







 本文介绍了神经网络中的全连接层,包括其线性部分和非线性部分,通过实例解释了全连接层如何从不同角度分析输入数据并进行非线性转换,探讨了多层神经网络的必要性和非线性函数的作用。
本文介绍了神经网络中的全连接层,包括其线性部分和非线性部分,通过实例解释了全连接层如何从不同角度分析输入数据并进行非线性转换,探讨了多层神经网络的必要性和非线性函数的作用。

接下来聊一聊现在大热的神经网络。最近这几年深度学习发展十分迅速,感觉已经占据了整个机器学习的“半壁江山”。各大会议也是被深度学习占据,引领了一波潮流。深度学习中目前最火热的两大类是卷积神经网络(CNN)和递归神经网络(RNN),就从这两个模型开始聊起。
当然,这两个模型所涉及到概念内容实在太多,要写的东西也比较多,所以为了能把事情讲得更清楚,这里从一些基本概念聊起,大神们不要觉得无聊啊……
今天扯的是全连接层,也是神经网络中的重要组成部分。关于神经网络是怎么发明出来的这里就不说了。全连接层一般由两个部分组成,为了后面的公式能够更加清楚的表述,以下的变量名中上标表示所在的层,下标表示一个向量或矩阵内的行列号:
线性部分:主要做线性转换,输入用X表示,输出用Z表示
非线性部分:那当然是做非线性变换了,输入用线性部分的输出Z表示,输出用X表示。

线性部分

线性部分做了什么事情呢?简单来说就是对输入数据做不同角度的分析,得出该角度下对整体输入数据的判断。
这么说有点抽象,举一个实际点的例子,就拿CNN的入门case——MNIST举例。MNIST的例子在此不多说了,它是一个手写数字的识别项目,输入是一张28*28的二值图,输出是0-9这是个数字,这里假设我们采用完全全连接的模型,那么我们的输入就是28*28=784个像素点。数据显示到屏幕上大概是这个样子:
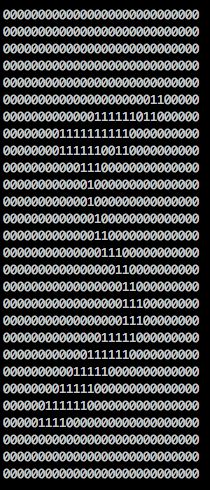
对于我们来说,这个像素点都太过于抽象了,我们无法判断这些像素点的取值和最终识别的关系:
他们是正相关还是负相关?
很显然,像素点之间是存在相关关系的,这个关系具体是什么我们后面再说,但存在关系这件事是板上钉钉的。所以只给每一个像素点一个权重是解决不了问题的,我们需要多组权重。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









