







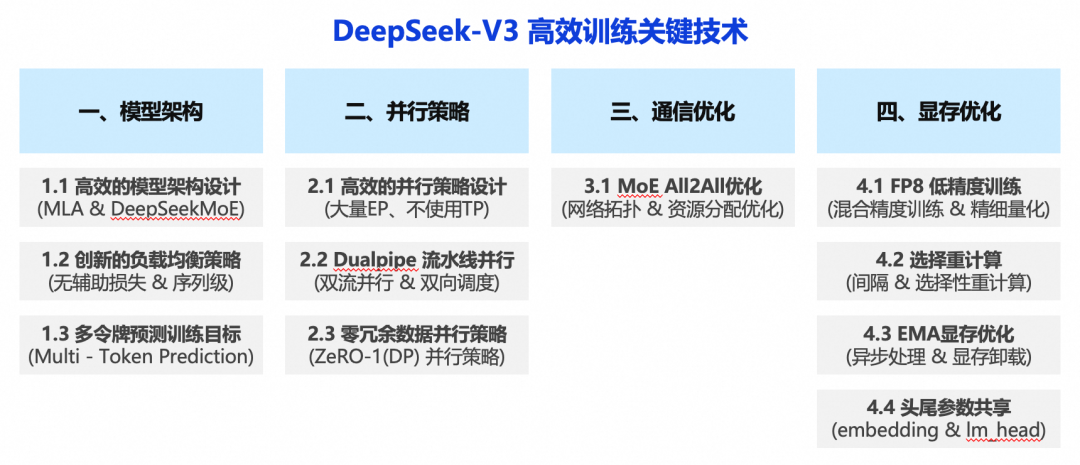
前言
今年春节 DeepSeek-V3&R1 对国内外 AI 圈产生了巨大的影响,其本质在于开拓了一条不同于 OpenAI 训练方法的道路,证明了通过模型架构和训练方法的极致优化,能够基于更少的算力资源训练出同等能力水平的大模型,这不仅让人们对 OpenAI 等厂商的高算力投入产生质疑,更通过将先进模型开源的策略对 OpenAI 等闭源模型的商业模式形成了巨大冲击。
本文试图探究 DeepSeek 为什么能够利用5%的算力训练出对标 GPT-4o 的先进模型,由于 DeepSeek-R1 源于 DeepSeek-V3 架构,且 DeepSeek-V3 论文中讲述了更多高效训练方法相关的内容,所以本文将以 DeepSeek-V3 为研究对象,分析其在高效训练方面都采用了哪些关键技术,未来再单独针对 DeepSeek-R1 进行分析总结。
一、模型架构
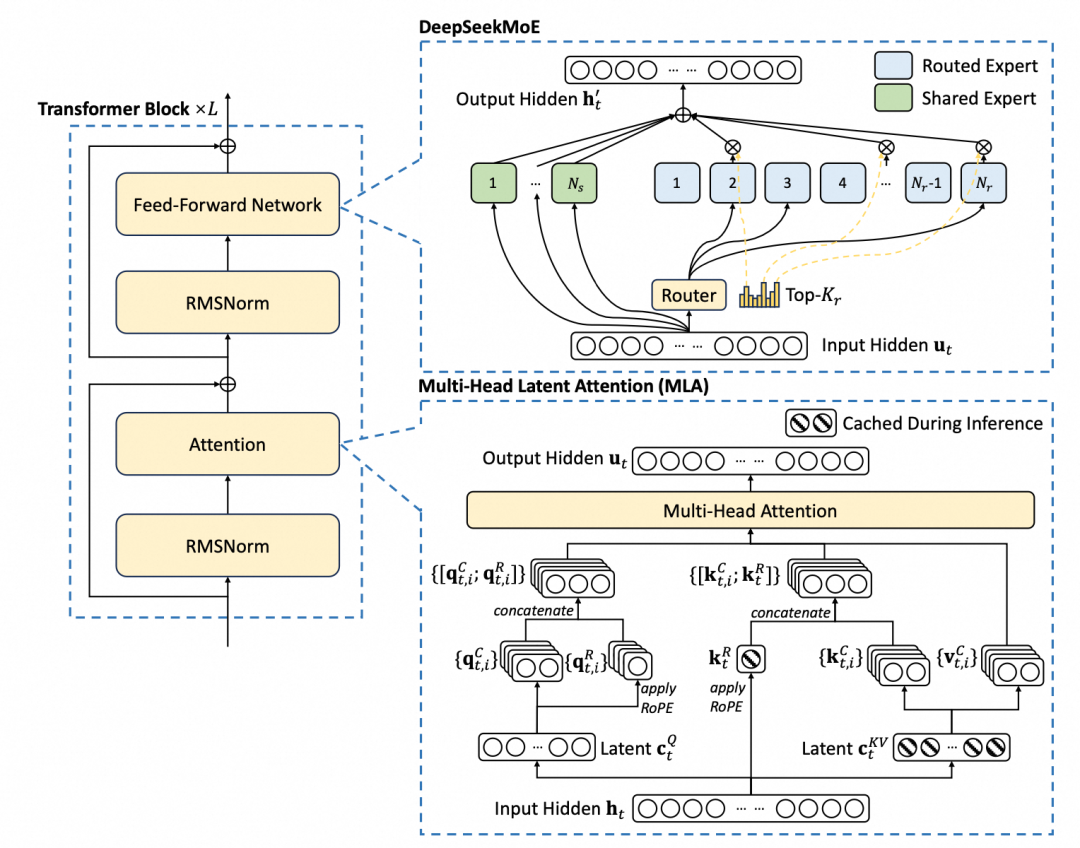
1.1 高效的模型架构设计:多头潜在注意力 MLA 和 DeepSeekMoE 架构
1. 多头潜在注意力 MLA:MLA(Multi - head Latent Attention)架构与标准的MHA(Multi - head Attention)架构相比,核心是对注意力键和值进行低秩联合压缩,减少了推理时的 Key - Value(KV)缓存,减少了推理内存占用,提升了推理效率,该架构对训练过程无直接帮助,不是本文分析的重点。
2. DeepSeekMoE 架构:核心是采用了更细粒度的专家分配策略,每个MoE层有1个共享专家和256个路由专家(共有58个MoE层14906个专家),每个输入Token可以激活8个路由专家,该架构可以有效利用计算资源,实现高效训练,其与标准MoE架构存在以下不同点:
a)专家构成:标准MoE架构的类型和分工较为宽泛,一般不会特别强调共享专家的设置,各个专家相对独立的处理不同输入数据,在处理不同类型数据特征时,专家间一般缺少专门设计的协作和共享机制;而 DeepSeekMoE 架构中的共享专家可对不同输入数据中的共性特征进行处理,在不同类型的输入数据间实现共性特征的知识共享,以便减少模型参数冗余,而路由专家则负责处理具有特定模式或特征的数据,提高模型对不同数据的适应性和处理能力。
b)专家分配:标准MoE架构的专家分配策略相对比较粗放,门控网络根据输入数据进行专家选择时,对于一些复杂数据特征的区分不够精准,不能很好地将数据分配到最能处理该特征的专家;而 DeepSeekMoE 架构采用了更细粒度的专家分配策略,门控网络能够更精准地分析输入数据的特征,将其分配到最合适的专家,提升模型对于复杂数据的处理能力。
