








今天我们来学习热图的制作
导入数据
library(pheatmap)
TEST=read.csv("TEST.csv",sep = ',',header = T,row.names=1)绘制默认热图
pheatmap(TEST)
归一化
我们的示例数据基因差异很明显,而且没有离群值,当有一个极大值的时候,就不会有这样的效果,比如
TEST1=TEST
TEST1[1,20]<-1000
pheatmap(TEST1)
这样完全看不出差异了,所以这个时候需要对数据进行标准化
#scale = "row"参数对行进行归一化
#clustering_method参数设定不同聚类方法,默认为"complete",可以设定为
#'ward', 'ward.D', 'ward.D2', 'single', 'complete', 'average', 'mcquitty', 'median' or 'centroid'
pheatmap(TEST1,scale = "row")#按照行进行均一化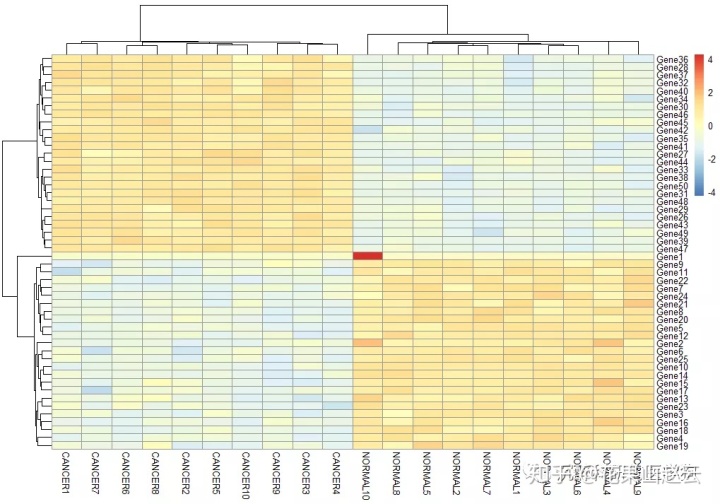
这样就可以看清基因表达之间的差异了
聚类
pheatmap(TEST1,scale = "row",clustering_distance_row 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5413
5413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









