






原文链接:
小样本学习综述: 三大数据增强方法mp.weixin.qq.com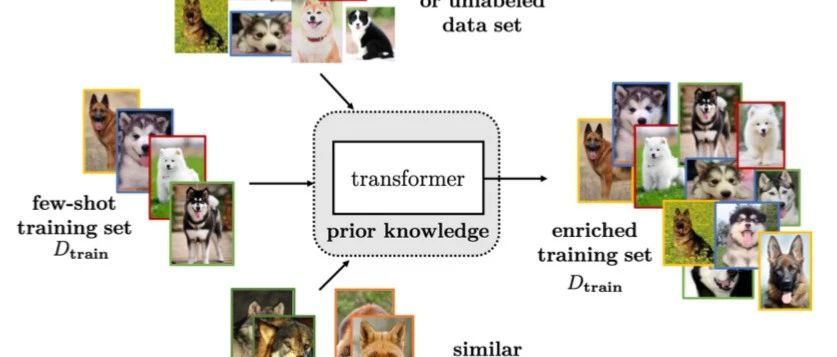
本文内容来源于最新小样本学习综述《Generalizing from a Few Examples: A Survey on Few-Shot Learning》中的第三节——Data部分。该部分内容主要讲如何通过先验知识达到数据增强的目的。文中把现有的数据增强方法归纳为三种:(1)Transforming Samples from Dtrain,(2)Transforming Samples from a Weakly Labeled or Unlabeled Data Set ,(3)Transforming Samples from Similar Data Sets。本文将会对这三种数据增强方法做相关介绍。
✎ Tip
全文共计2945字,预计阅读时长8分钟。关注公众号后台回复"200430",即可获取《Generalizing from a Few Examples: A Survey on Few-Shot Learning》论文原文
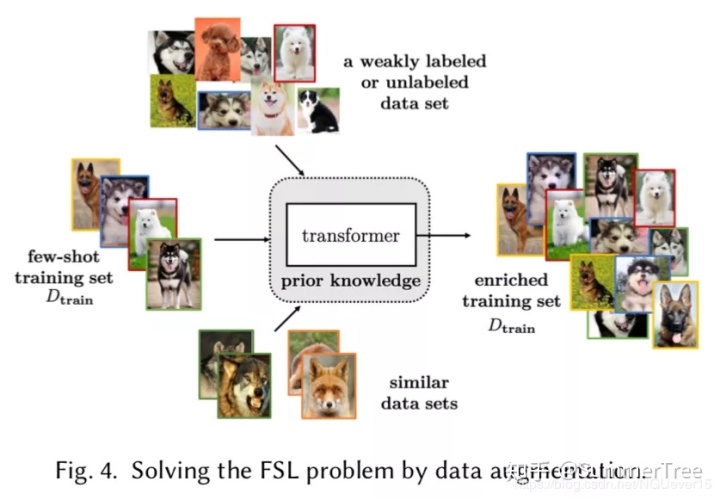
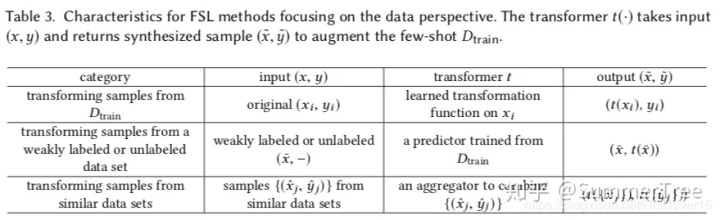
Data augmentation via hand-crafted rules is usually used as pre-processing in FSL methods. They can introduce different kinds of invariance for the model to capture. For example, on images, one can use translation [12, 76, 114, 119], flipping [103, 119], shearing [119], scaling [76, 160], reflection [34, 72], cropping [103, 160] and rotation [114, 138].许多增强规则根据数据集制定,使得他们很难应用到其他数据集中。因此manual data augmentation 不能完全解决FSL问题。还有一些数据增强方式依赖于样本是如何转化和添加到训练集的。我们把他们分类在Table 3当中。
下面,我们将分别介绍这三种方法。
01 Transforming Samples from Dtrain
这个策略通过转换训练集中原有的(xi,yi)(xi,yi)为多个样本来增加训练集DtrainDtrain. 转换过程作为先验知识包含在经验E中,以便生成其他样本。早期的FSL论文[90]通过将每个样本与其他样本反复对齐,从相似的类中学习了一组几何变换。将学习到的变换应用于每个(xi,yi)以形成大数据集,然后可以通过标准机器学习方法学习大数据集。类似地,[116]从相似类中学习了一组自动编码器,每个自动编码器代表一个类内可变性。通过将习得的变化量添加到xixi来生成新样本。在[53]中,通过假设所有类别在样本之间共享一些可变换的可变性,可以学习单个变换函数,将从其他类别学习到的样本对之间的差异转移到(xi,yi)。在[74]中,不是枚举成对的变量,而是使用从大量场景图像中获悉的一组独立的属性强度回归将每个xixi转换为几个样本,并将原始xixi的标签分配给这些新样本。[82]在[74]的基础上进行了改进,将连续属性子空间用于向x添加属性变化。
02 Transforming Samples from a Weakly Labeled or Unlabeled Data Set
