




目录
8.6.1 BME-HDR(Binning Multiplexed Exposure)
8.6.2 SME-HDR(Spatially Multiplexed Exposure)
8.6.3 QBC-HDR(Quad Bayer Coding HDR)
8.6.4 双增益输出(Dual Gain Output,DGO)
1、Sensor
摄像头用来成像的感光元件叫做Image Sensor,目前广泛使用的两种分别是CCD和CMOS。单反使用全局快门 (global shutter)的CCD器件,手机常用的是卷帘曝光(rolling shutter)的CMOS器件。
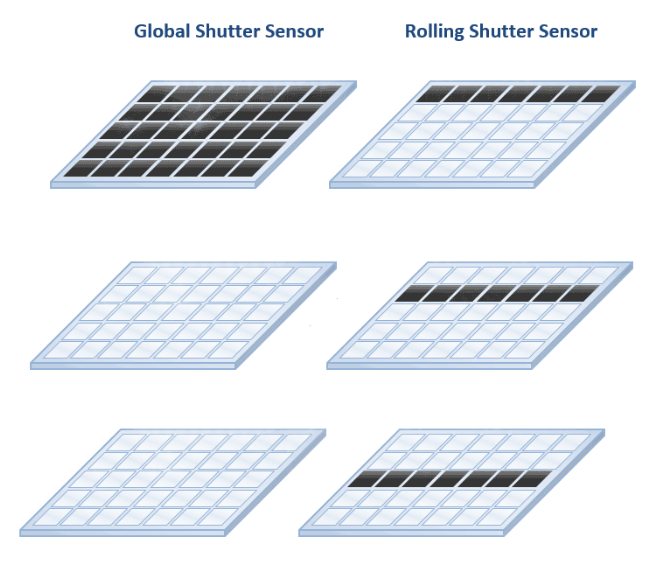
如上图所示,全局快门的特点是sensor 上所有像素是在同一瞬间全部开始曝光的,因此sensor 采集的是物体在同一时间点的画面。卷帘曝光的最显著特点是每一行像素开始曝光的时间点是不同的,是与像素位置有关的的函数。当画面中存在运动的物体时,物体在曝光过程中空间位置在不断变化,画面就发生变形,物体速度越快,变形就越严重。

Sensor成像的过程如下图所示: 首先,外界光照射像素阵列,发生光电效应,在像素单元内产生相应的电荷。行选择逻辑单元根据需要,选通相应的行像素单元。行像素单元内的图像信号通过各自所在列的信号总线传输到对应的模拟信号处理单元以及A/D转换器,转换成数字图像信号输出。其中的行选择逻辑单元可以对像素阵列逐行扫描也可隔行扫描。行选择逻辑单元与列选择逻辑单元配合使用可以实现图像的窗口提取功能。模拟信号处理单元的主要功能是对信号进行放大处理,并且提高信噪比。A/D转换器是把模拟信号转换为数字信号。
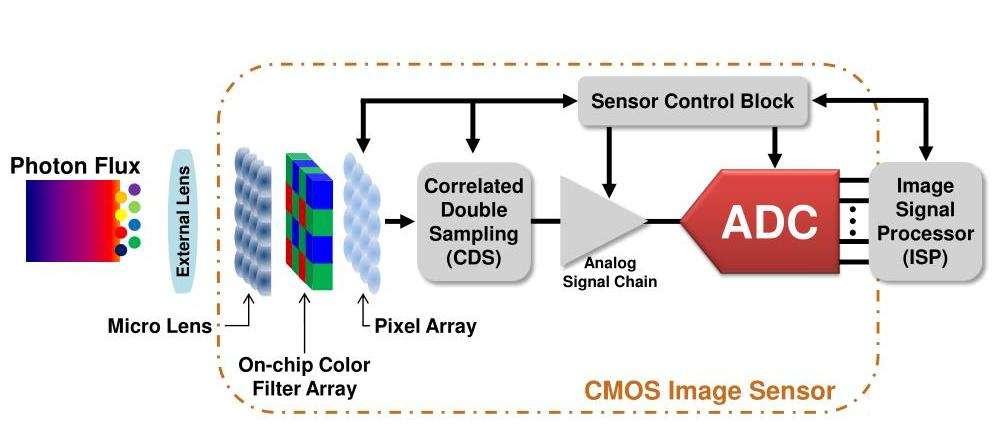
总结来讲,就是光照射像素阵列,发生光电效应,感光器件产生相应的电荷;然后按照行进行曝光,输出对应行的信号;接着模拟信号处理单元对信号进行放大;最后,模数转换,将模拟信号转换为数字信号。
2、算法的输入
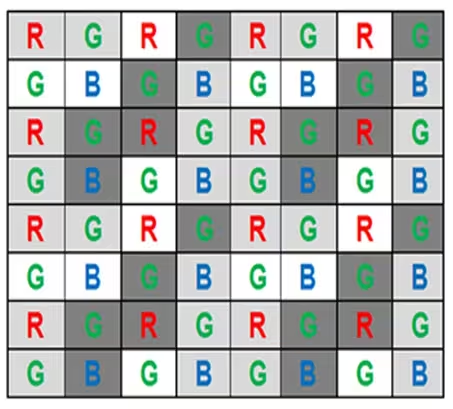
Sensor数字信号的常见输出形式有Raw和YUV等。RAW和YUV是两种常见的图像数据输出格式,主要区别在于数据处理阶段和应用场景。
2.1 RAW
RAW是传感器直接输出的原始数据,每个像素仅记录单通道(R/G/B)亮度,需通过Bayer插值还原为RGB图像,保留了更多的细节。
优点:是保留了完整信息,后期空间大,可以保留很多的暗部和亮度细节,适合后期处理(如调整白平衡、曝光等)
缺点:通常为12位或14位数据,所需的存储空间大,而且需软件处理才能显示
2.2 YUV
YUV由亮度(Y)和色度(U/V)组成,是一种处理后的中间格式,有轻微的压缩,但是可以直接显示。
3、BL
Sensor的信号输出时有一个AD转换的过程,但是实际AD芯片(模数转换芯片)的精度可能无法将电压值很小的一部分转换出来,因此,sensor厂家一般会在AD的输入之前加上一个固定的偏移量,以8bit数据为例,使输出的pixel value在5(非固定)~255之间,目的是为了让暗部的细节完全保留,当然同时也会损失一些亮部细节,由于对于图像来说,我们的关注度更倾向于暗部区域,ISP后面会有很多增益模块(LSC、AWB、Gamma等),因此亮区的一点点损失是可以接受的。
Sensor的电路本身会存在暗电流,导致在没有光线照射的时候,像素单位也有一定的输出电压,暗电流这个东西跟曝光时间和gain都有关系,不同的位置也是不一样的。因此在gain增大的时候,电路的增益增大,暗电流也会增强,因此很多ISP会选择在不同gain下减去不同的bl的值。
