





实例:随机森林模型在分类与回归分析中的应用(昆虫学)
【来源文献:李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(04):1190-1197.】
随机森林可以用于 分类和回归。当因变量 Y是分类变量时,是 分类; 当因变量 Y 是连续变量时,是 回归。自变量 X 可以是多个连续变量和多个分类变量的混合。在本文 3 个案例中, 判别分析和对有无数据的分析是分类问题, 对连续变量 Y的解释是回归问题。1 背景
随机森林( random forest)模型是由Breiman和Cutler在2001年提出的一种基于分类树的算法。它通过对大量分类树的汇总提高了模型的预测精度,是取代神经网络等传统机器学习方法的新的模型。随机森林的运算速度很快,在处理大数据时表现优异。 随机森林不需要顾虑一般回归分析面临的多元共线性的问题,不用做变量选择。现有的随机森林软件包给出了所有变量的重要性。另外, 随机森林便于计算变量的非线性作用,而且可以体现变量间的交互作用( interaction)。 它对离群值也不敏感。 2 目的:本文通过3个案例,分别介绍了随机森林在昆虫种类的 判别分析、有无数据的分析(取代逻辑斯蒂回归) 和回归分析上的应用。案例的数据格式和R语言代码可为研究随机森林在分类与回归分析中的应用提供参考。 3 具体实例: 3.1 实例一:在判别分析中的应用 判别分析( discriminant analysis)是在因变量Y的几个分类水平明确的条件下,根据若干自变量判别每个观测值的类型归属问题的一种多变量统计分析方法。判别与分类在统计学概念上有所交叉,在本文中不强调两者的区别。案例 1 中有 3种昆虫( A、B 和 C) 形态接近,不过可以通过4个长度指标( L1、L2、L3 和 L4) 进行种类的识别。 具体数据格式如表 1: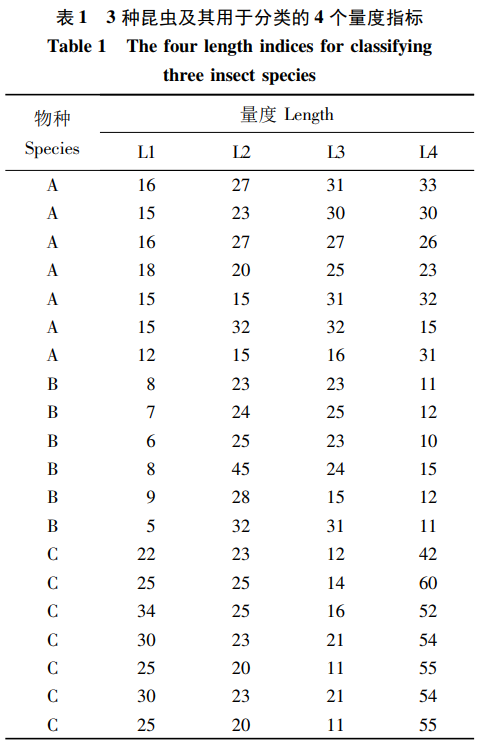
R代码实现:
①建模过程

