






1、背景:
1.1 关于kaggle:
谷歌旗下的 Kaggle 是一个数据建模和数据分析竞赛平台。该平台是当下最流行的数据科研赛事平台,其组织的赛事受到全球数据科学爱好者追捧。 如果学生能够在该平台的一些比赛中获得较好的名次,不仅可以赢得大量的奖金,还可以收获 Google 、 Amazon 等知名互联网公司的面试邀请。
1.2 关于泰坦尼克灾难(Titanic: Machine Learning from Disaster)
以下是关于泰坦尼克生存预测的说明,在‘data’处可以点击下载预测数据。
1.3泰坦尼克问题的背景:
- 这是一个大家都非常熟悉的故事,泰坦尼克号邮轮航行途中不行撞击冰山,导致船翻了,在救援的过程中,船长的要求是女士与小孩优先上游艇,所以最终是否存活并不是随机事件,而是有一定的决定因素的。
- 训练和测试数据是一些乘客的个人信息以及存货状况,要尝试根据它生成合适的模型并预测其他人的生存状况
- 这是一个二分类的问题,在监督模型中,逻辑回归,支持向量机,决策树,随机森林,KNN等算法都够进行处理,本篇文章中,主要内容还是处理数据构建特征,对于模型的选择与调优将放到后续的文章中。
2、 怎么做?
- 手把手教程马上就来,先来两条我看到的,觉得很重要的经验:
- 印象中Andrew Ng老师似乎在coursera上说过,应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
- Kaggle上的大神们,也分享过一些experience,说几条我记得的哈:
- 对数据的认识太重要了!
- 数据中的特殊点/离群点的分析和处理太重要了!
- 特征工程(feature engineering)太重要了!在很多Kaggle的场景下,甚至比model本身还要重要
- 要做模型融合(model ensemble)
3、初步的数据认知
官方提供的数据文件一共有三个,一个是带标签的训练数据,一个是不带标签的预测数据,第三个是结果的提交格式。下面就将训练数据与预测数据都读进来,并合并查看。在这多说一句,将训练数据与预测数据合并进行统一的清洗,可以减少许多的重复性工作
import pandas as pdimport matplotlib.pyplot as pltimport numpy as nptrain=pd.read_excel(r'E:huawei我的作品泰坦尼数据rain.xlsx')test=pd.read_excel(r'E:huawei我的作品泰坦尼数据est.xlsx')data=pd.concat([train,test]) #将训练数据与预测数据进行合并data_1=data.copy()如下图为数据结果:
Age,Fare,Parch,Pclass,SibSp等字段为数值型数据,Cabin,Embarked,Name,Sex,Ticket等字段为字符型数据
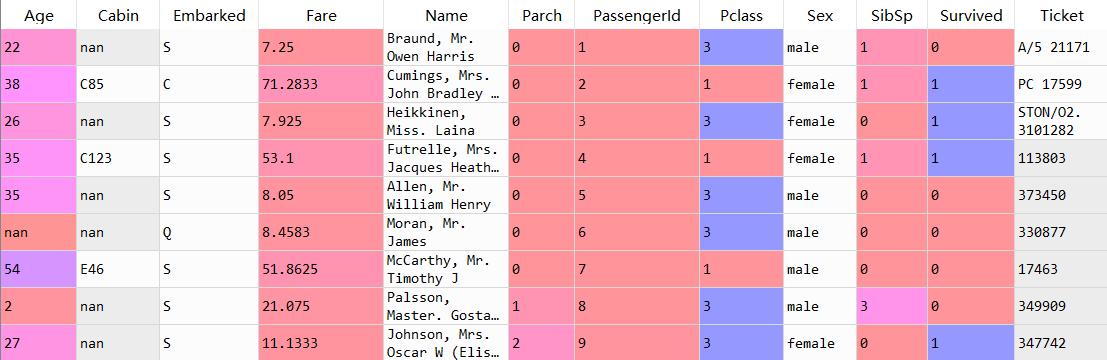
对数据进行初步的了解
data_describe=data_1.describe() #查看数值型数据的统计指标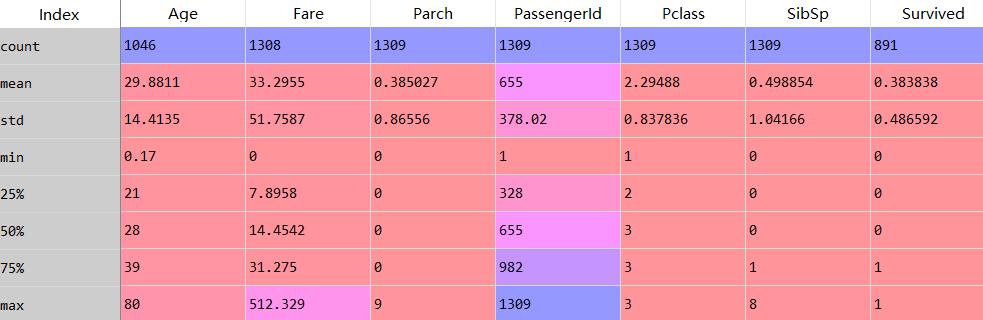
从上边的数据我们可以得到什么样的结论呢
- 乘客的平均年龄是29岁
- 平均票价是33.9,最高票价是512
- 二等舱、三等舱要比一等舱的乘客多很多
- 约有38.3%的乘客获救了
- 以上计算都忽略掉缺失值
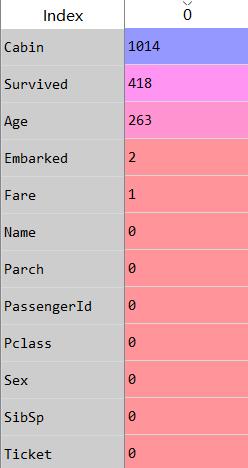