OB(Optical Black)是图像传感器在无光照条件下产生的暗电流值,用于校正图像暗部细节。ISP(图像信号处理器)中的BLC(黑电平校正)通过减去OB值和基底(Pedestal)优化图像质量。
RAW = sensor input - OB + pedestal(基底)
Sensor的感光区域可以分为有效像素区和有效OB区。这两个部分最大的区别在于,有效像素区是可以正常曝光的,而OB区在工艺上让它不能接受光子,最简单的想法就是在感光表明涂一层黑色的不感光物质,这样就能通过OB区无光照是的值来校正有效像素去的值。最简单的操作就是对OB去的像素值去平均,然后每个像素值减去这个值完成校正。
现在的主流cmos sensor都是自己把black level已经处理完了。在isp部分减掉的其实不是black level,而是sensor统一做出来的pedestal。sensor端不会将bl减完,因为sensor输出不能为负数,若将bl减完,就等于小于0的部分直接就丢掉了,这样做会改变noise的分布。
4、AWB
人眼具有颜色恒常性,可以避免光源变化带来的颜色变化,但是图像传感器不具备这种特性,从而造成色偏,白平衡(Auto White Balance, AWB)就是校正这个颜色的偏差。AWB就是通过某种算法将不同色温的环境光下成像后的白色还原成真实的白色(通常为自然日光环境光下的人观察到的白色)。
4.1 灰度世界法
灰度世界算法基于一个假说:任一幅图像,当它有足够的色彩变化,则它的RGB分量的均值会趋于相等(即灰色)
算法步骤:
- 计算各个颜色通道的平均值;
- 寻找一个参考值K,一般情况选取Gmean;
- 计算Rgain = Gmean/Rmean, Bgain = Gmean/Bmean;
- 对图像中的每个像素都乘以对应的gain值进行校正;
缺点:对于纯色场景,由于其颜色不够充足,灰度世界法就不适用了。
4.2 完全反射法(白块法)
完全反射也是基于一个假说:一幅图像中某个像素点最亮,代表它对各个波段的光线都近乎完全反射,那么它的真实颜色应该是白色的,即R=G=B,且RGB的值最大。
- 搜索图像中的最亮,且RGB的值最大的点。
- 计算Rgain = G/R,Bgain = G/B
- 将计算出来的Rgain和Bgain作用到每一个像素点
缺点:依赖于场景中有高光白块,如果没有白块的场景,就不适用了。
4.3 白点-色温标定法
该算法假设正常的画面中总会存在一些白色(灰色)区域,这些区域在不同光照条件下会表现出不同的(R/G,B/G)比值,
- 在实验室环境下测得不同色温光源下不同sensor对白色成像的R/G,B/G值
- 真实环境下,获取到整幅图像的R/G,B/G值,判断出当前处于什么色温,根据色温给出对应的Rgain和Bgain
缺点:在实际应用中,白点-色温标定法偶尔也会遇到基本假设不成立的情况,主要存在于画面亮度很低,或者一些比较特殊的场景。
5、去噪
Camera的噪声模型主要描述了图像采集过程中噪声的来源及其数学特性,包括泊松噪声(光子噪声和暗电流噪声)以及高斯噪声(读出噪声和ADC噪声)。 由2.1可知,获取raw图的过程包括以下三个部分:光照转换成电信号,经过模拟放大,AD 转换。在这个过程中,会有三个地方产生噪声:
- photon noise and dark noise:由于光激发电子的随机性,会产生 photon noise,而 sensor 本身由于发热激发的暗电流也会产生噪声,这种噪声称为 dark noise 或者热噪声
- read noise:模拟放大器在放大信号的时候,会产生噪声,这种噪声称为 read noise
