






 本文采用聚类分析和因子分析方法,针对知乎上的101个“统计”相关话题进行研究。通过关注数、提问数等6个指标,将话题聚为3类,并提取出2个关键因子。结果显示,‘统计学’影响力最大,其次是‘统计、数据统计、统计软件’等。此研究为理解非学术人群对统计的认知提供了量化依据。
本文采用聚类分析和因子分析方法,针对知乎上的101个“统计”相关话题进行研究。通过关注数、提问数等6个指标,将话题聚为3类,并提取出2个关键因子。结果显示,‘统计学’影响力最大,其次是‘统计、数据统计、统计软件’等。此研究为理解非学术人群对统计的认知提供了量化依据。

摘要:当前随着高等教育的普及,民众对于专业型知识的了解越加广泛,为了明确网络用户对于“统计”的认知程度,本文选取了“知乎”这一知识交流软件,以其话题数据作为本文的分析基础。本文采用多元统计中的聚类分析和因子分析方法对知乎上的“统计”相关话题进行分析。结合知乎软件上有关统计的101个话题,本文选取了关注数、提问数、精华数、父话题数、子话题数以及被引数6个指标,利用SPSS及R Studio软件,将原先的101个统计相关话题聚为3类,以及原先的6个指标提炼出两个公因子,并且将聚类结果用可视化的聚类图表示出来,为每类话题作出全面、客观、合理的评价。
关键词:知乎;统计;聚类分析;因子分析
1 引言
对学科关注点及其变化轨迹的挖掘与分析,有助于对学科发展现状及发展趋势的了解,因此一直受到人们的关注,传统意义上的学科热点分析,一般以期刊论文、硕博士论文等传统的学术文献作为信息源进行分析,但是以学术文献作为信息源的做法难以反映学术圈以外的群众对于学科的认识与了解,赖纪瑶等[1]选择知乎的“情报学”话题作为学科热点挖掘和分析对象,对情报学话题下“精华页面”中所有回答进行情报学科关注焦点分析;黄鲁成等[2]构建网络问答社区的话题识别指标,从话题关键词、关键词分布以及热点子话题3个角度对“老年人”话题焦点进行识别与分析;杜洋[3]选取“头腾大战”这一热点话题,用python语句批量采集知乎网站中关于“头腾大战”的问题与回答数据,以此分析回答内容的情感特征和王网友对于两家企业的支持情况。
总的来说,知乎网是一种新兴的知识交流载体,它超越了传统问答网站以答案为终点的模式,集问答、知识生产与共享、社交为一体,成为一个知识交流与积累的空间,在浮躁的网络文化环境中,知乎网理性的社群性质、优质的内容产出使其广受好评,在一众娱乐化、商业化倾向严重的社交网站中,知乎网显得格外突出,并且现有的关于学科的认知程度的研究大多存在于学术文献和期刊之间,对于知乎这种新兴的载体研究较少,另外,虽然现在有部分关于“知乎”话题的研究,但是大多是运用文本识别和分词技术对爬取的知乎文本数据进行分析,以用于个性化问题推荐,像本文的直接研究非学术人群对于学术话题“统计”的研究方式寥寥无几。因而本文试图通过聚类分析和因子分析的方法探究非学术人群对于“统计”相关话题的定量认识。
2 话题选取
