






Abstract: 本文主要研究几个关于共享内存的例子,以此来了解共享内存的性质,为我们的核函数加速Keywords: 行主序,列主序,填充与无填充,从线程索引体映射数据元素
开篇废话
同一个东西,A花大工夫做到极致,成本100,售价200;C模仿A的做法快速的通过仿制,节省了研发试验的所有开销,但是没有做到A那么完美,成本25,售价140。A虽然好但是不见得销量有C高,并且A的利润并没有C那么高,所以,作为商人,选择C是没错的,商人的目的就是盈利,但是问题来了,如果不是商人呢?而是一个科学家呢?
本文我们主要研究共享内存的数据布局,通过代码实现,来观察运行数据,换句话说,我们主要研究上一篇中的放西瓜,取西瓜,以及放冬瓜等的一些列操作对性能的影响,以及如何才能使效率最大化。
几个例子包括以下几个主题:
- 方阵与矩阵数组
- 行主序与列主序
- 静态与动态共享内存的声明
- 文件范围与内核范围的共享内存
- 内存填充与无内存填充
当使用共享内存设计核函数的时候下面两个概念是非常重要的:
1. 跨内存存储体映射数据元素
2. 从线程索引到共享内存偏移的映射
当上面这些主题和概念都得到很好地理解,设计一个高效的使用共享内存的核函数就没什么问题了,其可以避免存储体冲突并充分利用共享内存的优势。
注意,从几何上讲,方形属于矩形,这里我们说的矩形时指长方形。
方形共享内存
我们前面说过我们的线程块可以是一维二维和三维的,对应的线程编号是threadIdx.x, threadIdx.y以及threadIdx.z,为了对应一个二维的共享内存,我们假设我们使用二维的线程块,那么对于一个二维的共享内存
#define N 32
...
__shared__ int x[N][N];
...
当我们使用二维块的时候,很有可能会使用下面这种方式来索引x的数据:
#define N 32
...
__shared__ int x[N][N];
...
int a=x[threadIdx.y][threadIdx.x];
当然这个索引就是 $(y,x)$ 对应的,我们也可以用 $(x,y)$ 来索引。
在CPU中,如果用循环遍历二维数组,尤其是双层循环的方式,我们倾向于内层循环对应x,因为这样的访问方式在内存中是连续的,因为CPU的内存是线性存储的,但是GPU的共享内存并不是线性的,而是二维的,分成不同存储体的,并且,并行也不是循环,那么这时候,问题完全不同,没有任何可比性。
回顾放西瓜的例子以及存储体冲突的特性,容易想到,我们最应该避免的是存储体冲突,那么对应的问题就来了,我们每次执行一个线程束,对于二维线程块,一个线程束是按什么划分的呢?是按照threadIdx.x 维进行划分还是按照threadIdx.y维进行划分的呢?
这句话有点迷糊?那我再啰嗦一遍,因为这个很关键,我们每次执行的是一个线程束,线程束里面有很多线程,对于一个二维的块,切割线程束有两种方法,顺着y切,那么就是threadIdx.x固定(变化慢),而threadIdx.y是连续的变化,顺着x切相反;CUDA明确的告诉你,我们是顺着x切的,也就是一个线程束中的threadIdx.x 连续变化。
我们的数据是按照行放进存储体中的这是固定的,所以我们希望,这个线程束中取数据是按照行来进行的,所以
x[threadIdx.y][threadIdx.x];
这种访问方式是最优的,threadIdx.x在线程束中体现为连续变化的,而对应到共享内存中也是遍历共享内存的同一行的不同列
上面这个确实有点绕,我们可以画画图,多想象一下CUDA的运行原理,这个就好理解了,说白了就是不要一个线程束中访问一列共享内存,而是要访问一行。
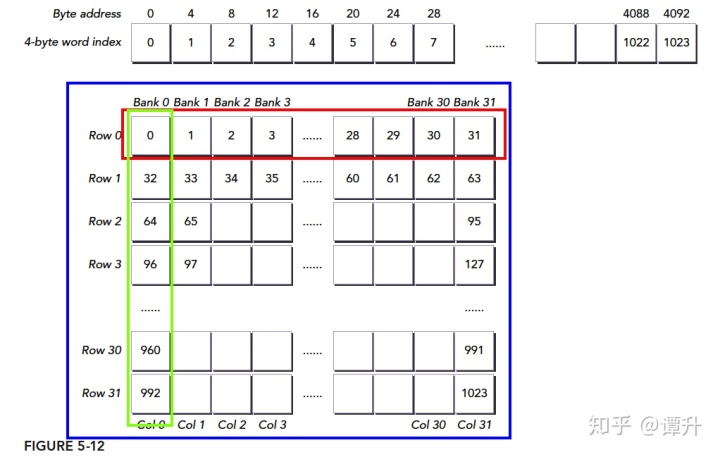
对照上图,我们把一个int类型(四字节)的1024个元素的数组放到共享内存A中,每个int的索引对应到蓝框中,假设我们的块大小是 $(32,32)$ 那么我们第一个线程束就是 threadIdx.y=0,threadIdx.x=0......31,如果我们使用
A[threadIdx.x][threadIdx.y];
的索引方式,就会得到绿框的数据,可想而知,这冲突达到了最大,效率最低、
果我们使用
A[threadIdx.y][threadIdx.x];
我们就会得到红色框中的数据,无冲突,一个事务完成。
本文全部代码在GitHub上可下载使用:https://github.com/Tony-Tan/CUDA_Freshman