- ADC noise:模数转换器在进行模数转换的时候,会产生噪声,这种噪声称为 ADC noise
5.1 泊松噪声
泊松分布式一种离散分布,均值和方差都是 λ 。
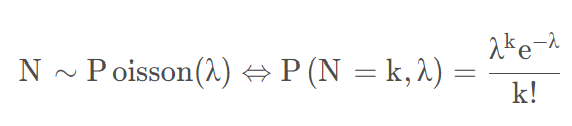
可加性
两个独立且服从泊松分布的随机变量,其和仍然服从泊松分布。![]() ,
,![]() ,则
,则![]() 。
。
乘以常数
若随机变量 X∼Poisson(λ),则 Y=cX(c 为常数)的期望和方差为:
- 期望:E(Y)=cλ
- 方差:Var(Y)=
λ
5.1.1 光子噪声
photon noise 是和环境照度相关的一种噪声,假设环境照度为 Φ ,光电转换效率为 α ,曝光时间为 t,则 photon noise 满足如下分布:
n_photon noise∼P(Φ,α,t)=P(Φ⋅α⋅t)
5.1.2 热噪声
dark noise 则和暗电流有关,和环境照度无关,曝光时间越长,电流导致 sensor 发热越大,产生的噪声也越多,假设暗电流强度为 D,曝光时间为 t, 则 dark noise 满足如下分布:
n_dark noise∼P(D⋅t)
5.2 高斯噪声
高斯噪声服从高斯分布,即正态分布(Normal distribution),通常记作X~N(μ ,)。其中, μ是正态分布的数学期望(均值),
是正态分布的方差。
如果![]() ,
,![]() ,且X和Y是统计独立的正态随机变量,那么它们的和为:
,且X和Y是统计独立的正态随机变量,那么它们的和为:
![]()
5.2.1 读出噪声
拟放大器在放大信号的时候,会产生read noise 读出噪声,是满足均值为 0 的高斯分布。
n_read∼N(0,)
5.2.2 ADC噪声
ADC噪声是模数转换器在进行模数转换的时候产生的,也是满足均值为 0 的高斯分布。
n_ADC∼N(0,)
5.3 噪声模型
信号放大前的信号记为L,L=n_photon noise+n_dark noise,L~P(Φ⋅α⋅t+D⋅t)。信号放大过程,就是把前面光电转换的电信号进行放大,放大系数是由电路系统本身决定的,也就是我们通常所说的 gain 值,这个值和 ISO 有关。
g=k⋅ISO
经过放大后的信号为
G=L⋅g+n_read⋅g
再经过后面的 ADC 转换之后的数字信号记为I
I = G+n_ADC = L⋅g+n_read⋅g+n_ADC
I ~ P(Φ⋅α⋅t+D⋅t)⋅g + N(0,)⋅g + N(0,
)
= P(Φ⋅α+D)⋅t⋅g + N(0,⋅g+
)
从上面可知 ,噪声模型是一个泊松高斯的联合噪声,高斯项是一个加性噪声。
I的均值和方差分别为:
E(I) = (Φ⋅α+D)⋅t⋅g
D(I) = (Φ⋅α+D)⋅t⋅ +
⋅
+
= (Φ⋅α+D)⋅t⋅ +(
⋅
+
)
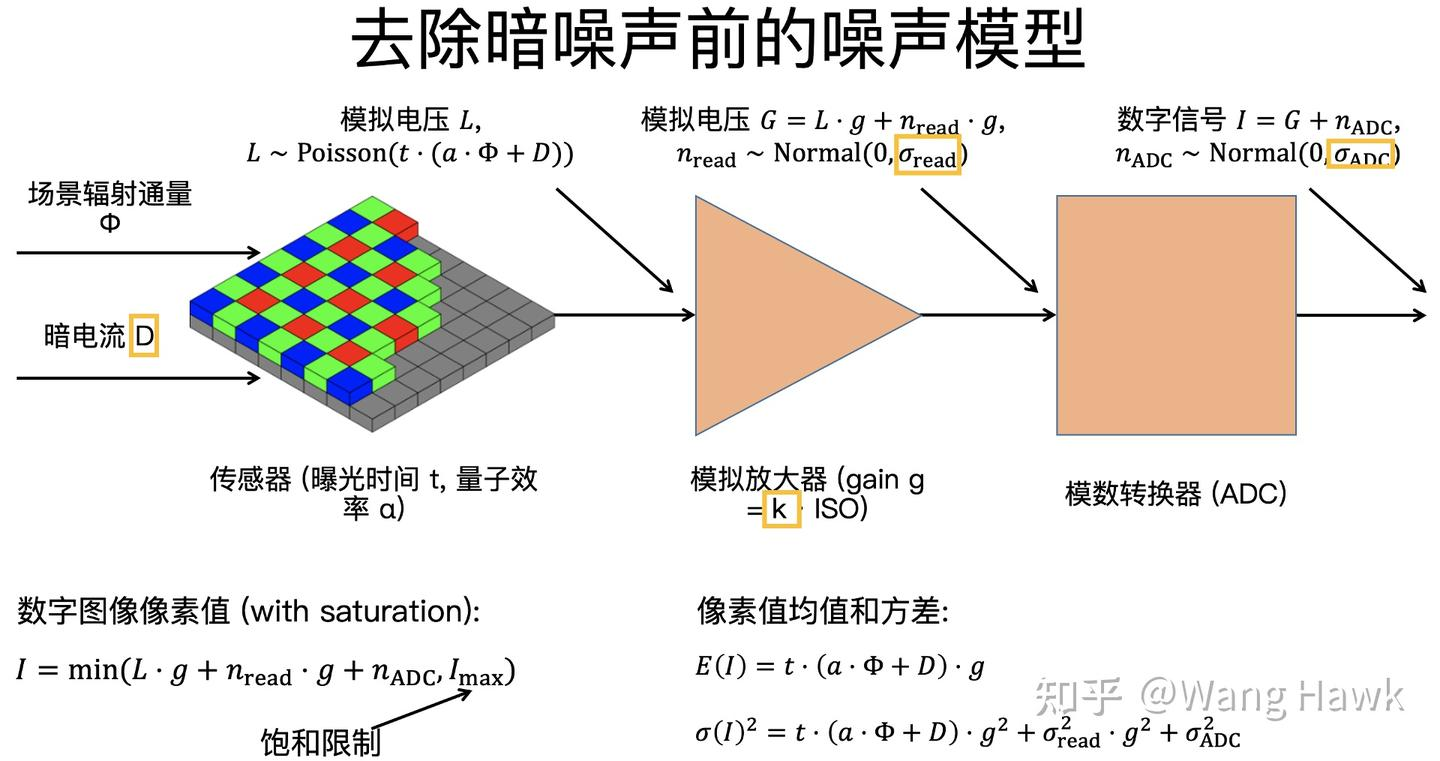
如果我们把相机镜头遮挡住,并在这个状态下拍摄大量的图像,再对这些图像取均值,相当于在令环境照度为 Φ =0,于是这个均值图像相当于:
![]()
不必求出暗电流D的具体值,只需要在同等曝光时间和ISO设定的图像中减去这个暗帧,就可以消除图像中的暗噪声。消除掉暗噪声后,相机的噪声模型就变成了下图所示:
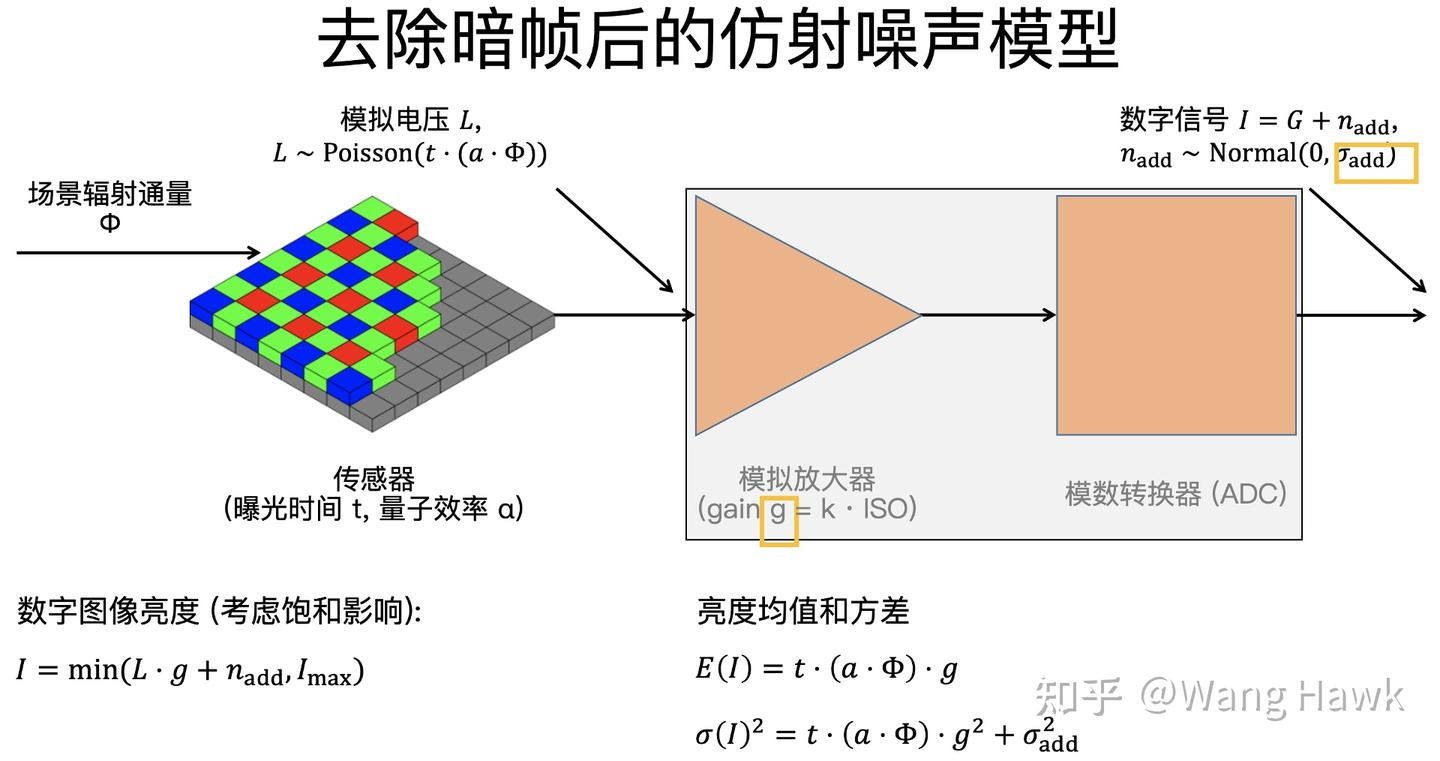
此时噪声有两项,一项是与信号相关的泊松噪声,另一项是与信号无关的高斯噪声。数字信号I的分布如下:
I ~ P(Φ⋅α⋅t)⋅g + N(0,⋅g+
)
I的均值和方差变为:
E(I) = Φ⋅α⋅t⋅g
D(I) = Φ⋅α⋅t⋅ +
⋅
+
