







 本文探讨了确定性系数模型(CF)与随机森林模型在滑坡易发性评价的应用。确定性系数模型用于分析灾害事件与因子之间的敏感性,而随机森林模型通过集成学习提供高准确性分类。研究中,选取了坡度、坡向、海拔等多个因素作为评价因子,利用随机森林确定最佳参数,如特征数和决策树个数,进行模型构建和预测。结果显示,高程、植被覆盖度、岩性和道路是影响滑坡易发性的重要因素,模型预测效果良好,为滑坡灾害防治提供了指导。
本文探讨了确定性系数模型(CF)与随机森林模型在滑坡易发性评价的应用。确定性系数模型用于分析灾害事件与因子之间的敏感性,而随机森林模型通过集成学习提供高准确性分类。研究中,选取了坡度、坡向、海拔等多个因素作为评价因子,利用随机森林确定最佳参数,如特征数和决策树个数,进行模型构建和预测。结果显示,高程、植被覆盖度、岩性和道路是影响滑坡易发性的重要因素,模型预测效果良好,为滑坡灾害防治提供了指导。
引
言
我国是一个多山的国家,地质环境多样,崩塌、滑坡、泥石流等地质灾害频发。据统计,给国民经济每年造成约200亿人民币的损失,已经严重危害了我们国家人民生命财产的安全。在我国滑坡灾害已经成为了仅次于地震的第二大地质灾害。通过科学编制滑坡灾害分区图,可以将灾害防患于未然,对指导防灾减灾和降低灾害带来的损失具有重要的意义。
目前,国内外学者采用了多种模型应用于滑坡易发性评价,总体可以将其归纳为定量方法和定性方法。定性方法主要包括专家经验法、层次分析法(AHP)和加权线性组合(WLC)等。定量方法主要分统计分析模型(信息量法(IM)、确定性系数(CF)等)和机器学习方法(支持向量机(SVM)、人工神经网络(ANN)等)。本文主要讨论确定性系数与随机森林模型在滑坡易发性评价应用研究。
1模型方法介绍
本文采用确定性系数与随机森林结合,其优势在于确定性系数是可以根据过去滑坡点与孕灾因子之间的关系确定滑坡的敏感性,即定量反映某孕灾因子的易发区间,但是缺点在于无法从整体上反映该因子对滑坡的贡献程度。随机森林模型作为集成学习的代表算法,在有限样本下,不易出现过拟合,又兼具有较好的准确性,在分类过程中有较好的表现,同时还能用于评价因子的重要性。通过确定性系数模型计算因子间不同区间的敏感性,作为分类的依据,利用随机森林模型进行训练以及预测。将二者进行结合,充分利用二者的优势进行耦合,对研究区易发性进行预测,同时评价各个因子的重要性,分析研究区滑坡发生的规律。
1.1确定性系数模型(Certain Factors)
确定性系数模型(CF)最早是Shortliffe和Buchanan提出,并由Heckerman以此为基础进行了改进。该模型是一个概率函数,属于双变量统计分析的范畴,可以用来分析灾害事件发生在各个因子之间一个敏感程度。其公式为:
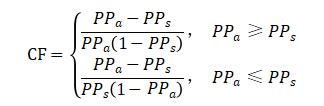
式中:PPa表示在影响因子a中单元存在的灾害点的个数与影响因子a的单元面积的比值;PPs为灾害事件在整个研究区中灾害发生的一个先验概率指数,表示了灾害在研究区总体的易发程度一个量化估计。PPs是通过研究区灾害点个数与研究区面积的比值计算得到。PPa与PPs相互比较大小,会得到不同的计算公式。由上述公式得知,CF值的变化范围在-1~1之间。当计算CF值大于0时,表示在该影响因子下容易发生灾害,越接近1代表该单元越容易发生灾害;当计算CF值小于0时,表示在该影响因子下不容易发生灾害,越接近-1代表该单元越不容易发生灾害;当计算CF值约等于0时,则不能确定该影响因子是否容易发生灾害。
1.2随机森林(Random Forests)
随机森林是由 Leo Breiman提出的一种机器学习算法,是属于集成学习的一种组合分类算法。随机森林是由多个弱分类器—决策树的集成,通过从原数据集中有放回地抽取多个样本,对抽取的样本利用决策树算法进行训练,然后把这些决策树组合在一起,通过投票,得票最多的即为最终的分类结果。随机森林算法主要步骤包括:
(1) 从原始样本中以有样本放回的方式取样多次,每进行一次则形成一个训练集。
(2) 在每次取样形成一个训练集后,则对应生成一颗决策树。假设样本共有M个特征,在M个特征中随机抽取F个特征作为决策树的每个内部节点的分裂特征集。
(3) 节点分裂方式为分类特征集最优方式分裂,决策树的生成使用CART算法。
(4) 将生成的所有决策树进行集成,组成随机森林算法,对新的数据进行分类预测。最终结果由每棵树的结果投票产生,得票多的即为分类结果。
2研究区概况
本次研究区收集滑坡点或滑坡隐患点共353个,主要类型以碎石土滑坡、残坡积层土质滑坡为主。碎石土滑坡多发育于河谷口岸坡或盆地边缘,主要岩性为泥盆纪白云岩,基岩裂隙发育,斜坡多为上陡、中缓、下陡的三段式结构,上段一般大于30°。残坡积层土质滑坡广泛分布于全
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









