






seq2seq,是生成式模型,诞生之初主要是为解决RNN无法处理不定长配对的问题。
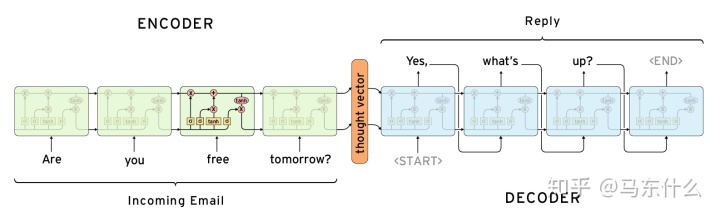
除此之外,另一个重要的地方在于,seq2seq的结构可以更好的处理一些场景下的输出问题,典型的就是时间序列预测的多步预测,标签之间存在着很强的序列相关性,这部分之前写过了:
马东什么:深度学习在时间序列预测上的三种策略以及一些soa模型的总结zhuanlan.zhihu.comseq2seq要解决的核心问题是 序列、序列、序列,无论是文本的离散序列还是时间序列预测的连续序列,因此,cnn、rnn等这类可以学习到序列相关性的模型都可以作为其输入和输出,所以基本上没看到有人把DNN放进seq2seq结构的,虽然也是可以实现的。。。
典型的应用就是:

encoder端使用cnn,decoder端使用RNN,完成图片文本描述自动生成的任务。
然后时seq2seq的目标函数:
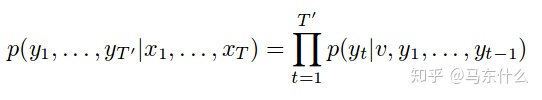
对于输入序列x1,...,xT与输出序列y1,...,yT'而言,通过Encoder我们能将x1,...,xT转换成上下文向量v,我们希望能在Decode阶段最大化条件概率p,可以看到输出的长度时T',输入的长度是T。
早期直接使用LSTM,输入和输出必须是等长度的:
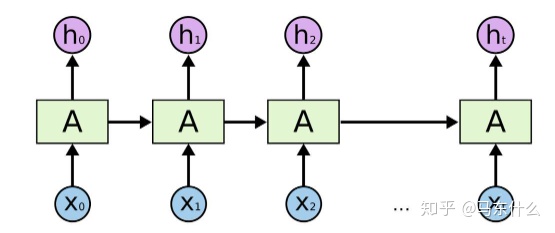
那个时候没有seq2seq的概念,直接用LSTM来完成机器翻译,输出是每一个cell的hidden state,因此模型结构固定了输出的长度为cells的个数,对于时间序列的多步预测也是,这意味着我们只能用n个历史特征来预测未来的n个时间步的结果。
seq2seq的两个高级概念:teacher forcing 和beam search
陈猛:简说Seq2Seq原理及实现zhuanlan.zhihu.com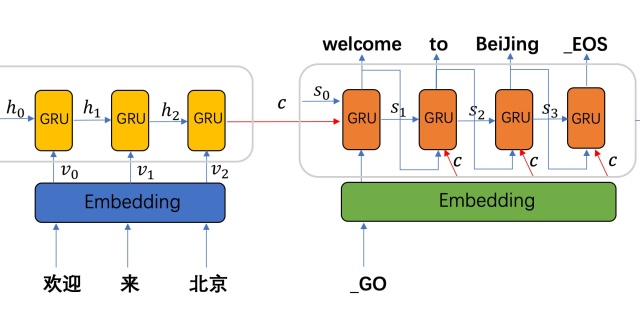

这部分,这三篇文章都写的比较好。
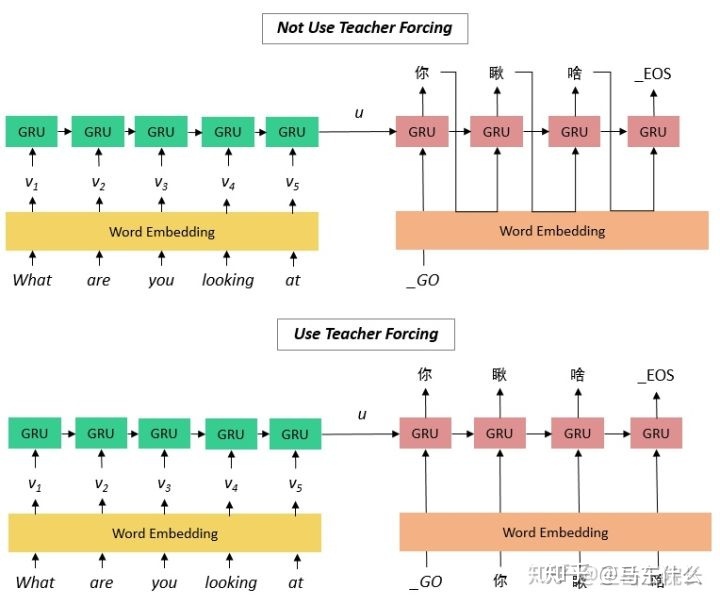
teacher forcing是训练seq2seq的一种技巧,不使用seq2seq则,如上图:
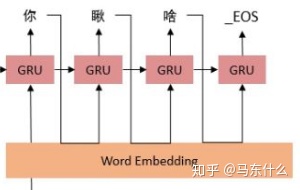