= Φ⋅α⋅t⋅ +(
⋅
+
)
= E(I)⋅g+(⋅
+
)
5.3.1 信号相关的噪声
使用线性拟合的方式进行信号相关的泊松项噪声的标定。
D(I) = E(I)⋅g+(⋅
+
)
可以看到方差D(I)和图像亮度E(I)和增益g都成线性关系。在同一个曝光组合下拍摄不同灰度色卡,计数不同灰度下的方差,使用Stats.linregress( )对色卡均值和方差做线性回归,横坐标为灰度,纵坐标为方差,可以得到斜率和截距。斜率是增益g,截距是高斯加性噪声。
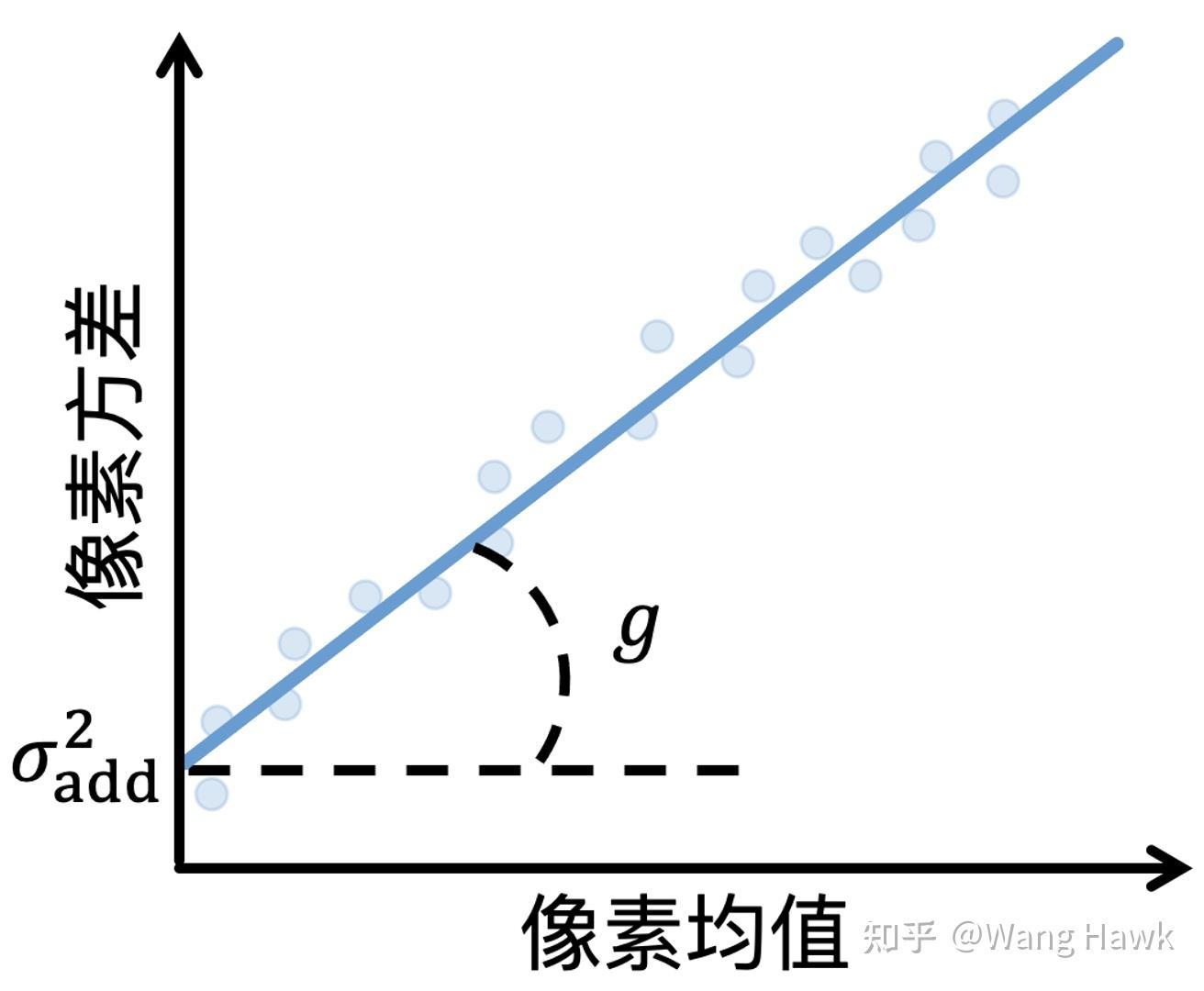
斜率:因为泊松噪声的特殊性,经过增益后方差被放大倍,均值被放大
倍,所以可以直接得到方差为E(I)*g。可以得到不同ISO下的斜率,很明显增益g和ISO(ISO指的是a gain*d gain)成正相关,可以考虑使用直线拟合斜率和ISO的关系。
截距:注意这里的截距指高斯加性噪声,包含了读出噪声和ADC噪声:
5.3.2 信号无关的噪声
与信号无关的噪声是高斯噪声,有两部分组成,且是加性噪声。读出噪声与增益有关,ADC噪声与增益无关。最后的读出噪声是原始读出噪声乘以增益,对应方差变为原始读出噪声的方差乘以增益的二次方,而增益系数又与ISO是线性关系,所以读出噪声的方差和ISO的关系可以使用二次函数表示。使用np.polyfit最小二乘法进行多项式拟合,会标定得到三个数,分别是二次项系数,一次项系数,常数项。
通常使用黑帧的方法也可以得到加性噪声,使得信号为0,得到的数据自然就是信号无关的噪声。
5.4 噪声标定
噪声标定的流程:
- 首先,相同的环境和参数下采集多张图片,对采集的每张图像减去当前的暗帧,然后求取每个像素的均值和方差。
- 通过采样大量不同均值的像素点的信息,可以很容易的拟合出一条直线,斜率是增益,截距是加性噪声(高斯噪声)的方差。
- 泊松项的方差与增益是一次项的关系,高斯噪声的方差与增益是二次项的关系,分别拟合出其参数。
6、超分
超级分辨率(Super-Resolution,SR)是通过软件算法对现有图像进行放大并提升清晰度的一种技术,适用于低像素原始文件。通过深度学习技术扩大图像像素,抑制画质下降,适用于特写、远景等需要细节放大的场景。 超分是一个ill-poseed问题,没有稳定解和唯一解 。实现方式有传统的插值算法和AI模型。
传统的插值方法有:最近邻插值,双线性插值,双平方插值,双立方插值以及其他高阶方法。最近邻插值和双线性插值算法很容易出现锯齿,生成的图片质量不好。因此一般只在对图像质量要求不高的场合下采用。双平方插值和双立方插值,实质上是”低通滤波器”,在增强图像平滑效果的同时丢失了许多高频信息。而在很多应用场合,细节信息恰恰非常重要,要考虑如何在保证平滑效果的同时尽可能地保留细节信息。
7、demosaic
对RAW数据进行插值的过程叫做Bayer demosaicking,其原理如下图所示:
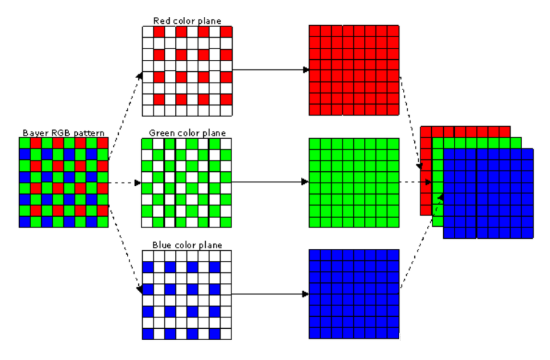
Demosaic 的难点在于,RAW域的任何一个像点(photosite)只包含一个真实的采样值,而构成像素(R,G,B)的其它两个值需要从周围像点中预测得到。既然是预测,就一定会发生预测不准的情况,这是不可避免的,而预测不准会带来多种负面影响,包括拉链效应(zipper artifacts),边缘模糊,颜色误差等。

Demosaic有两种方式,一种是传统的插值算法,另一种是AI模型。
7.1 最近邻插值
最近邻插值算法是将目标图像中的点,对应到原图像中后,找到最相邻的整数坐标点的像素值,作为该点的像素值输出。图像会出现明显的块状效应,会在一定程度上损失空间对称性(Alignment)。最近邻法速度最快,没有考虑像素之间的空间关系、色彩关系,效果不佳。