行主序访问和列主序访问
行主序访问和列主序访问我们上面已经把原理基本介绍清楚了,我们下面看实现后的试验,这里我们研究的访问,包括读和写,也就是加载和存储。
我们定义块的尺寸为
#define BDIMX 32
#define BDIMY 32
核函数只完成简单的两个操作:
- 将全局线程索引值存入二维共享内存
- 从共享内存中按照行主序读取这些值并存到全局内存中
项目完整的代码在24_shared_memory_read_data这个文件夹下,下文我们只贴部分代码。
核函数如下
__global__ void setRowReadRow(int * out)
{
__shared__ int tile[BDIMY][BDIMX];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[threadIdx.y][threadIdx.x];
}
- 定义一个共享内存,大小为 $32times 32$
- 计算当前线程的全局位置的值idx
- 将idx这个无符号整数值写入二维共享内存tile[threadIdx.y][threadIdx.x]中
- 同步
- 将共享内存tile[threadIdx.y][threadIdx.x]中的值写入全局内存对应的idx位置处
核函数的内存工作:
1. 共享内存的写入
2. 共享内存的读取
3. 全局内存的写入
这个核函数按照行主序读和写,所以对于共享内存没有读写冲突
另一种方法就是按照列主序访问了,核函数代码如下:
__global__ void setColReadCol(int * out)
{
__shared__ int tile[BDIMY][BDIMX];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
tile[threadIdx.x][threadIdx.y]=idx;
__syncthreads();
out[idx]=tile[threadIdx.x][threadIdx.y];
}
原理不再赘述,我们直接看运行结果:
对于使用nvprof如果出现 ======== Error: unified memory profiling failed.错误,是因为系统的保护机制,所以使用sudo权限来执行即可,如果sudo找不到你的nvprof,你可以用完整路径,或则添加到环境变量:
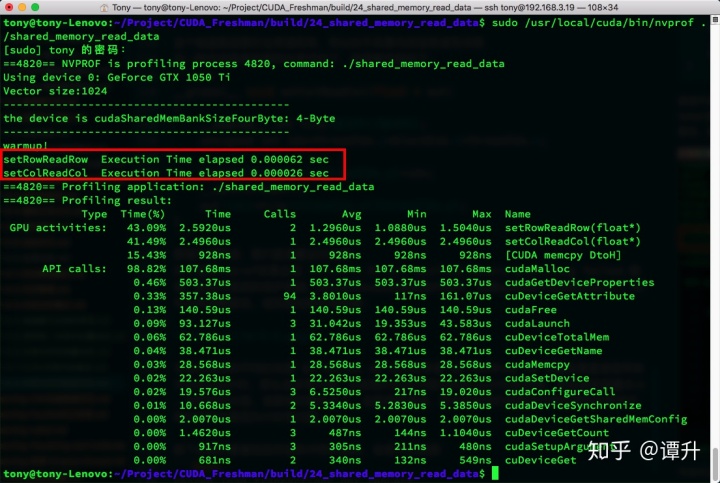
可见行主序的平均时间是 $1.552mu s$ 而列主序是 $2.4640mu s$ 注意如果直接使用来方法即cpu计时,那么会非常不准,比如我们红色方框内就是cpu计时的结果,原因是数据量太小,运行时间太短,误差相对就太大了,这显然是错误,很有可能我们前面也出现过理论和实际不符的情况也是因为计时有问题。
接下来我们看看检测存储体冲突的指标,会是什么数据:
shared_load_transactions_per_request
shared_store_transactions_per_request
- shared_load_transactions_per_request 结果:
nvprof --metrics shared_load_transactions_per_request ./shared_memory_read_data
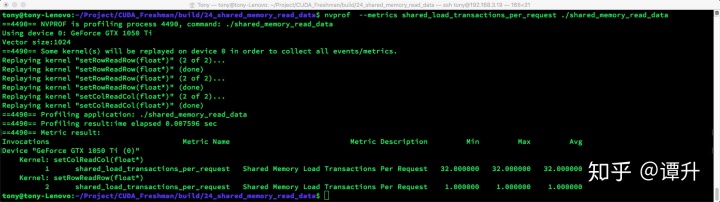
可以看到load过程行主序1个事务,而列主序32个
- shared_store_transactions_per_request 结果:
nvprof --metrics shared_store_transactions_per_request ./shared_memory_read_data
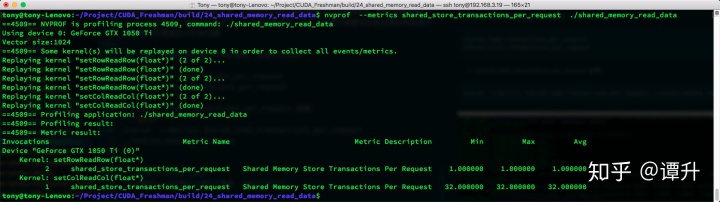
同样行主序的事务是1,而列主序的事务是32
注意,我们这个设备是4-byte宽的,上面第二张图中有相关信息。
按行主序写和按列主序读
完整内容在 https://face2ai.com/CUDA-F-5-2-共享内存的数据布局/















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









