







目录
基于yolo11-seg的水果桃子语义分割
1.数据阶段
1.1数据集准备
Peach桃子语义分割数据集,包含2400张图像,标注了10129个实例(果实)。用于水果检测任务,支持目标检测、语义分割和实例分割任务。
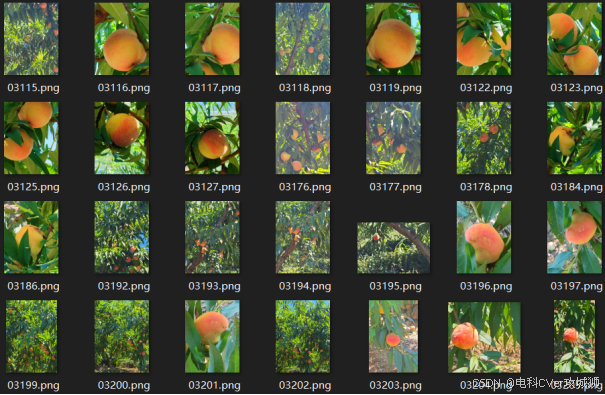
数据集介绍:高质量标注,数据集中的图像由专业人员使用Labelme工具进行标注,确保了标注的准确性和一致性。标注标准要求精确地绘制可见果实的多边形边界,同时排除被遮挡的部分。多样性和挑战性,图像采集于不同的果园区域,涵盖了不同的光照条件、阴影、遮挡情况以及树枝、叶脉等干扰因素,能够有效模拟实际农业场景中的复杂情况,对水果分割模型的鲁棒性提出了较高的要求。类别丰富,数据集仅包含一个类别——桃子(Peach),但涵盖了不同成熟度、大小和形状的桃子实例,有助于模型学习桃子的多样性和变异性。
数据集的多样性和挑战性使得基于该数据集训练的模型能够更好地适应不同的农业场景,从而提高模型的泛化能力,减少对特定果园环境或数据集的依赖。
1.2数据集划分
Peach桃子语义分割数据集,按照7:1:2的比例划分为训练集、验证集、测试集,并组织好yolo算法所需的目录结构。最终,得到yolo格式的语义分割标签,具体目录结构如下:
★其结构如下:
peach_dataset
- images
- - train
- - val
- - test
- labels
- - train
- - val
- - test
【注意:准备好的peach_dataset文件夹,应该与下面的工程项目yolov11_seg位于同级目录,不要将peach_dataset文件夹放置在工程项目里面】
☆可直接获取转换完成的yolo格式数据集(如下图),获取方式见文末
![]()
1.3环境安装
--- 安装指令:pip install ultralytics==8.3.59 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.训练阶段
2.1开始训练
前提条件:cuda、torch、ultralytics版本匹配且可用,使用yolo11-seg m型号预训练模型】
【需要进入工程项目yolov11_seg里面】
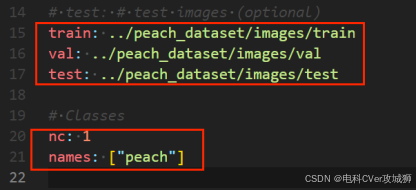
--- 修改数据配置文件./custom.yaml,训练集/验证集路径设定,类别数和类别名称需一致
--- 执行训练命令:python train.py
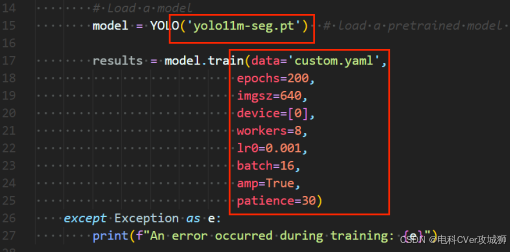
【按需修改train.py文件里的训练参数,例如:windows系统,workers应该设置为0;linux系统,可设置为8】
训练200 epoch后(含有早停机制,150 epochs),模型保存在runs/segment/train/weights文件夹
2.2结果展示
2.2-1、F1_curve.png(F1分数)
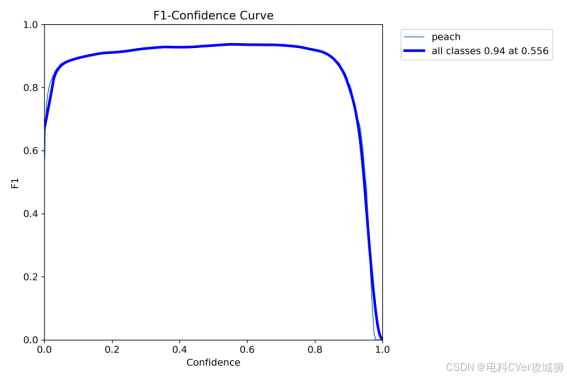
由图可知,当confidence为0.556时,all classes的F1分数为0.94;表示该模型在0.556的置信度预测类时整体表现良好,具有一定的准确性和召回率。
什么是F1分数?F1分数是精确率(Precision)和召回率(Recall)的调和平均值,它同时考虑了模型预测的准确性和覆盖面。
2.2-2、P_curve.png(精确率曲线)