7.2 双线性插值
sensor输出一幅Bayer时,每个像素只有R,G,B三个通道中的一个通道的像素,通过插值算法把缺失的像素估计出来,m*n的二维数组插值为m*n*3的3个二维数组。举例说明一下双线性插值,以下图的GRBG bayer矩阵为例:

以G3,3 这个点为例,我们需要求出G3,3点处的R 和B像素数值
R3,3=(R3,2+R3,4)/2
B3,3=(B2,3+B4,3)/2
以R3,4 这个点为例,我们需要求出R3,4点处的G和B像素数值
G3,4=(G2,4+R3,3+G3,5+G4,4)/4
B3,4=(B2,3+B2,5+B4,3+B4,5)/4
以B2,5 这个点为例,我们需要求出B2,5点处的G和B像素数值
G2,5=(G1,5+R2,4+G2,6+G3,5)/4
R2,5=(B1,4+B1,6+B3,4+B3,6)/4
根据同样的原理,我们可以对Bayer图像中的每一个点都进行插值,得到插值结果。双线性插值是基于相邻像素的线性加权平均,计算简单但易产生伪彩色(如栅栏区域的“拉链效应”)。而且忽视了各通道间的相关性,插值结果往往带有比较严重的伪彩色。
8、HDR
高动态范围成像(High Dynamic Range Imaging,简称HDRI或HDR),在计算机图形学与电影摄影术中,是用来实现比普通数位图像技术更大曝光动态范围(即更大的明暗差别)的一组技术。
普通相机(甚至是手机相机)在同一张照片中很难同时精确地展现出极亮和极暗的细节。换句话说,当我们拍摄一张照片时,常常会发现照片的某些部分过曝(例如天空过亮,细节丢失),而另一些部分又可能是欠曝的(例如阴影部分的细节无法清晰呈现)。
HDR 模式的出现正是为了解决这个问题。它通过将不同曝光度的多张照片合成在一起,保留更多亮部和暗部的细节,从而实现更加丰富和真实的图像效果。HDR 模式能够将图像的亮度范围扩展,从而模拟出更接近人眼感知的视觉效果。
曝光三要素:光圈、快门、ISO。
8.1 光圈
光圈主要负责控制进入相机的光线量。光圈越大,单位时间内进入的光线就越多,照片的亮度也就越高。反之,光圈越小,进入的光线量就越少,照片的亮度则相应降低。
8.2 快门
快门负责控制曝光时间。快门速度越快,曝光时间就越短,进入相机的光线量也就越少。相反,快门速度越慢,曝光时间就越长,进入的光线量则越多。
8.3 ISO
ISO也是影响曝光效果的重要因素。ISO越高,相机对光线的敏感度就越高,即使在光线较暗的环境下也能拍摄出明亮的照片。然而,过高的ISO也可能导致照片出现噪点,影响画质。
8.4 EV
快门速度、光圈(F值)和ISO共同决定曝光量。曝光量 = T(时间)× F²(光圈平方)× ISO。当快门速度、光圈的平方、ISO三者乘积相同时,画面的亮度相同。这一规律被称为等值曝光原理,其核心在于三者组合形成的曝光量恒定。
对于同一环境,当快门速度、光圈的平方、ISO三者乘积相同时,画面的亮度相同,且这三者乘积翻倍时,称为“增加一档曝光”,即+1EV。例如同一环境中,乘积为4相对乘积等于1为+2EV。摄环境的时候,如果照片过暗,要增加EV值,如果照片过亮,要减小EV值。相对于所谓”正确曝光“的照片,曝光补偿若为正值则过曝,若为负值则欠曝,并以EV值为单位计算。
EV值(Exposure Value)是描述绝对照度的摄影用单位,与照度Lux是一一对应的,有以下关系:
![]()
EV = log₂(F²/T)-log₂(ISO/100)。
对于所谓”正常曝光“的照片,在iso为100时,EV=log₂(F²/T)。
8.5 多帧HDR