此策略通过从标记弱监督或未标记的大数据集中选择带有目标标记的样本来增强Dtrain。例如,在用监控摄像头拍摄的照片中,有人,汽车和道路,但没有一个被标记。另一个示例是一段较长的演示视频。它包含说话者的一系列手势,但是没有一个被明确注释。由于此类数据集包含样本的较大变化,因此将其增加到Dtrain有助于描绘更清晰的p(x,y)p(x,y)。而且,由于不需要人工来标记,因此收集这样的数据集更加容易。但是,尽管收集成本很低,但主要问题是如何选择带有目标标签的样本以增加到Dtrain。在[102]中,为Dtrain中的每个目标标签学习了一个示例SVM,然后将其用于从弱标签数据集中预测样本的标签。然后将具有目标标签的样品添加到Dtrain中。在[32]中,标签传播直接用于标记未标记的数据集,而不是学习分类器。在[148]中,采用渐进策略选择信息丰富的未标记样品。然后为选定的样本分配伪标签,并用于更新CNN。
03 Transforming Samples from Similar Data Sets
该策略通过汇总和改编来自相似但较大数据集的输入输出对来增强DtrainDtrain。聚集权重通常基于样本之间的某种相似性度量。在[133]中,它从辅助文本语料库中提取聚合权重[133]。由于这些样本可能不是来自目标FSL类,因此直接将汇总样本增加到DtrainDtrain可能会产生误导。因此,生成对抗网络(GAN)[46]被设计为从许多样本的数据集中生成不可区分的合成x [42]。它有两个生成器,一个生成器将few-shot类的样本映射到大规模类,另一个生成器将大规模类的样本映射到少数类(以弥补GAN训练中样本的不足) 。
Discussion and Summary
使用哪种增强策略的选择取决于具体的应用。有时,针对目标任务(或类)存在大量弱监督或未标记的样本,但是由于收集注释数据和/或计算成本高昂(这对应于引入的第三种情况)。在这种情况下,可以通过转换标记较弱或未标记的数据集中的样本来执行增强。当难以收集大规模的未标记数据集,但few-shot类具有某些相似类时,可以从这些相似类中转换样本。如果只有一些学习的转换器而不是原始样本可用,则可以通过转换训练集中的原始样本来进行扩充。总的来说,通过增强DtrainDtrain解决FSL问题非常简单明了, 即通过利用目标任务的先验信息来扩充数据。另一方面,通过数据扩充来解决FSL问题的弱点在于,扩充策略通常是针对每个数据集量身定制的,并且不能轻易地用于其他数据集(尤其是来自其他数据集或域的数据。最近,AutoAugment [27]提出了自动学习用于深度网络训练的增强策略的来解决这个问题。除此之外,因为生成的图像可以很容易地被人在视觉上评估,现有的方法主要是针对图像设计的。而文本和音频涉及语法和结构较难生成。[144]报告了最近对文本使用数据增强的尝试。
推荐参考文献
[108]T. Pfister, J. Charles, and A. Zisserman. 2014. Domain-adaptive discriminative one-shot learning of gestures. InEuropean Conference on Computer Vision. 814–829.
[32] Y. Duan, M. Andrychowicz, B. Stadie, J. Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba. 2017. One-shot imitation learning. In Advances in Neural Information Processing Systems. 1087–1098.[27] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le. 2019. AutoAugment: Learning augmentation policies from data. In Conference on Computer Vision and Pattern Recognition. 113–123.
更多参考文献可通过阅读原文获得。














 2016
2016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