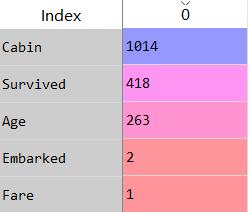
各字段缺失情况如下
data_null=data_1.isnull().sum() #查看缺失值 初步假设:
- Cabin字段的缺失值最多,将近80%的记录都为空,假设缺失值有实际意义,在处理时将空值作为新的一类
- Age字段缺失值占比20%,也不能建单的通过平均值/中位数/众数来填充,填充的方法可以采用对不同乘客属性的中位数进行填充。
- Embarked与Fare的缺失值较少,简单的中位数/平均数填充即ok
乘客的各属性分布以及与获救结果的关联统计
分别查看性别,仓位等级,上船港口以及仓位编号与是否生存的关系
fig=plt.figure(figsize=(15,10))###Sex与Survived关系axes_1=fig.add_subplot(2,2,1)sur_sex=pd.pivot_table(train,index='Survived',columns='Sex',values='PassengerId',aggfunc='count')sur_sex.plot(kind='bar',stacked=True,ax=axes_1)plt.title('Sex-Survived')##pclass与是否存活svi_p=pd.pivot_table(train,index='Survived',columns='Pclass',values='PassengerId',aggfunc='count')axes_2=fig.add_subplot(2,2,2)svi_p.plot(kind='bar',stacked=True,ax=axes_2)plt.title('Pclass-Survived')###embarked与是否存活axes_3=fig.add_subplot(2,2,3)sur_emb=pd.pivot_table(train,index='Survived',columns='Embarked',values='PassengerId',aggfunc='count')sur_emb.plot(kind='bar',stacked=True,ax=axes_3)plt.title('Embarked-Survived')##cabin与survived关系axes_6=fig.add_subplot(2,2,4)train['Cabin'].fillna('N',inplace=True)train['Cabin_c']=train['Cabin'].map(lambda x : x[0])sur_ca=pd.pivot_table(train,index='Survived',columns='Cabin_c',values='PassengerId',aggfunc='count')sur_ca.T.plot(kind='bar',stacked=True,ax=axes_6)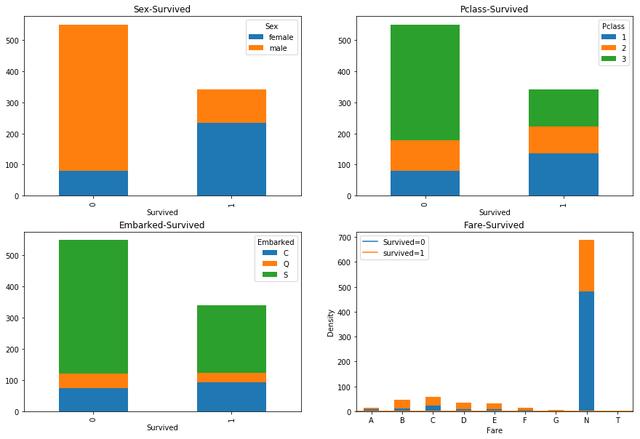
结论:
- 图一,性别与生存的有着强关系,在生存的乘客中,女性的比例明显要高很多。
- 图二,仓位等级与生存有着强关系,一等舱的乘客生存的概率明显要高很多。
- 图三、登录港口与生存有着一定的关系,并不是很明显,在生存的乘客中,C港口登录的乘客要多一些。
- 图四、A~G的仓位中,生存的概率是差不多的,而N仓的生存率明显会低很多。
年龄与船票价格的的概率密度曲线