多帧HDR是最普通的实现HDR的方法。优点是对CIS要求不高,所有CIS都可以实现时域HDR;缺点是若被摄物体移动较大,则会产生叠影。
当遇到明暗差距很大的场景时,手机的CIS面积小,仅依靠普通的单次曝光无法提供足够的动态范围,即要么高光过曝,要么暗部难以看清。因此拍摄多张照片,一部分提高曝光使照片的暗部可以看清,另一部分压低曝光使照片亮部可以看清,该过程称为包围曝光。将这样的照片叠加,即可得到暗部亮部均清晰的照片,从而变相提高动态范围。手机的夜景模式,就是一种较为暴力的HDR合成。

8.6 单帧HDR
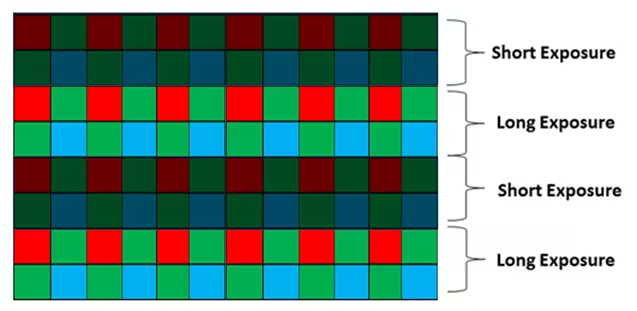
8.6.1 BME-HDR(Binning Multiplexed Exposure)
这种HDR方式将CIS上每两行为一组(因为Bayer排列的RGGB需要占用两行),分别进行长、短曝光。长曝光获得暗部细节,短曝光获得亮部细节,将相邻两组的图像合并即可获得更高的动态范围。缺点很显著,就是其分辨率会减半。
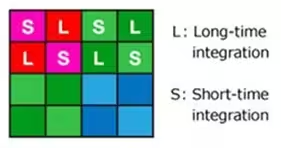
8.6.2 SME-HDR(Spatially Multiplexed Exposure)
这种方式在4x4的Bayer阵列中,对不同的像素采用不同的曝光,最终合成HDR图像。大约损失20%的图像质量。总体上还挺复杂的。
8.6.3 QBC-HDR(Quad Bayer Coding HDR)
这种方式与上一种类似,但结合了Quad Bayer排列使用,在4个同颜色滤光片下,两对角线的像素分别采用长短曝光,从而合成HDR图像。
8.6.4 双增益输出(Dual Gain Output,DGO)
这种方式需要结合双电路增益(双原生ISO)技术,两路不同原生ISO的图像同时输出并融合,从而提升图像的信噪比。这种方式主要应用于摄像机上,例如ARRI和Canon的部分摄像机等等。
DGO对于动态范围提升的幅度虽然不如前几种大,但仍然非常显著,并且对画质不会有什么负面的影响,除了功耗和成本略高一些就没什么缺点了。
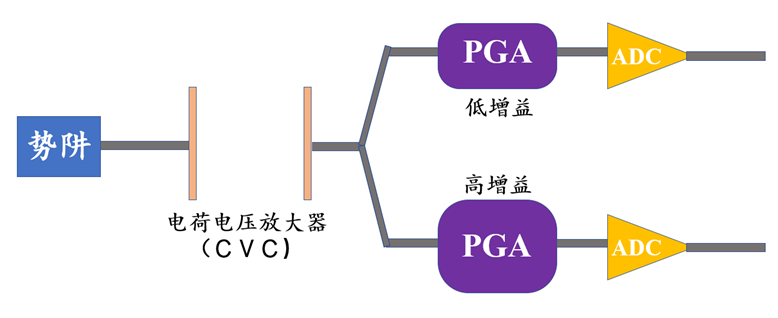
双原生ISO技术(Dual Gain Amplifier)
双原生ISO技术是指:电路中有两条电路,连接增益大小不同的PGA。
事实上,更准确地讲,该技术应称为双电路增益。
9、配准算法
相机领域中的配准:
- 为图像融合算法(多帧降噪MFNR、多帧HDR、多帧大小FOV融合)提供辅助帧往参考帧上对齐的功能,使融合算法能更多利用参考帧图像内容,实现全局/局部清晰度、对比度效果提升。
- 防抖功能中,为了视频效果减少拍摄设备带来的抖动感,将当前帧的图像内容对齐到运动轨迹平滑后的当前帧位置。
- 相机拍照时,为解决sensor行曝光和rolling shutter带来的图像形变,对当前图像做图像校正的功能。
- 基于RGB相机的3D建模、SLAM中tracking模块。
9.1 全局配准
待配准帧和参考帧分别对raw图抽取2个G通道取均值->下采样到1/4尺寸(1/2w*1/2h)->待配准帧做亮度对齐(根据metadata中的iso expoT算出gain,乘到全图上),保证变曝光帧与N帧亮度一致->gamma变换将图像拉亮(因为RAW图本身很暗)->做5*5的高斯滤波做中等平滑去噪->参考帧与待配准帧做完预处理后,再分别进行特征提取。
全局配准算法主要通过计算单应性矩阵(H矩阵)实现图像对齐,其核心步骤包括关键点检测、特征匹配和H矩阵求解。
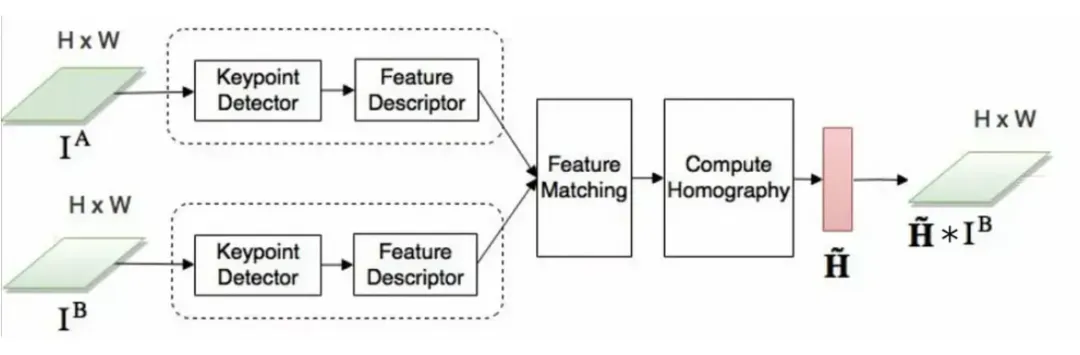
9.1.1 关键点检测