”瞅“的输入是”你“的prediction与hidden state。。后面依此类推,这样的问题和之前提到过的
马东什么:时间序列多步预测的五种策略zhuanlan.zhihu.com递归多步预测的问题是一样的,用预测的结果作为输入特征会导致误差的积累,特别是初始的预测结果如果存在误差则后续的误差会越来越大。
思路也不复杂,我们原本是使用第t+1个时间步的预测结果和hidden state作为t+2的时间步的输入(这种训练方式的叫法这么多的吗,有叫autoregressive的,有叫贪婪模式的,有叫free running的。。。),使用teacher forcing之后,使用第t+1个时间步的真实标签和hidden state作为第t+2个时间步的输入。
teacher forcing的好处在于可以加快模型收敛同时避免了误差累计传播的问题。
这里有一个更形象的例子:
炫云:Teacher Forcing训练机制zhuanlan.zhihu.com
RNN存在着两种训练模式(mode):
free-running mode
teacher-forcing mode
free-running mode就是大家常见的那种训练网络的方式: 上一个state的输出作为下一个state的输入。而Teacher Forcing是一种快速有效地训练循环神经网络模型的方法,该模型使用来自先验时间步长的输出作为输入。

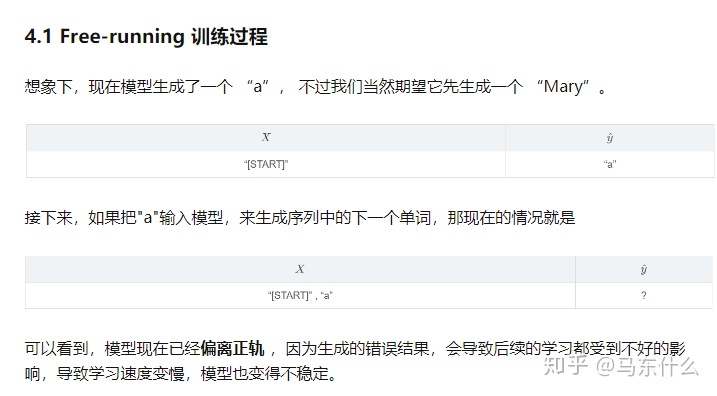
时间序列问题同理。
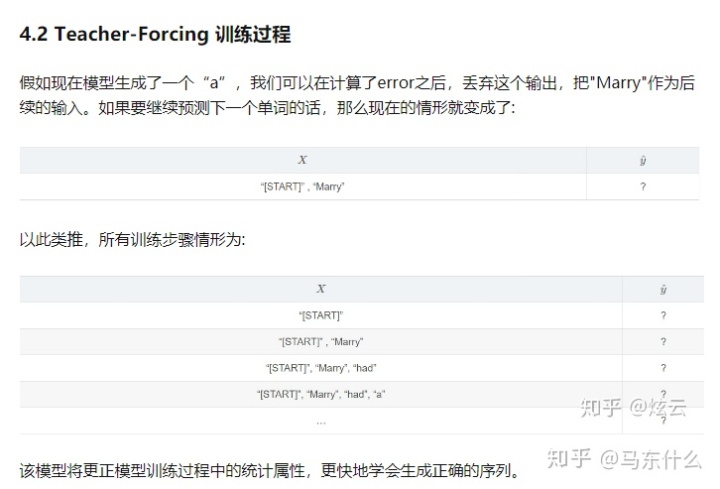
缺点是:
这些文章讨论了在进行自然语言处理的时候存在的其他问题:
Dreaming.O:关于Teacher Forcing 和Exposure Bias的碎碎念zhuanlan.zhihu.com上面的『比喻』,其实就是不太严谨的 Exposure Bias 现象了。更严谨的表述,由于训练和预测的时候decode行为的不一致, 导致预测单词(predict words)在训练和预测的时候是 从不同的分布中推断出来的。而这种不一致导致训练模型和预测模型直接的Gap,就叫做 Exposure Bias。
实际上说的就是特征分布偏移导致模型存在偏差的问题;
