮挡或看不见。在实际应用中,重要的是车道检测算法可以从上下文中估计车道位置,即使在这些经常发生的具有挑战性的场景中。因此,对于这些情况,我们仍然根据上下文注释车道线,如图 2 (a)(2)(4) 所示。我们也希望我们的算法能够区分道路上的障碍物,就像图 2 (a)(1) 中那样,这样障碍物另一侧的车道就不会被标注。在本文中,我们将注意力集中在四个车道标记的检测上,这是在实际应用中最受关注的。其他的车道标记则没有标注。
3.2 SCNN
to more efficiently learn the spatial relationship and the smooth, continuous prior of lane markings, or other structured object in the driving scenario, we propose Spatial CNN. Note that the ’spatial’ here is not the same with that in ’spatial convolution’, but denotes propagating spatial information via specially designed CNN structure.
提出了空间 CNN ,以提高学习驾驶场景中空间关系以及车道线或其他结构化物体的平滑、连续先验信息的效率。需要注意的是,这里的“空间”与“空间卷积”并不相同,而是指通过专门设计的 CNN 结构传播空间信息。
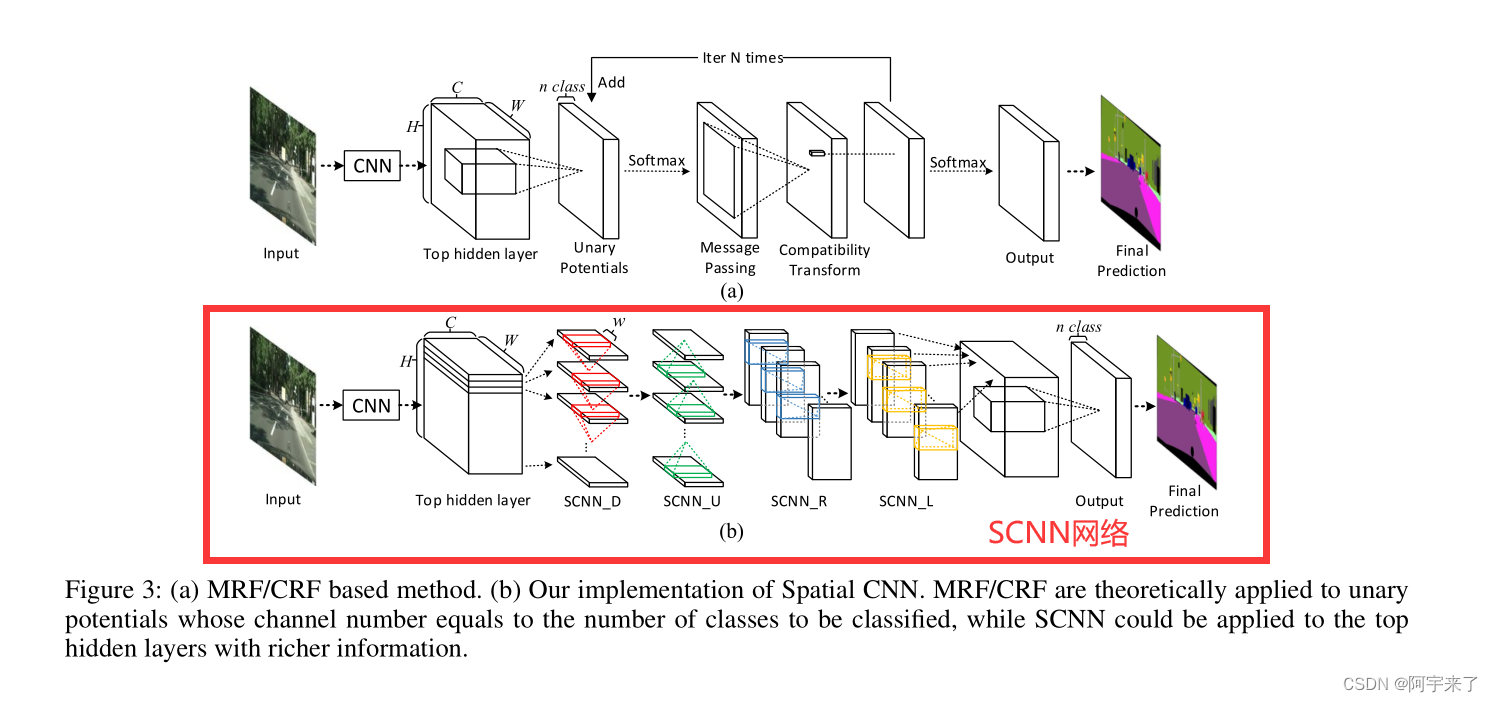
As shown in the ’SCNN D’ module of Fig. 3 (b), considering a SCNN applied on a 3-D tensor of size C × H × W, where C, H, and W denote the number of channel, rows, and columns respectively. The tensor would be splited into H slices, and the first slice is then sent into a convolution layer with C kernels of size C×w, where w is the kernel width. In a traditional CNN the output of a convolution layer is then fed into the next layer, while here the output is added to the next slice to provide a new slice. The new slice is thensent to the next convolution layer and this process would continue until the last slice is updated.
如图 3 (b) 的‘ SCNN D ’模块所示,考虑将 SCNN 应用在大小为 C × H × W 的 3-D 张量上,其中 C 、 H 、 W 分别表示通道数、行数、列数。张量会被分割成 H 个切片,然后第一个切片被送入卷积层,用 C 个大小为 C × w 的核,其中 w 是核宽度。在传统的
CNN 中,卷积层的输出然后被送入下一层,而这里的输出被添加到下一个切片以提供一个新的切片。然后,新的切片被发送到下一个卷积层,这个过程将继续,直到最后一个切片被更新。
Specifically, assume we have a 3-D kernel tensor K with element K i,j,k denoting the weight between an element in channel i of the last slice and an element in channel j of the current slice, with an offset of k columes between two elements. Also denote the element of input 3-D tensor X as X i,j,k , where i, j, and k indicate indexes of channel, row, and column respectively. Then the forward computation of SCNN is:
where f is a nonlinear activation function as ReLU. The X with superscript ` denotes the element that has been updated.
Note that the convolution kernel weights are shared across all slices, thus SCNN is a kind of recurrent neural network.
Also note that SCNN has directions. In Fig. 3 (b), the four ’SCNN’ module with suffix ’D’, ’U’, ’R’, ’L’ denotes SCNN
that is downward, upward, rightward, and leftward respectively.
.
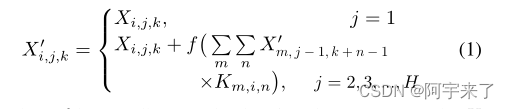
上图为SCNN 的正向计算。其中 f 是一个非线性激活函数,如 ReLU 。上标的 X 0 表示已更新的元素。需要注意的是,卷积核的权值是在所有切片上共享的,因此 SCNN 是 一种循环神经网络。 还要注意,SCNN 有方向。在图 3 (b) 中,后缀 ’ D ’ 、 ’ U ’ 、 ’ R ’ 、 ’ L ’ 的四个 ‘SCNN’ 模块分别表示向下、向上、向右、向左的 SCNN 。
总结
以上就是今天SCNN论文总结,后续补上GitHub代码实现以及模型代码+训练代码分析。


















 3115
3115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