社会化问答网站通过问答来实现信息与信息、用户与信息、用户与用户的复杂交互,在此过程中会留下大量的关于不同话题的讨论与问答[4],在统计学专业的背景下,选取知乎软件“统计”相关话题作为研究对象,知乎网目前日活跃用户量上千万,庞大的用户群体每天都在源源不断地产生新内容,对知乎网海量信息进行全面分析不具可操作性,因为本文选取的“知乎”相关话题是截止到2019年1月17日,共选取了包含“统计”、“贝叶斯统计”、“心理统计”、“统计物理”、“统计学分布”等在内的101个话题。
根据系统性原则以及可行性原则设立6个评价指标:关注数(人)、提问数(个)、精华数(个)、父话题数(个)、子话题数(个)、被引数(次)。在使用上述方法构建指标、收集数据后,用SPSS 25.0对其分别进行系统聚类以及k-means聚类,查看聚类结果并结合先验知识将其分为3类,并用R Studio软件将其绘制成聚类可视图,并用KMO和Bartlett球形度检验样本数据是否适合作因子分析,若指标间存在相关性,采用因子分析法,通过线性变换,将原始指标综合为少数几个公因子,公共因子间相互无关,并且这少数几个公因子包含原始变量的大部分信息,然后把方差贡献率作为权重,构造公因子的线性函数,该函数值即话题的综合热度大小。
3 聚类分析和因子分析过程
3.1 聚类分析
通过对“统计”相关话题进行聚类分析,运用SPSS 25进行系统聚类,得到聚类树形图,如图1所示。
图1 统计话题聚类树形图
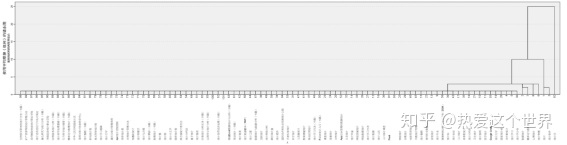
从图1可以看出,若把话题分成3类,则92为第1类,1、3为第2类,2、4~91、93~101为第3类。
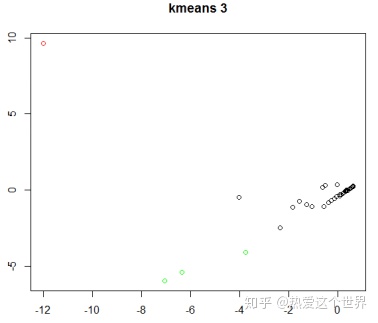
再运用SPSS 25进行快速聚类,得到“统计”相关话题的最终聚类中心、每个聚类中的个案数目以及“统计”相关话题的分类表,并用R Studio可视化表达聚类结果。
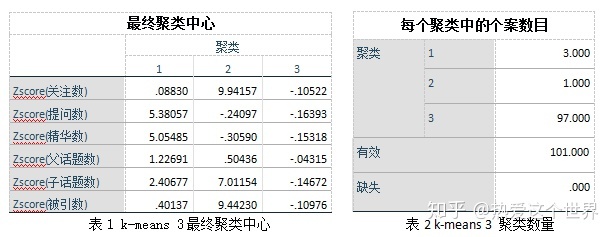
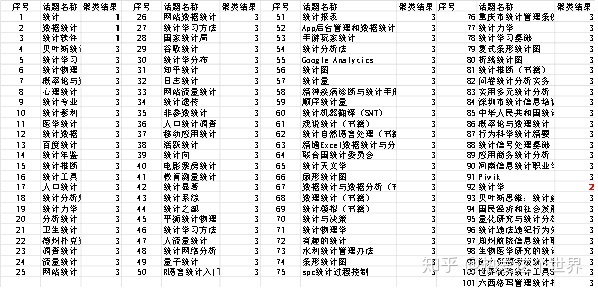
表3 k-means 3聚类结果
图2 k-means 3聚类可视图
3.2 因子分析
应用SPSS 25将原始数据标准化并计算出相关系数矩阵如表4所示,再进行KMO和Bartlett球形度检验,KMO和Bartlett的检验结果显示,KMO值>0.5,勉强适合做因子分析,显著性<0.5,说明指标间具有相关性,适合做因子分析。由相关系数矩阵求得其特征值与方差累计贡献率如表6所示。从表6可以看出,前两个主成分的特征值大于1,并且累计贡献率达到83.058%,故提取前2个作为公因子。
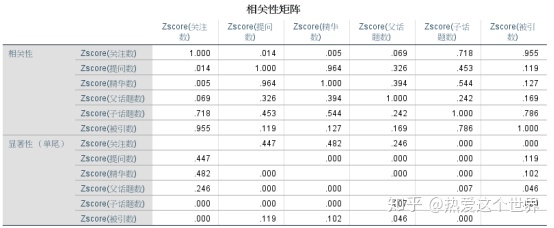
表4 相关性矩阵

表5 KMO和巴特利特球形度检验
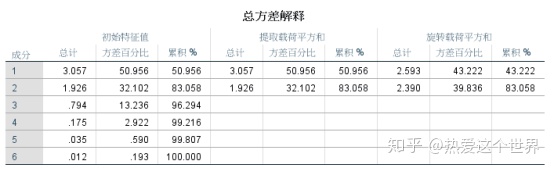
表6 解释的总方差
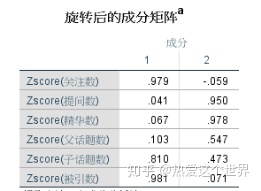
表7 旋转后的因子载荷矩阵
