







 通过Excel进行因子分析,研究48位求职者15个维度的适应度数据,发现4个因子可解释75.5%的变异。因子1关联形象、好感度等,适合推销员;因子2、3关联申请书、经验和匹配度,可能适合管理岗位。结果有助于简化评价维度并理解求职者特质。
通过Excel进行因子分析,研究48位求职者15个维度的适应度数据,发现4个因子可解释75.5%的变异。因子1关联形象、好感度等,适合推销员;因子2、3关联申请书、经验和匹配度,可能适合管理岗位。结果有助于简化评价维度并理解求职者特质。
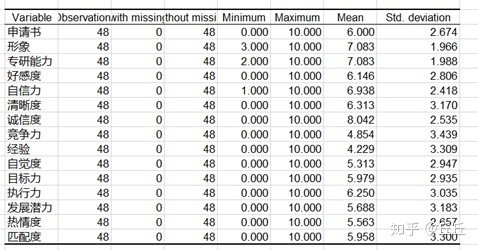
有48位求职者信息,用15个维度来衡量求职者与岗位的适应度,具体数据信息如下:
由于变量之间的许多相关性很高,因此认为法官可能会混淆某些变量,或者某些变量可能是多余的。因此,进行了因素分析以确定较少的潜在因素。
通过使用Excel做因子因素分析后,可以得到如下结果:
下表显示的是所选变量的摘要统计量以及变量之间的相关矩阵。我们可以看到一些相关性非常高(“执行流”和“清晰度”为0.883)。
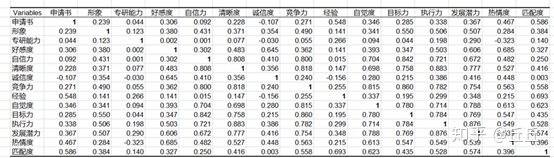
为整个输入表计算标准化的Cronbach的alpha。α为0.914意味着所选变量之间存在一定的冗余。
再看和残差相关矩阵可以验证因子分析模型是否正确,以及在哪里无法再现相关性。
下表显示了因子分析得出的特征值。我们可以看到,使用4个因子,保留了初始数据变异性的75.5%。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8379
8379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