c)专家激活:标准MoE架构对于输入数据激活的专家数量没有固定标准,在某些情况下输入数据可能会激活过多非必要的专家,导致计算资源的浪费;而 DeepSeekMoE 架构明确了每个输入 Token 激活8个路由专家,在保证模型处理效果的同时,避免了过度激活专家带来的计算资源浪费,提高了计算效率、降低了计算成本;在具体实现方式上,共享专家会对每个输入 Token 进行处理,以便提取通用的基本特征,而路由专家会根据输入 Token 的特征而决定是否被激活参与计算。
1.2 创新的负载均衡策略:无辅助损失负载均衡和序列级负载均衡
1. 基本概念:在MoE大模型训练过程中,输入数据会根据一定的路由规则分配到不同的专家模型进行处理,这个过程中可能会出现负载不均衡的情况,即某些专家被频繁调用,而另一些专家则很少被使用,这会导致训练效率和模型性能下降;
业界通常采用的负载均衡策略为引入专门的辅助损失函数来强制平衡专家之间的负载,例如通过惩罚专家之间的负载差异来促使模型均匀地使用各个专家,额外引入的损失函数往往会导致模型复杂度增加、训练不稳定、发生与原本训练目标不一致等问题;
除了上述基于单 Token 的负载不均问题外,一个输入序列中的 Token 在专家间的分配情况也容易出现负载不均,即同一序列中的多个 Token 可能会集中分配给某些专家。
2. 优化方法:DeepSeek-V3 采用无辅助损失负载均衡技术,通过直接在路由机制中融入负载均衡逻辑,避免了引入辅助损失函数,实现了仅通过对路由决策动态调整就实现专家负载均衡的效果;同时训练过程辅以序列级负载均衡策略,确保了每个序列内的专家负载均衡。
a)无辅助损失负载均衡:DeepSeek-V3 为每个专家引入了一个可学习的偏置项,在训练过程中它会随着专家负载情况进行动态更新,当门控网络计算输入 Token 与各专家的匹配得分时,该偏置项会动态调整每个专家的匹配得分,基于得分和对各专家利用率的实时监测(例如在一定时间窗口内专家处理的 Token 数量、计算资源占用时长等),动态调整路由策略,将输入 Token 实时分配给负载较低的专家,这种方法不仅负载均衡效果好,而且避免了引入辅助损失函数带来的衍生问题。
b)序列级负载均衡:DeepSeek-V3 额外增加了一个序列级负载均衡损失函数,对序列中的每个 Token 进行精细化的分析和处理,根据 Token 在序列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