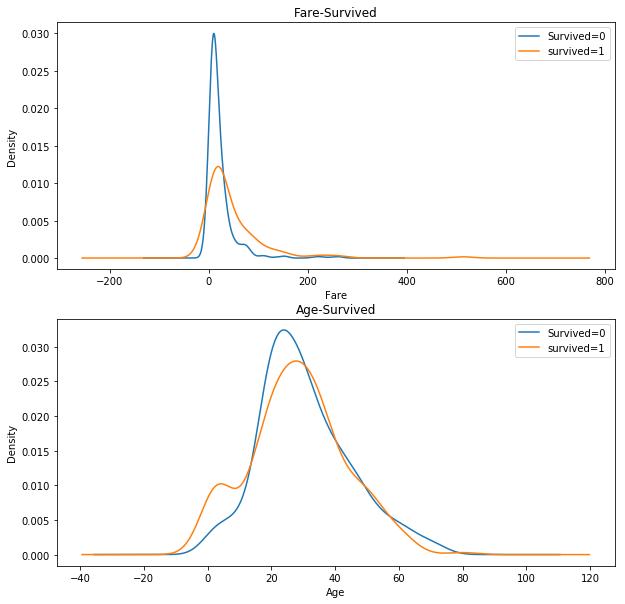
结论:
- 图一、死亡的乘客中低Fare的比例明显要比生存的乘客比例高
- 图二、死亡的乘客中20-30岁的比例要比生存的乘客高,在0-10岁的乘客明显生存概率要高一些
4、缺失值填充
除去要预测的Survived字段,一共有四个字段有缺失值,下边将按照缺失值从少到多的顺序来填充
4.1 Fare字段的缺失值填充
Fare只有一个记录的缺失值

Fare的整体分布:Fare主要分布在100以下,如果用全局平均数或中位数填充,受高于100值的影响会比较大,所以我们看一下,能不能从其他的字段中找出一点相关性
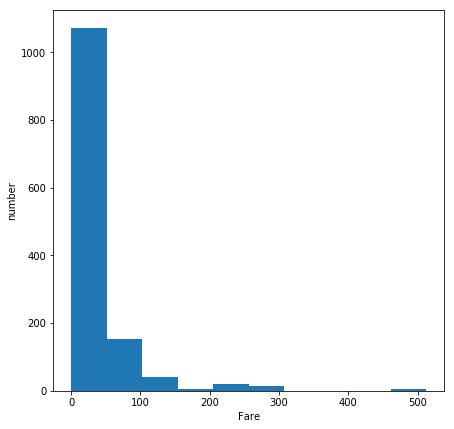
在这一条记录中,Cabin的字段是缺失的,Pclass的字段是有的,那么先用Pclass=3的Fare的中位数填充
data_fare=pd.pivot_table(data_1,index='Pclass',values='Fare',aggfunc='median')data_1['Fare'].fillna(data_fare.loc[3,'fare'],inplace=True)4.2 填充Embarked的缺失值
在Embarked-Survived的图中可以看出,相比未生存下来的人,生存者中C港口登录的占比要高很多,同时,缺失的这两条记录都是生存者,那么久很简单了额,直接用C来填充缺失值

data_1['Embarked'].fillna('C',inplace=True) 4.3 最简单的两个缺失值填充已经完成了,下面要来填充年龄的缺失值了
由于年龄的缺失值相对较多,也不能直接使用全局均值/平均数来填充,跟Fare字段的填充逻辑一致,先在现有数据中寻找与Age相关的字段,在现有字段中与年龄最相关的就是Name中的title了,先在决定使用不同title对应的年龄的中位数进行填充
由下图的Title-Age的密度曲线可以看出,除了‘Miss’外,其他的各个title的年龄密度曲线都比较集中,将‘Miss’中Parch是否大于零划分为两类,继续观察密度曲线,如右图。现在来看Miss的年龄目睹曲线将会平滑一些。
##Age字段缺失值填充def name(x): #先对Name字段进行处理,构造解析title函数 str_1=x.split(',')[1] str_2=str_1.split('.')[0] str_3=str_2.strip() return str_3data_1['title']=data_1['Name'].map(lambda x: name(x))fig=plt.figure(figsize=(15,7))axes=fig.add_subplot(1,2,1)data_1.loc[data_1['title']=='Mr','Age'].plot(kind='kde',ax=axes)data_1.loc[data_1['title']=='Miss','Age'].plot(kind='kde',ax=axes)data_1.loc[data_1['title']=='Mrs','Age'].plot(kind='kde',ax=axes)data_1.loc[data_1['title']=='Master','Age'].plot(kind='kde',ax=axes)data_1.loc[data_1['title']=='Dr','Age'].plot(kind='kde',ax=axes)plt.legend(('Mr','