常用算法:SIFT、ORB、AKAZE等,用于检测图像中的关键点(如角点、边缘)。
考虑采用Shi-Tomasi 角点检测算法,它是一种改进的角点检测算法,在Harris 角点检测算法的基础上进行了优化,改进了角点响应函数,以最小特征值作为响应函数,实现了更鲁棒、参数更直观的角点检测。
从配置中读配准阈值参数,不同iso下配准结果是否有效的校验阈值是不一样的(iso低,画面亮,对配准点的匹配要求就高,反之则要求低)
根据不同帧类型,校验一些参数如lv iso等,校验帧是否有效,无效的帧需要丢掉(比如待配准的Normal帧,如果相对于参考帧Normal帧 LV iso变化较大,也不参与配准),拦截一些不需要配准的异常情况
9.1.2 特征匹配
匹配策略:通过特征描述子匹配两幅图像中的对应关键点,筛选出高置信度的匹配对(如使用RANSAC剔除异常值)。利用全部内点和最小二乘法算出最终的单应性矩阵(H矩阵)。
9.1.3 H矩阵求解
H是一个3×3矩阵,描述两平面(如图像平面)间的投影变换关系,满足:
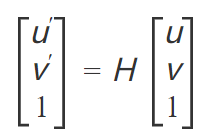
自由度:H有8个独立参数(因齐次坐标尺度不变性),需至少4对匹配点求解。
H矩阵式一个3*3的矩阵,如下图所示:

其中 0134 为旋转,25为平移,67为缩放,h8==1(归一化)。处理时会设置阈值:
- abs(h0-1) || abs(h4-1) > threshRotate(0.0X)对应旋转超过阈值
- h2 || h5 > threshShift(X0) 对应平移超过阈值X0(几十)个像素
- h6 || h7 > threshZoom(0.000X)对应缩放超过阈值
当上述任意一个值超过阈值时,认为两帧图像间位移量较大,丢掉待配准帧(该帧不需要warp到参考帧,也不再参与后续多帧融合)。通过映射矩阵将待配准帧映射warp到参考帧坐标系。最终将配准后的多帧送网络进行融合。
工程优化:
低分辨率预处理:对图像下采样后计算H,再缩放至原尺寸以减少计算量。
多帧配准:在手机HDR场景中,需对多帧图像(如N帧、L帧)分别配准,通过亮度对齐和高斯滤波预处理后提取特征
9.2 局部配准
10、ToneMapping
当HDR模块完成多帧合成(frame stitch)后,接下来就需要对数据位宽进行压缩以节约后续步骤的计算资源。比较合理的做法是采取逐级压缩策略,比如在HDR模块先压缩到12位精度,经过CCM、Gamma 等颜色处理后进一步压缩到10位精度,经过CSC模块后进行最后一次压缩得到最终的8位精度输出。从16/20位精度压缩到12位精度的过程称为色调映射,这一步骤的主要任务是压缩图像的动态范围,将HDR图像映射到LDR图像,并尽量保证图像细节不损失。
色调映射的方法大致分为两类 ,即全局算法(Global Tone Mapping,GTM)和局部算法(Local Tone Mapping,LTM)。
10.1 GTM
全局算法可以理解为每幅图像有一个颜色映射表,GTM算法通过查表的方法把一个输入颜色映射为一个输出颜色。有些算法对所有图像都使用固定的表,有些算法则是针对每一帧图像创建不同的表。
GTM算法特点 :
- 任意相同颜色的像素点,在映射后,还是相同的颜色;
- 全局算法一般较简单,速度快;
- 全局算法的性能一般劣于局部方法;
存在算法 : 直方图均衡化、Gamma、对数校正、直方图规定化、分段灰度变换
10.2 LTM
局部算法借鉴了人眼的知觉原理,在映射一个像素时,不仅考虑该像素的绝对值,还会考虑该像素周围区域的平均亮度值,将对比度大的像素映射为高亮,对比度小的像素映射为低亮,往往可以取得更好的效果。
LTM算法特点 :