Teacher-Forcing 技术在解码的时候生成的字符都受到了 Ground-Truth 的约束,希望模型生成的结果都必须和参考句一一对应。这种约束在训练过程中减少模型发散,加快收敛速度。但是一方面也扼杀了翻译多样性的可能。
Teacher-Forcing 技术在这种约束下,还会导致一种叫做 Overcorrect(矫枉过正) 的问题。例如:
1. 待生成句的Reference为: "We should comply with the rule."
2. 模型在解码阶段中途预测出来:"We should abide"
3. 然而Teacher-forcing技术把第三个ground-truth "comply" 作为第四步的输入。那么模型根据以往学习的pattern,有可能在第四步预测到的是 "comply with"
4. 模型最终的生成变成了 "We should abide with"
5. 事实上,"abide with" 用法是不正确的,但是由于ground-truth "comply" 的干扰,模型处于矫枉过正的状态,生成了不通顺的语句。
不太了解这一块儿的,get 不到其缺点;
还有一个比较大的应用问题,那就是:
teacher forcing在训练阶段可用,预测阶段不可用,显然预测阶段t+1的真实标签是没有的,没法像训练一样t+1的真实标签和hidden state传入t+2,这个时候就需要beam search的帮助了,所以beam search实际上是在预测阶段使用的一种手段,和模型训练无关,并不会参与到模型的参数更新的过程中,类似于一种模型输出的后处理的手段。
之前基础的 seq2seq 版本在输出序列时,仅在每个时刻选择概率 top 1 的单词作为这个时刻的输出单词(相当于局部最优解),然后把这些词串起来得到最终输出序列。实际上就是 贪心策略
但如果使用了 Beam Search,在每个时刻会选择 top K 的单词都作为这个时刻的输出,逐一作为下一时刻的输入参与下一时刻的预测,然后再从这 K*L(L为词表大小)个结果中选 top K 作为下个时刻的输出,以此类推。在最后一个时刻,选 top 1 作为最终输出。有点 带剪枝的动态规划的意思
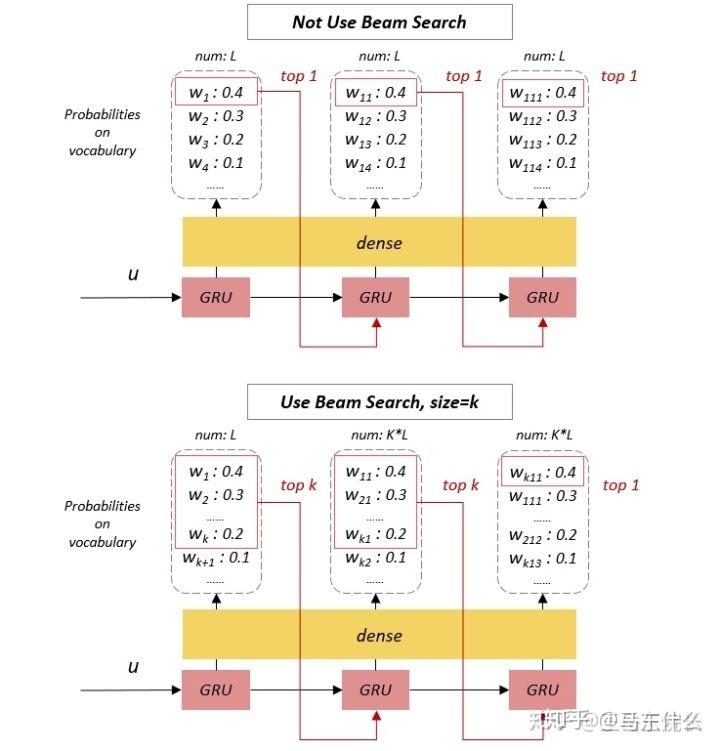
这个其实本质上就是生成多个候选序列,在最后一个时间步输出的时候,所有的候选序列的不同预测时间步的概率累成得到了最终的k个结果,我们取最终累计概率最大的作为输出,具体过程可见这一篇,非常的详细:
AI Starter:如何通俗的理解beam search?zhuanlan.zhihu.com然而有一个主要的问题在于,时间序列预测不存在所谓的topk的概念,因为预测的都是实值,所以无法使用beam search的方式来解决预测的问题,因此,针对于这个问题实际上时间序列预测 of seq2seq 舍弃了beam search的思路,使用了teacher forcing的扩展方法——curriculum learning,对应的采样方法叫做scheduled sampling。
思路也很简单:
https://blog.csdn.net/bobobe/article/details/81297064blog.csdn.net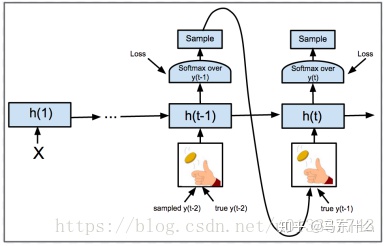
curriculum learning如上图所示,训练时网络将不再完全采用真实序列标记做为下一步的输入,而是以一个概率p选择真实标记,以1-p选择模型自身的输出。“scheduled sampling”即p的大小在训练过程中是变化的,就像学习率一样。作者的思想是:一开始网络训练不充分,那么p尽量选大值,即尽量使用真实标记。然后随着训练的进行,模型训练越来越充分,这时p也要减小,即尽量选择模型自己的输出。这样就尽量使模型训练和预测保持一致。
p随训练次数的变化方式有如下选择:
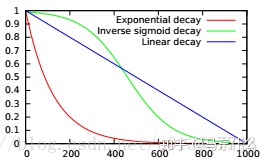
最终的输出仍旧是按照常规的 seq2seq的方式来输出,只不过采用了这样的训练方式可以较好的提高模型的泛化性能。
代码部分,把深度序列模型系列整理完了发几个demo上来。
总的来说,seq2seq的原理并不复杂,复杂一点的是加入attention机制之后可能会有一点难理解,seq2seq+attention也可以并且也已经应用到时间序列的预测上来了,attention的内容打算单独整一块写,这里就不赘述了,配合之前写的seq2seq的一些经典结构:
马东什么:seq2seq by keras 总结zhuanlan.zhihu.comseq2seq的研究差不多就先到这边吧














 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