Miss','Mrs','Master','Dr'),loc='best')plt.title('Title-Age')plt.xlabel('Age')axes_2=fig.add_subplot(1,2,2)data_1.loc[(data_1['title']=='Miss')&(data_1['Parch']>0),'Age'].plot(kind='kde',ax=axes_2)data_1.loc[(data_1['title']=='Miss')&(data_1['Parch']==0),'Age'].plot(kind='kde',ax=axes_2)plt.legend(('Parch>0','Parch=0'))plt.title('Miss/Parch-Age')plt.xlabel('Age')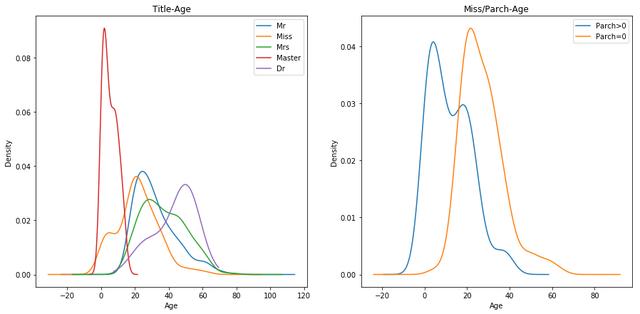
#先输出除去'Miss'字段的各Title的年龄中位数data_age=pd.pivot_table(data_1,index='title',values='Age',aggfunc='median')data_age.drop(['Miss'],axis=0,inplace=True)title_sex=data_age.to_dict()['Age']data_1.set_index('title',inplace=True)data_1['Age'].fillna(title_sex,inplace=True)data_1.reset_index(inplace=True)##对miss中age的缺失值进行填充data_1['Parch>0']=0data_1.loc[(data_1['title']=='Miss')&(data_1['Parch']>0),'Parch>0']=1miss_age=pd.pivot_table(data_1.loc[data_1['title']=='Miss'],index='title',values='Age',columns='Parch>0',aggfunc='median')data_1.loc[(data_1['title']=='Miss')&(data_1['Parch']>0)]=9.5data_1['Age'].fillna(25.5,inplace=True)Miss分Parch是否大于零的Age的中位数分别为25.5与9.5

4.4 现在对最后一个缺失值Cabin进行填充
Cabin的数据比较特殊,字符类型,分类也比较多,经观察,仓位的首字母是可以提取出来作为特征使用的。Cabin空值较多,用N来代替空值,空值的产生应该是这一部分人本身就没有仓位导致的。
data_1['Cabin'].fillna('N',inplace=True)data_1['cabin_1']=data_1['Cabin'].map(lambda x : x[0])cabin_s=pd.pivot_table(data_1,index='cabin_1',columns='Survived',values='PassengerId',aggfunc='count')cabin_s['存活率']=cabin_s[1.0]/(cabin_s[0.0]+cabin_s[1.0])data_1['cabin_1'].replace({'G':'A','F':'C','E':'B','D':'B','T':'N'},inplace=True)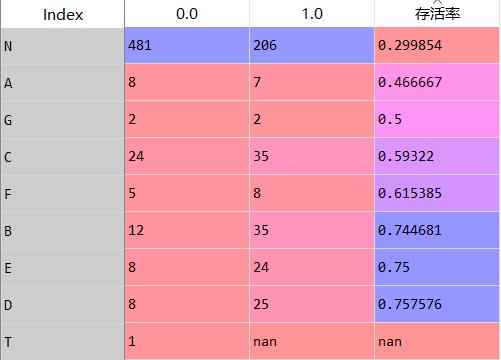
