







1.什么是K-近邻算法
举个🌰:某天小白来到杭州,但是他不知道自己当前所处的位置。于是就打电话问小猫、小狗等朋友,他们在哪个区域,距离自己有多远。假设小白打电话问了3个朋友,距离小白最近的3个朋友里有2个位于萧山区,那小白就认为自己也处于萧山区。

思想: 根据最近的距离来判断自己当前属于哪个类别,最近的那个类别属于什么类别,则认为自己也属于那个类别。
定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最近邻)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
由此产生一个问题:距离究竟该如何计算呢?
距离公式:

(1)欧式距离:即使用勾股定理求解两点或多点间的距离。

(2)曼哈顿距离:在地图中两点之间的距离往往不是直线距离。
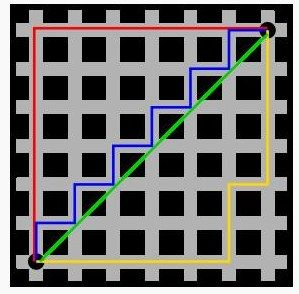
如图所示,每种颜色的线段所对应的路径,其最终距离都是相同的。这一点用平移的思想就很容易理解了。

(3)切比雪夫距离:在国际象棋的棋盘上,国王有8个方位可以走,但每次只能移动1个单位的距离。假设国王从(A,1)出发,前往(C,5)。从A到C横坐标需要移动2个单位的距离,从1到5纵坐标需要移动4个单位的距离,而从(A,1)到(C,5)路径可以是(B,2)->(C,3)->(C,4)->(C,5),共计4个单位的距离。

经过分析与推算,最终得出切比雪夫距离。即为两点间横坐标/纵坐标差值。(取两者中较大的那个值)
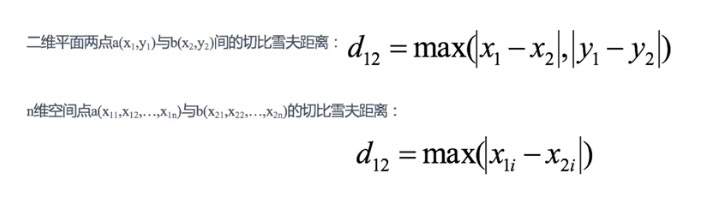
(4)闵可夫斯基距离:并非一种距离,而是对一组距离的定义。
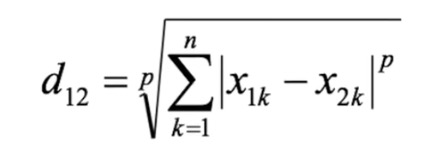
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p->∞时,就是切比雪夫距离。
小结:
i. 以上四种距离都存在明显的缺陷。如现有三个样本:a(180,50),b(190,50),c(180,60)。其中第一个值代表身高(单位:cm),第二个值代表体重(单位:kg)。a与b的闵式距离=a与c的闵式距离。但是身高与体重并不能划等号。
ii. 未考虑各个分量的分布(期望、方差等)可能是不相同的。
(5)标准化欧式距离:针对欧式距离的改进。将各个分量都标准化到均值、方差相等。
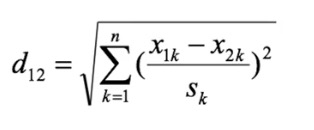
(6)余弦距离:几何中,夹角余弦可以用来衡量两个向量方向之间的差异;机器学习中,可以用来衡量两个样本之间的差异。如图所示,在二维空间中两个向量之间的夹角余弦公式:
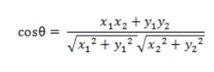
2.K-近邻算法的应用
| 序号 | 电影名称 | 搞笑镜头 | 拥抱镜头 | 打斗镜头 | 影片类型 |
|---|---|---|---|---|---|
| 1 | 功夫熊猫 | 39 | 0 | 31 | 喜剧片 |
| 2 | 叶问3 | 3 | 2 | 65 | 动作片 |
| 3 | 二次曝光 | 2 | 3 | 55 | 爱情片 |
| 4 | 代理情人 | 9 | 38 | 2 | 爱情片 |
| 5 | 新步步惊心 | 8 | 34 | 17 | 爱情片 |
| 6 | 谍影重重 | 5 | 2 | 57 | 动作片 |
| 7 | 美人鱼 | 21 | 17 | 5 | 喜剧片 |
| 8 | 宝贝当家 | 45 | 2 | 9 | 喜剧片 |
| 9 | 唐人街探案 | 23 | 3 | 17 | ? |
思路: 想要推算「唐人街探案」属于什么类型的影片,就可以使用K-近邻算法。这里使用三维空间点的欧式距离法则,分别计算该电影与其他电影的的距离,结果如下:
| 序号 | 电影名称 | 影片类型 | 距离 |
|---|---|---|---|
| 1 | 功夫熊猫 | 喜剧片 | 21.47 |
| 2 | 叶问3 | 动作片 | 52.01 |
| 3 | 二次曝光 | 爱情片 | 43.42 |
| 4 | 代理情人 | 爱情片 | 40.57 |
| 5 | 新步步惊心 | 爱情片 | 34.44 |
| 6 | 谍影重重 | 动作片 | 43.87 |
| 7 | 美人鱼 | 喜剧片 | 18.55 |
| 8 | 宝贝当家 | 喜剧片 | 23.43 |
| 9 | 唐人街探案 | — | — |
将距离从小到大排序。若k=1,只取最近的一个样本,对应的18.55「美人鱼」影片属于喜剧片,因此判断「唐人街探案」也属于喜剧片。若k=5,取最近的5个样本时,其中有3部电影:「美人鱼」、「功夫熊猫」、「宝贝当家」属于喜剧片,距离分别为18.55、21.47、23.43,2部电影:「新步步惊心」、「代理情人」属于爱情片,距离分别为34.44、40.57。3>2,根究大多数原则,认为「唐人街探案」属于喜剧片。
问题:
i. 选择较小的k值,容易受到异常点的影响,如k=1时,距离最近的「美人鱼」影片统计错误,则导致预测的影片结果也发生异常。
ii. 选择较大的k值,容易受到样本均衡的问题。如k取6时,就会发现有3部电影属于喜剧片,3部电影属于爱情片。从而导致结果难以判断。
解决方案:
i. 在实际过程中,K一般取一个比较小的数值,会采用交叉验证法(将数据分为训练集和验证集)来选取最优的K值,这个会在后续过程中涉及哦~
3.K-近邻算法流程总结
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按距离递增次序排列
(3)选取与当前点距离最小的k个点
(4)统计前k个点所在的类别出现的频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
4.K-近邻算法简单实现
以预测「唐人街探案」属于什么类型的影片为例:
# 1.导入模块
from sklearn.neighbors import KNeighborsClassifier
# 2.构造数据
x = [[39,0,31],[3,2,65],[2,3,55],[9,38,2],[8,34,17],[5,2,57],[21,17,5],[45,2,9]]
y = ["喜剧片","动作片","爱情片","爱情片","爱情片","动作片","喜剧片","喜剧片"]
# 3.训练模型
# 3.1 实例化一个估计器对象
estimator = KNeighborsClassifier(n_neighbors=2)
# 3.2 调用fit方法,进行训练
estimator.fit(x,y)
# 4.数据预测
res = estimator.predict([[23,3,17]])
print(res)















 2467
2467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