- 映射前颜色相同的像素点,映射后颜色可能不同
- 局部算法一般较全局方法更复杂,速度相对较慢;
- 局部算法的性能一般优于全局方法;
- 会出现光晕等现象
11、LSC
镜头阴影有两种表现形式,分别是
- Luma shading,又称vignetting,指由于镜头通光量从中心向边缘逐渐衰减导致画面边缘亮度变暗的现象。
- Chroma shading,指由于镜头对不同波长的光线折射率不同引起焦平面位置分离导致图像出现伪彩的现象。
11.1 Vignetting

如上图所示,由于镜头中都会存在多处光阑,当入射光线偏离光轴角度较大时,部分光线就会被光阑遮挡而不能参与成像,因此越靠近sensor边缘的像素接收到的曝光量就越低。
11.2 Chroma shading
镜头对不同波长的光线折射率不同会导致色差问题,即不同波长的焦点在空间上不重合,导致焦平面分裂为三个不完全重合的曲面,这会破坏图像的白平衡,使图像出现伪彩,如下图所示。根据sensor所处的前后位置不同,伪彩可能偏红也可能偏蓝。

12、CCM
人眼在可见光波段的频谱响应度和半导体传感器的频谱响应以及显示器的激励响应都存在较大的差别,这些差别会对摄像机的色彩还原造成较大的影响。举例来说,从下图所示的光谱响应曲线中可以了解到,一个典型的硅材料sensor在500nm处对蓝、绿光的响应几乎是相等的,但是人眼的蓝色锥细胞对500nm的蓝绿光响应却几乎为零。假设sensor按照自己的特性忠实地记录下它对500nm波长的响应值为b,根据CIE的标准,显示器会在b值的驱动下发出波长为435.8nm的蓝光,使人眼感知到明亮的蓝光。这个过程在人眼看来,就是成像系统在绿色中凭空增加了很多蓝色的成分,降低了绿色的饱和度,造成了颜色失真。
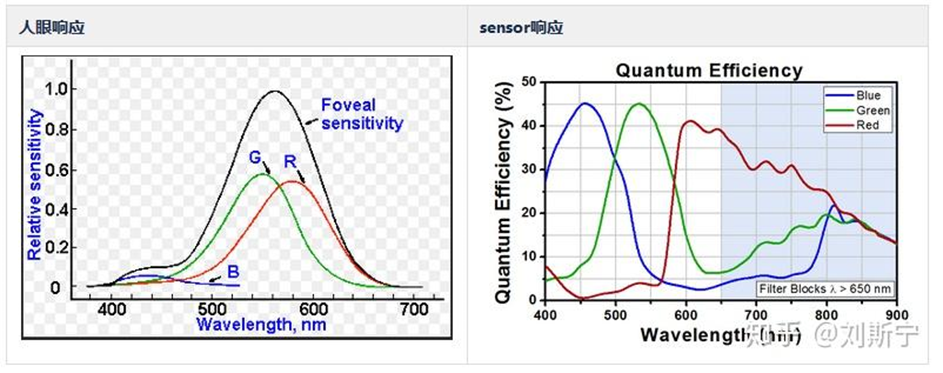
此外,摄像机光路上一般还存在镜头、滤波片等光学元件,镜头的镀膜、滤光片的频率响应等参数也会对色彩还原造成影响,这些因素综合作用的结果,就是人眼在显示器上看到的RGB颜色与真实世界中感知到的物体颜色存在偏差, 尤其是色饱和度受到较大影响,因此必须对摄像机记录的颜色进行校正以还原人眼的感知效果。
颜色校正,英文color correction,是在RGB空间中完成的处理任务,主流的做法是用一个3x3 的矩阵将一个输入像素值(R, G, B)线性地映射为一个新的像素值(R', G', B'),通过审慎地选择矩阵参数使映射后的颜色更符合人的认知习惯。这个3x3 的矩阵叫做颜色校正矩阵,英文color correction matrix,简称CCM,其变换公式如下。

CCM公式的一个基本约束就是不能破坏白平衡,即对于任何R=G=B的输入,必须保证输出满足R'=G'=B'。正式由于这个原因,颜色校正操作只能放在白平衡调整之后执行。
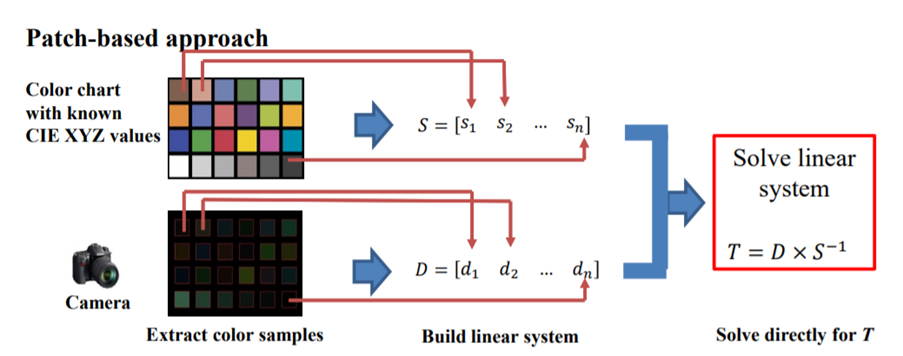
实践中通常使用X-Rite 24色卡上的18个彩色色块为标准计算校正系数,基本原理是用摄像机拍摄色卡,提取18个色块的平均颜色(Rn, Gn, Bn),n=1..18 构成输入矩阵
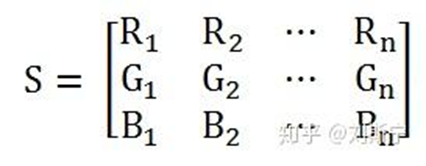
用24色卡上的18个彩色色块的标准RGB值构成目标矩阵

则有关于CCM的矩阵方程

求解M的过程如下
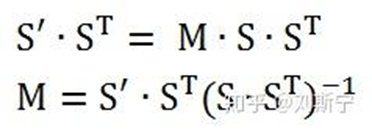
上述过程需要使用某种色卡,因此称为patch-based方法。



















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