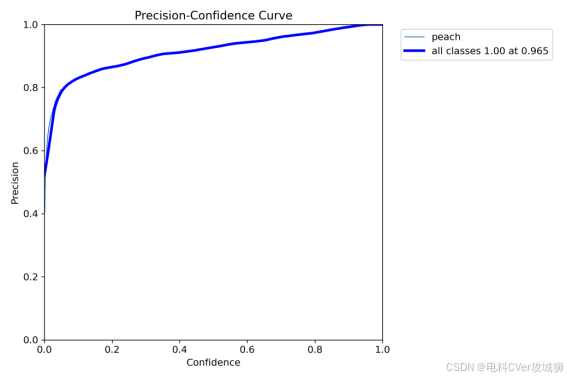
图中的深蓝色折线代表整体的精度,随着置信度的增加,精确度也增加,在置信度为0.965时,精确度达到了1。其余1条线分别表示1个类别在不同的置信度下的精度。
精确率曲线,帮助分析模型在检测任务中的表现,特别是在不同置信度设置下的精确性表现。通过这条曲线,可以选择合适的置信度阈值,以优化模型的检测结果,平衡精确率和召回率。
2.2-3、PR_curve.png(精确率-召回率曲线)
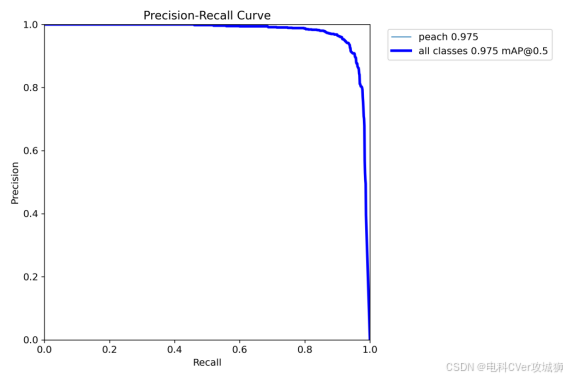
图中的曲线为Precision-Recall Curve(精确度-召回率曲线),展示了不同阈值下分类器的精确度和召回率。具体来说,横轴表示Recall(召回率),范围从0.0到1.0;纵轴表示Precision(精确度),范围从0.0到1.0。图中主要有两条曲线:
(1)彩色线代表1个类别的精确度-召回率曲线,每个类别的精确度各有差异;
(2)深蓝色线代表所有类别的平均精确度-召回率曲线,其精确度也在0.975左右保持稳定。
这两条曲线都显示了随着召回率的增加,精确度略有下降的趋势,但整体上精确度保持在很高的水平。
通过这条曲线,可以评估模型在目标检测任务中的整体性能,并找到合适的置信度阈值,以在精确率和召回率之间做出最佳平衡。PR 曲线越接近右上角,模型性能越好,曲线下方的面积越大,说明模型在不同置信度下的表现越稳定。
2.2-4、R_curve.png(召回率曲线)
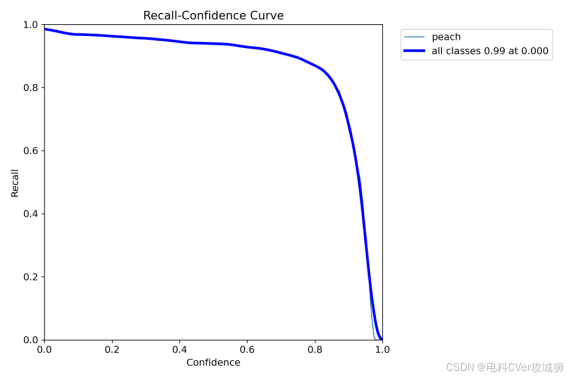
图中的R曲线为Recall-Confidence Curve(召回率-置信度曲线),它展示了不同置信度下的召回率。具体来说,横轴表示置信度,从0.0到1.0;纵轴表示召回率,从0.0到1.0。图中主要有1条曲线:
(1)1条彩色线:代表1个类别的召回率随置信度的变化情况。这条曲线显示了随着置信度的增加,每个类别的召回率先变化较小,然后在某个点之后迅速下降。
(2)深蓝色线:代表所有类别的平均召回率随置信度的变化情况。
展示模型在不同的置信度阈值(confidence thresholds)下的召回率表现。召回率曲线帮助评估模型在目标检测任务中,检测到真正目标的能力。通过这条曲线,用户可以评估模型的检测能力,分析模型在不同阈值下对真实目标的检测是否全面。如果召回率曲线在较低的置信度下表现较好,说明模型可以有效检测大多数目标;如果曲线下降较快,可能需要调整模型或数据集,避免漏检问题。
2.2-5、results.png(结果指标曲线)
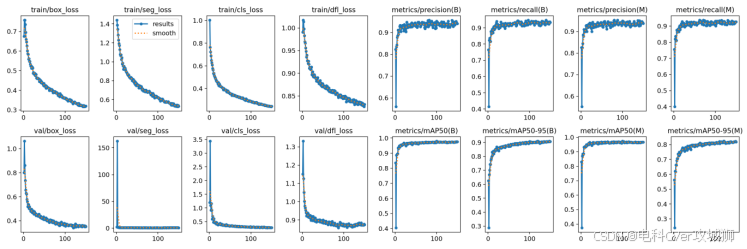
这张图展示了基于 YOLOv11 的分割算法(seg)训练和验证过程中的多个指标变化情况。以下是对每个指标的含义和图中趋势的分析:
训练阶段(第一行)
train/box_loss:
含义: 边界框回归损失,衡量预测框与真实框之间的差距。
趋势: 损失值随着训练迭代次数增加而逐渐下降,表明模型在边界框预测上逐渐优化。
train/seg_loss:
含义: 分割损失,衡量分割掩码(mask)与真实掩码之间的差距。
趋势: 损失值快速下降,表明模型在分割任务上逐渐收敛。
train/cls_loss:
含义: 分类损失,衡量预测类别与真实类别之间的差距。
趋势: 损失值下降,表明模型在分类任务上逐渐优化。
train/dfl_loss:
含义: 分布式焦点损失(Distribution Focal Loss),用于提高边界框回归的精度。