②用新的数据进行检验

R代码实现:
①建模

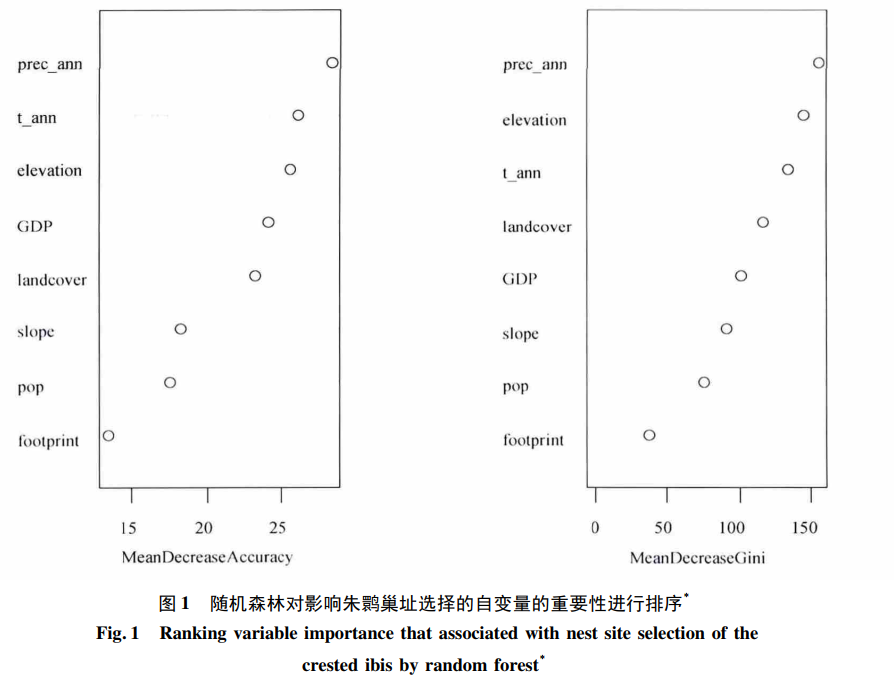
运行结果:
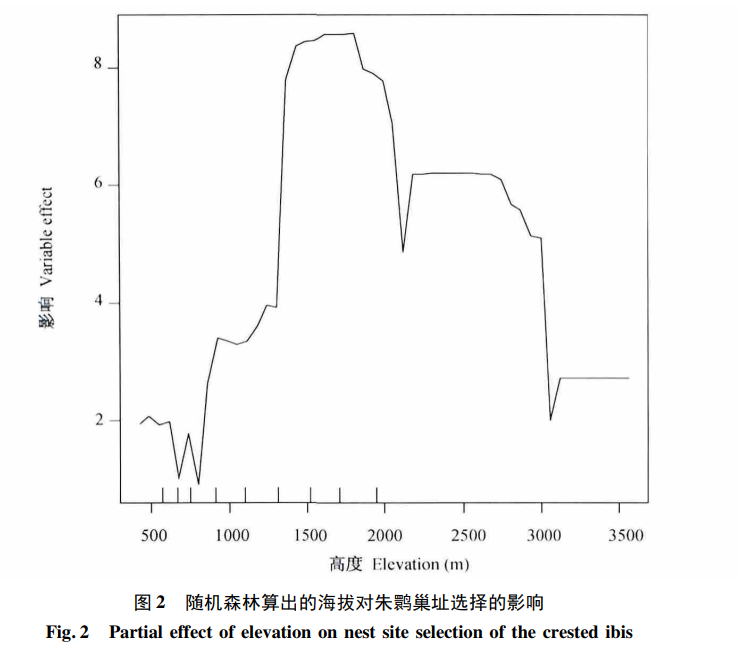
②随机森林可以给出每个自变量对因变量的作用。下列R代码给出海拔对巢址选择的影响, 结果在图 2 中, 表示中等程度的海拔最适宜营巢。

运行结果:
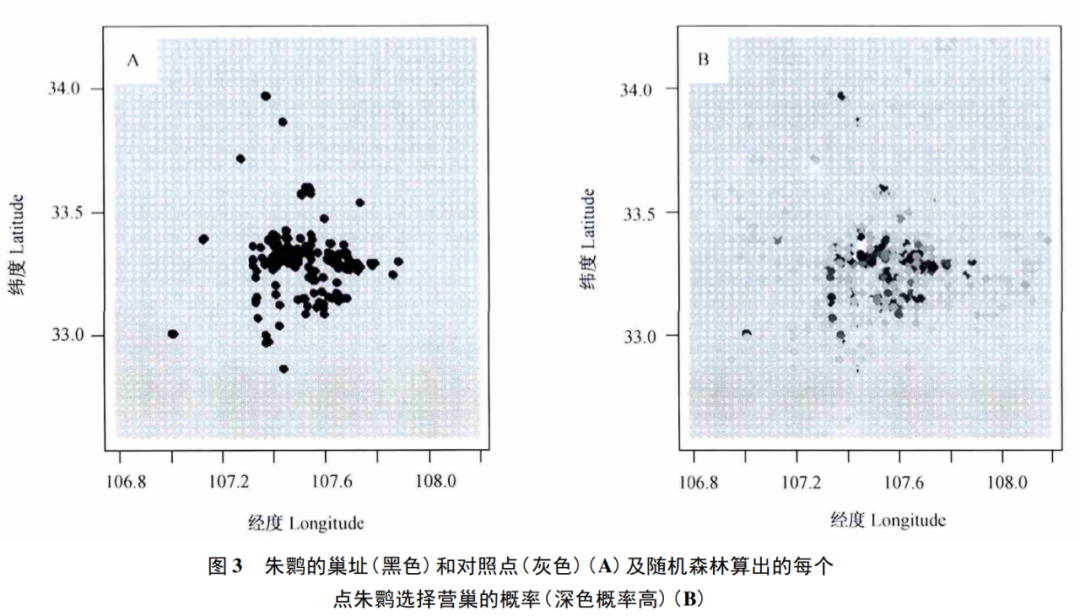
③随机森林可以通过下列代码预测任何地点朱鹮营巢的概率(图3)

