








本文整理自笔者年前在知乎上的一个回答:
大数据舆情情感分析,如何提取情感并使用什么样的工具?(贴情感标签) 1、我将数据筛选预处理好,然后分好词。 2、是不是接下来应该与与情感词汇本库对照,生成结合词频和情感词库的情感关键词库。 3、将信息与情感关键词库进行比对,对信息加以情感标记。 4、我想问实现前三步,需要什么工具的什么功能呢?据说用spss和武汉大学的ROST WordParser。该如何使用呢? https://www. zhihu.com/question/3147 1793/answer/542401478
情感分析说白了,就是一个文本(多)分类问题,我看一般的情感分析都是2类(正负面)或者3类(正面、中性和负面)。其实,这种粒度是远远不够的。本着“Talk is cheap, show you my code”的原则,我不扯咸淡,直接上代码给出解决方案(而且是经过真实文本数据验证了的:我用一个14个分类的例子来讲讲各类文本分类模型---从传统的机器学习文本分类模型到现今流行的基于深度学习的文本分类模型,最后给出一个超NB的模型集成,效果最优。
**************************************前方高能****************************************
在这篇文章中,笔者将讨论自然语言处理中文本分类的相关问题,将使用一个复旦大学开源的文本分类语料库,对文本分类的一般流程和常用模型进行探讨。
首先,笔者会创建一个非常基础的初始模型,然后基于此使用不同的特征进行改进。
接下来,笔者还将讨论如何使用深度神经网络来解决NLP问题,并在文章末尾以一般关于集成的一些想法结束这篇文章。
本文覆盖的NLP方法有:
- TF-IDF
- Count Features
- Logistic Regression
- Naive Bayes
- SVM
- Xgboost
- Grid Search
- Word Vectors
- Dense Network
- LSTM/BiLSTM
- GRU
- Ensembling
NOTE: 笔者并不能保证你学习了本文之后就能在NLP相关比赛中获得非常高的分数。但是,如果你正确地“吃透”它,并根据实际情况适时作出一些调整,你可以获得非常高的分数。
废话不多说,先导入一些我将要使用的重要python模块。
import pandas as pd
import numpy as np
import xgboost as xgb
from tqdm import tqdm
from sklearn.svm import SVC
from keras.models import Sequential
from keras.layers.recurrent import LSTM, GRU
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.embeddings import Embedding
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from sklearn import preprocessing, decomposition, model_selection, metrics, pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from keras.layers import GlobalMaxPooling1D, Conv1D, MaxPooling1D, Flatten, Bidirectional, SpatialDropout1D
from keras.preprocessing import sequence, text
from keras.callbacks import EarlyStopping
from nltk import word_tokenize接下来,加载并检视数据集。
data=pd.read_excel('/home/kesci/input/Chinese_NLP6474/复旦大学中文文本分类语料.xlsx','sheet1')
data.head()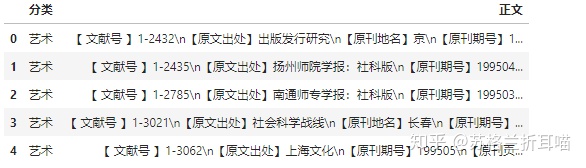
data.info()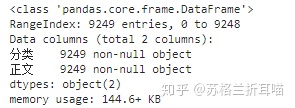
对文本数据的正文字段进行分词,这里是在Linux上运行的,可以开启jieba的并行分词模式,分词速度是平常的好多倍,具体看你的CPU核心数。
import jieba
jieba.enable_parallel(16) #并行分词开启
data['文本分词'] = data['正文'].apply(lambda i:jieba.cut(i) )
data['文本分词'] =[' '.join(i) for i in data['文本分词']]
值得注意的是,分词是任何中文文本分类的起点,分词的质量会直接影响到后面的模型效果。在这里,作为演示,笔者有点偷懒,其实你还可以:
- 设置可靠的自定义词典,以便分词更精准;
- 采用分词效果更好的分词器,如pyltp、THULAC、Hanlp等;
- 编写预处理类,就像下面要谈到的数字特征归一化,去掉文本中的#@¥%……&等等。
data.分类.unique()
data.head()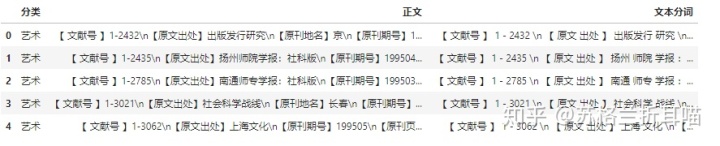
这是一个典型的文本多分类问题,需要将文本划分到给定的14个主题上。
针对该问题,笔者采用了kaggle上通用的 Multi-Class Log-Loss 作为评测指标(Evaluation Metric).
def multiclass_logloss(actual, predicted, eps=1e-15):
"""对数损失度量(Logarithmic Loss Metric)的多分类版本。
:param actual: 包含actual target classes的数组
:param predicted: 分类预测结果矩阵, 每个类别都有一个概率
"""
# Convert 'actual' to a binary array if it's not already:
if len(actual.shape) == 1:
actual2 = np.zeros((actual.shape[0], predicted.shape[1]))
for i, val in enumerate(actual):
actual2[i, val] = 1
actual = actual2
clip = np.clip(predicted, eps, 1 - eps)
rows = actual.shape[0]
vsota = np.sum(actual * np.log(clip))
return -1.0 / rows * vsota接下来用scikit-learn中的Label Encoder将文本标签(Text Label)转化为数字(Integer)
lbl_enc = preprocessing.LabelEncoder()
y = lbl_enc.fit_transform(data.分类.values)在进一步研究之前,我们必须将数据分成训练和验证集。 我们可以使用scikit-learn的model_selection模块中的train_test_split来完成它。
xtrain, xvalid, ytrain, yvalid = train_test_split(data.文本分词.values, y,
stratify=y,
random_state=42,
test_size=0.1, shuffle=True)
print (xtrain.shape)
print (xvalid.shape)(8324,) (925,)
构建基础模型(Basic Models)
让我们先创建一个非常基础的模型。
这个非常基础的模型(very first model)基于 TF-IDF (Term Frequency - Inverse Document Frequency)+逻辑斯底回归(Logistic Regression)。
笔者将scikit-learn中的TfidfVectorizer类稍稍改写下,以便将文本中的数字特征统一表示成"#NUMBER",达到一定的降噪效果。
def number_normalizer(tokens):
""" 将所有数字标记映射为一个占位符(Placeholder)。
对于许多实际应用场景来说,以数字开头的tokens不是很有用,
但这样tokens的存在也有一定相关性。 通过将所有数字都表示成同一个符号,可以达到降维的目的。
"""
return ("#NUMBER" if token[0].isdigit() else token for token in tokens)
class NumberNormalizingVectorizer(TfidfVectorizer):
def build_tokenizer(self):
tokenize = super(NumberNormalizingVectorizer, self).build_tokenizer()
return lambda doc: list(number_normalizer(tokenize(doc)))利用刚才创建的Number Normalizing Vectorizer类来提取文本特征,注意里面各类参数的含义,自己去sklearn官方网站找教程看。
stwlist=[line.strip() for line in open('/home/gaochangkuan/input/stopwords7085/停用词汇总.txt',
'r',encoding='utf-8').readlines()]
tfv  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1672
1672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