趋势: 损失值下降,表明模型在边界框回归的精度上逐渐优化。
metrics/precision(B):
含义: 精确率(Precision),衡量模型预测的正样本中有多少是真正的正样本(针对边界框任务)。
趋势: 精确率逐渐上升并趋于稳定,表明模型在减少误报方面表现良好。
metrics/recall(B):
含义: 召回率(Recall),衡量模型预测的正样本中有多少是真正的正样本(针对边界框任务)。
趋势: 召回率快速上升并趋于稳定,表明模型在检测到更多真实目标的同时保持了较高的准确率。
metrics/precision(M):
含义: 精确率(Precision),针对分割掩码任务。
趋势: 精确率逐渐上升并趋于稳定,表明模型在分割任务中减少了误报。
metrics/recall(M):
含义: 召回率(Recall),针对分割掩码任务。
趋势: 召回率快速上升并趋于稳定,表明模型在分割任务中能够检测到更多的真实目标。
验证阶段(第二行)
val/box_loss:
含义: 验证集上的边界框回归损失。
趋势: 损失值下降,表明模型在验证集上的边界框预测性能逐渐优化。
val/seg_loss:
含义: 验证集上的分割损失。
趋势: 损失值快速下降,表明模型在验证集上的分割性能逐渐优化。
val/cls_loss:
含义: 验证集上的分类损失。
趋势: 损失值下降,表明模型在验证集上的分类性能逐渐优化。
val/dfl_loss:
含义: 验证集上的分布式焦点损失。
趋势: 损失值下降,表明模型在验证集上的边界框回归精度逐渐优化。
metrics/mAP50(B):
含义: 平均精度(mAP)在 IoU=0.5 时的值,针对边界框任务。
趋势: mAP50 快速上升并趋于稳定,表明模型在边界框任务上的整体检测性能良好。
metrics/mAP50-95(B):
含义: 平均精度(mAP)在 IoU=0.5 到 0.95 时的值,针对边界框任务。
趋势: mAP50-95 逐渐上升并趋于稳定,表明模型在不同 IoU 阈值下的检测性能逐渐优化。
metrics/mAP50(M):
含义: 平均精度(mAP)在 IoU=0.5 时的值,针对分割掩码任务。
趋势: mAP50 快速上升并趋于稳定,表明模型在分割任务上的整体性能良好。
metrics/mAP50-95(M):
含义: 平均精度(mAP)在 IoU=0.5 到 0.95 时的值,针对分割掩码任务。
趋势: mAP50-95 逐渐上升并趋于稳定,表明模型在不同 IoU 阈值下的分割性能逐渐优化。
【总结】
训练阶段:所有损失函数(box_loss、seg_loss、cls_loss、dfl_loss)均呈下降趋势,表明模型在训练过程中逐渐收敛。同时,精确率和召回率逐渐上升并趋于稳定,表明模型的检测和分割性能良好。
3.推理阶段
使用训练好的模型进行预测(输入测试图片文件夹input_test_images):
python detect.py
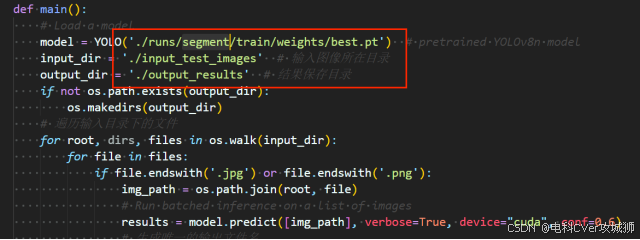
检测完成后,结果保存在output_results文件夹,样例输出如下:

结束语
感谢您的耐心阅读!若文中存在错误,恳请指出,我会努力改进。若您有更优方法,也请不吝分享,让我们共同进步!
【⭐⭐⭐免费获取yolo格式的peach语义分割数据集,请阅读:


















 7569
7569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