运行结果:
R代码实现:
①导入数据

运行结果:
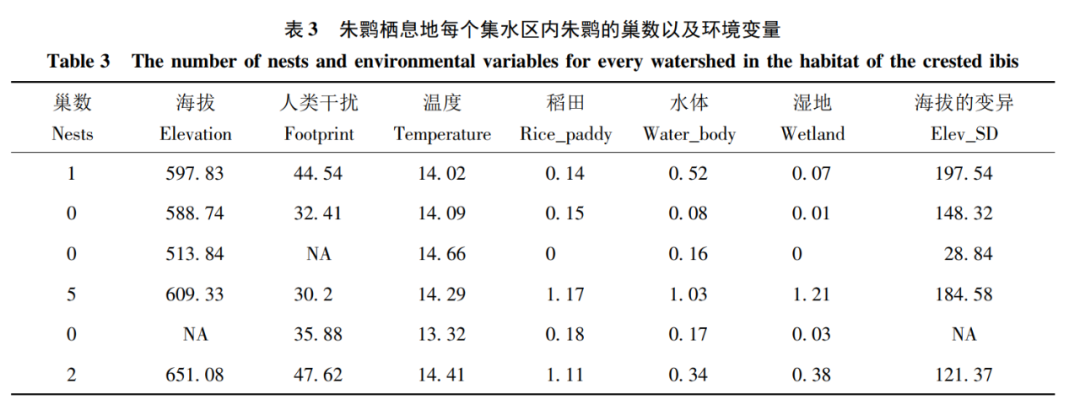
②对于缺失数据,R语言的 randomForest 软件包通过na.roughfix函数用中位数(对于连续变量)或众数(对于分类变量)来进行替换。

运行结果:
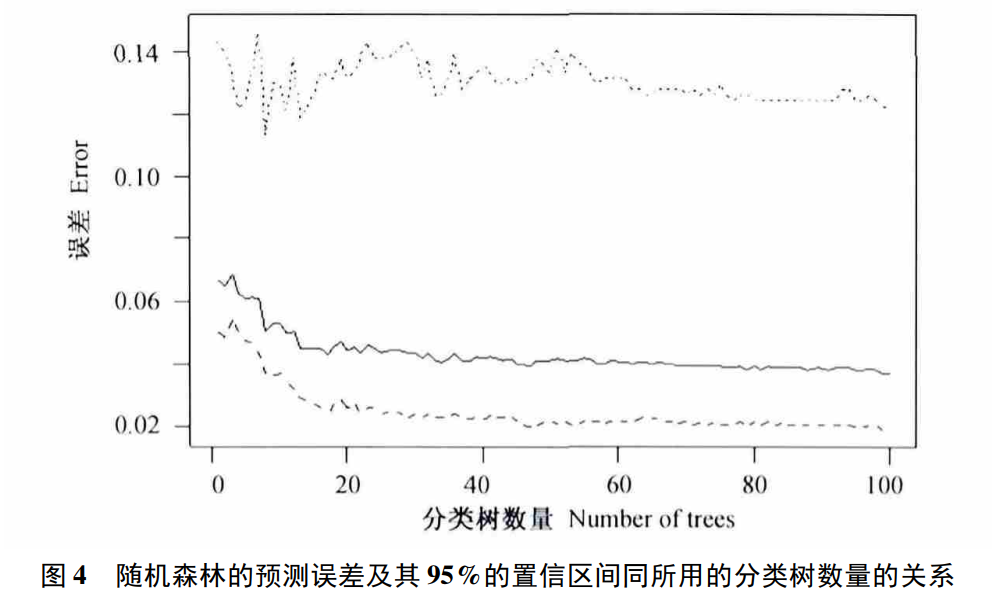
4 总结
本文中随机森林的优点:随机森林结构比较复杂,然而它却极端易用,需要的假设条件(如变量的独立性、正态性等) 比逻辑斯蒂回归等模型要少得多;它也不需要检查变量的交互作用和非线性作用是否显著;使用者可以调节mtry的取值来检查模型的缺省值是否给出误差最小的结果;目前,人们已经对多种机器学习的模型进行了比较,随机森林经常独占鳌头;它包含估计缺失值的算法,如果有一部分的资料遗失,仍可以维持一定的准确度;随机森林中分类树的算法自然地包括了变量的交互作用;随机森林对离群值不敏感;随机森林通过袋外误差( out-of-bag error) 估计模型的误差,对于分类问题,误差是分类的错误率;对于回归问题,误差是残差的方差,所以随机森林不需要另外预留部分数据做交叉验证。 本文中随机森林的缺点是它的算法倾向于观测值较多的类别(如果昆虫B的记录较多,而且昆虫A、B和C间的差距不大,预测值会倾向于B,所以最好选数据时保证两类的平衡,可以利用过采样或欠采样方法平衡)。另外,随机森林中水平较多的分类属性的自变量(如土地利用类型>20个类别)比水平较少的分类属性的自变量(气候区类型<10 个类别)对模型的影响大。总之,随机森林功能强大而又简单易用,相信它会对各行各业的数据分析产生积极的推动作用。













 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