因子载荷表达了公共因子对原始变量的解释程度,由于初始因子载荷矩阵中,各因子表达的含义不够明确,为此采用旋转变换,是各因子的意义凸显出来,经过四次迭代收敛,得到旋转后的因子载荷矩阵如表7所示。第一公因子包含关注数、子话题数和被引数,称为热度因子,第二公因子包含提问数、精华数和父话题数,称为内容因子。
2个因子的得分函数分别为:
F1=0.250X1-0.045X2-0.040X3-0.006X4+0.176X5+0.243X6
F2=-0.076X1+0.268X2+0.275X3+0.149X4+0.085X5-0.039X6
F=(λ1旋*F1+λ2旋*F2)/(λ1旋+λ2旋)
根据因子得分函数可以计算出每个话题的综合得分以及热度因子和内容因子的单项得分,表8是综合得分由高到低的前十个话题。
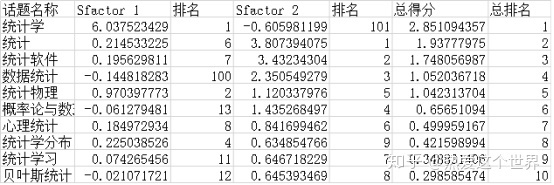
表8 话题综合得分前十位
由表可见,“统计”相关话题影响力最大的前十位依次为:统计学、统计、统计软件、数据统计、统计物理、概率论与数理统计、心理统计、统计学分布、统计学习、贝叶斯统计。
4 结论分析
4.1 聚类分析
系统聚类和快速聚类的结果相似,都是把101个“统计”相关话题分为三类,唯一的区别是系统聚类并没有把“数据统计”和“统计、统计软件”归为一类,而是和剩下的97个话题归为一类。其中,人们对于统计最广泛的认识是“统计学”,说明在想到“统计”时,第一印象仍是把“统计”当作一个专业来看待,其次对“统计的”认识是“统计、数据统计、统计软件”,说明人们把“统计”当作一门运用各种软件进行数据处理工作的一门学科,最后才是包含心理统计、统计物理、百度统计、医学统计等衍生话题。
4.2 因子分析
把关注数、提问数、精华数、父话题数、子话题数、被引数六个指标提取为热度因子和内容因子,并按因子得分函数求得综合得分,从表8的排序结果来看,综合排序的结果与聚类分析的结果基本一致,“统计学”的综合得分显著地高于其他的相关话题,而除了第二类的“统计”、“统计软件”、“数据统计”,还有一个“统计物理”的综合得分超过1,除此之外,非学术群众对于统计相关话题有基本了解的还有“概率论与数理统计”、“心理统计”、“统计学分布”、“统计学习”、“贝叶斯统计”、“统计力学”、“人口统计”、“非参数统计”以及“Google Analytics”,综合来看,对“统计”相关话题的影响力评价较为全面、客观。
参考文献
[1] 赖纪瑶,魏思仪,秦玥. 基于“知乎”关注热点的学科认知特点挖掘——以情报学为例 [J].图书情报工作,2017(24).
[2] 黄鲁成,蒋林杉,苗红等.基于网络问答社区的话题识别与分析——以知乎“老年人”话题为例[J].图书情报工作,2016(5).
[3] 杜洋.基于知乎数据的情感分析——以“头腾”大战为例[J].江苏科技信息,2018(31).
[4] 蔡骐,陈月.基于社会网的知乎网意见领袖研究[J].湖南师范大学社会科学学报,2018(5).

















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