仓位的分类有点过多,且各仓位的存活率是有相似性的,将A,G仓归为A类,C,F仓归为C类,将B,E,D仓归为B类,T仓归为N类。其中归为N类的记录有点多,看看能不能再优化一下。下面看一下各仓位类型和Fare的密度曲线。
fig=plt.figure(figsize=(8,8))axes=fig.add_subplot(1,1,1)data_1.loc[data_1['cabin_1']=='A','Fare'].plot(kind='kde',ax=axes)data_1.loc[data_1['cabin_1']=='B','Fare'].plot(kind='kde',ax=axes)data_1.loc[data_1['cabin_1']=='C','Fare'].plot(kind='kde',ax=axes)data_1.loc[data_1['cabin_1']=='N','Fare'].plot(kind='kde',ax=axes)plt.legend(('A','B','C','N'),loc='best')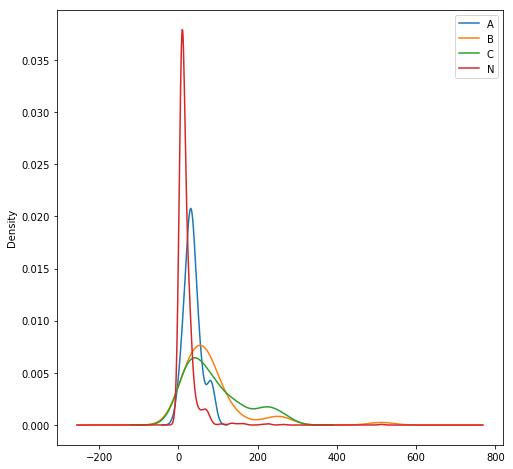
通过曲线可以看出,填充的N仓是有一部分凸起的,且部分高价票的乘客也是N仓的,现在将N仓中Fare>240的改为B仓,Fare>80的改为C仓。
data_1.loc[(data_1['cabin_1']=='N')&(data_1['Fare']>240),'cabin_1']='B'data_1.loc[(data_1['cabin_1']=='N')&(data_1['Fare']>80),'cabin_1']='B'优化后的曲线

5、构造新特征
以上已经将各变量的缺失值填充完毕,现在就来到了最考验创造力的时刻:构造新特征。在上文中,我们还有几个变量没有用到:Name,Parch,SibSp等字段。
5.1Name字段清洗
思路:现有title分类过多,对title进行分类,聚类的规则就是按照title的实际意义进行分类,分类规则如下:
title_dict={'Mlle':'Miss','Ms':'Mrs','Dr':'Officer','Dona':'Royalty', 'Lady':'Royalty','Mme':'Mrs','the Countess':'Royalty', 'Rev':'Officer','Col':'Officer','Major':'Officer','Capt':'Officer', 'Don':'Royalty','Jonkheer':'Royalty','Sir':'Royalty'}data_1['title'].replace(title_dict,inplace=True)5.2 Parch与SibSp字段的清洗
data_1['family_size']=data_1['Parch']+data_1['SibSp']+1data_1['family_size'].value_counts()def f_size(x): if x==1: a='single' elif x<=3 and x>=2: a='small' elif x<=6: a='media' else: a='large' return adata_1['family_size_']=data_1['family_size'].map(lambda x :f_size(x))5.3 构造‘儿童’与‘母亲’字段
将年龄<12的作为儿童,将title=Mrs,parch>1的作为母亲
data_1['child']=0data_1.loc[data_1['Age']<12,'child']=1data_1['mother']=0data_1.loc[(data_1['Parch']>1)&(data_1['title']=='Mrs'),'mother']=15.4 构造高票价的字段
将Fare大于高于200的构造一个新字段
data_1['high_fare']=0data_1.loc[data_1['Fare']>200,'high_fare']=16 特征已经构造完了,最后一步需要将one-hot编码了
finall_df=data_1[['PassengerId','Survived','Age','Fare','family_size','child', 'mother','high_fare']].copy()title_df=pd.get_dummies(data_1['title'],prefix='title')embarked_df=pd.get_dummies(data_1['Embarked'],prefix='Embarked')pclass_df=pd.get_dummies(data_1['Pclass'],prefix='pclass')sex_df=pd.get_dummies(data_1['Sex'],prefix='sex')cabin_df=pd.get_dummies(data_1['cabin_1'],prefix='cabin')family_df=pd.get_dummies(data_1['family_size_'],prefix='family')finall_df=pd.concat([finall_df,title_df,embarked_df,pclass_df,sex_df,cabin_df,family_df],axis=1)7 数据基本已经清洗完了,还有最后一步,数值型数据的规范化
在选择分类器的时候会有一部分分类器是基于距离的,所以数值型数据需要进行标准化,一方面能够加快收敛的速度,另一方面在计算距离的避免不同量纲带来的距离不统一的问题
在此对‘Age’,‘Family_size’采用最大最小化归一,由于Fare的值分布不均匀,采用z-score规范化
finall_df['Age']=(finall_df['Age']-finall_df['Age'].min())/(finall_df['Age'].max()-finall_df['Age'].min())finall_df['family_size']=(finall_df['family_size']-finall_df['family_size'].min())/(finall_df['family_size'].max()-finall_df['family_size'].min())x_=finall_df['Fare'].max()finall_df['Fare']=finall_df['Fare'].map(lambda x: math.log(x+1,10)/math.log(x_,10))finall_df['cabin']=finall_df['cabin_n']/finall_df['cabin_n'].max()














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









