






ACCV 2024 | ViT涨点神器!DeBiFormer:双层路由注意力新框架
转载自:晓飞的算法工程笔记
论文: DeBiFormer: Vision Transformer with Deformable Agent Bi-level Routing Attention

-
论文地址:https://arxiv.org/abs/2410.08582
-
论文代码:https://github.com/maclong01/DeBiFormer
创新点
-
提出了可变形双层路由注意力(
DBRA),一种用于视觉识别的注意力内注意力架构,利用代理查询优化键值对的选择并增强注意力图中查询的可解释性。 -
提出了一种新型主干网络
DeBiFormer,基于注意力热图的可视化结果具有更强的识别能力。 -
在
ImageNet、ADE20K和COCO上进行的大量实验表明,DeBiFormer始终优于其他基线。
内容概述
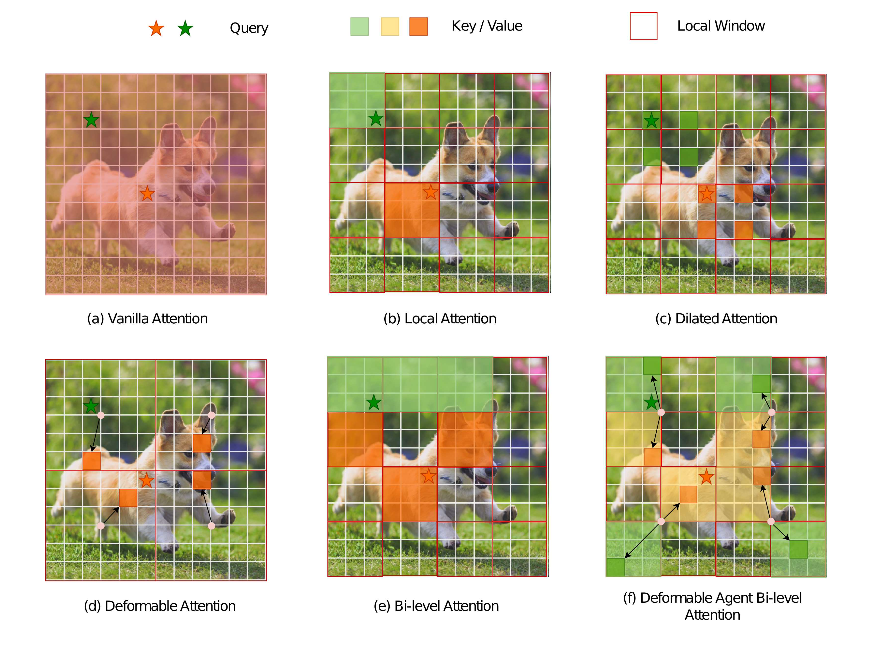
为了改善注意力,许多研究提出了精心设计的高效注意力模式,其中每个查询仅选择一小部分键值对进行关注。然而,尽管有不同的合并或选择键和值标记的策略,这些标记对于查询而言并不具有语义性。在将预训练的ViT和DETR应用于其它下游任务时,查询并不是来自语义区域的键值对。因此,强迫所有查询集中在不充足的标记集合上可能不会产生最佳结果。
最近,随着动态查询感知的稀疏注意力机制的出现,查询聚焦于动态语义最强的键值对,即双层路由注意力。然而,在这种方法中,查询是由语义键值对处理的,而不是源自详细的区域,这在某些情况下可能无法产生最佳结果。此外,在计算注意力时,为所有查询选择的这些键和值受到过多无关查询的影响,导致对重要查询的关注减少,这在执行分割时会产生显著影响。
为了使查询的注意力更加高效,论文提出了可变形双层路由注意力(DBRA),这是一种用于视觉识别的注意力内注意力架构。
-
第一个问题是如何定位可变形点。为注意力附加一个偏移网络,该网络以查询特征为输入,生成所有参考点的相应偏移量。因此,候选的可变形点朝着重要区域移动,以高灵活性和高效率捕获更多信息特征。
-
第二个问题是如何从语义相关的键值对中聚合信息,然后将信息广播回查询。当选择用于可变形点的键值对时,专注于前
k个路由区域,选择与区域仅需的语义最相关的部分键值对。在选择了语义相关的键值对后,对可变形点查询应用标记到标记的注意力,然后应用第二个标记到标记的注意力将信息广播回查询。在此过程中,作为键值对的可变形点用于表示语义区域中最重要的点。
DeBiFormer
可变形双层路由注意力(DBRA)
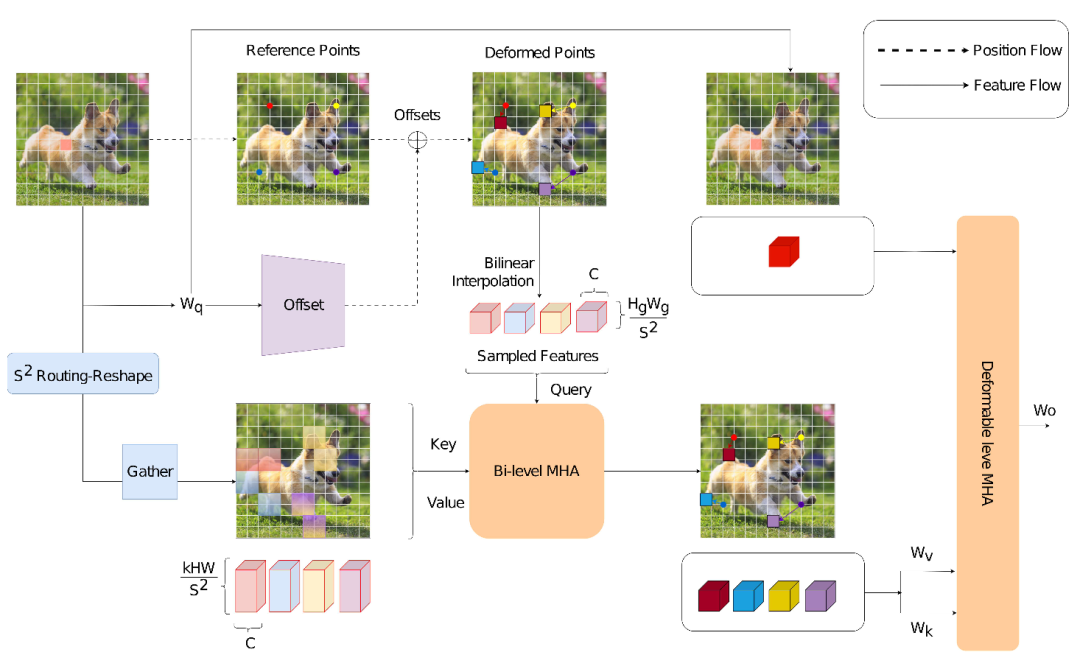
DBRA首先采用一个可变形注意力模块,根据查询特征生成参考点的偏移量,得到可变形点。然而,这些点往往倾向于聚集在重要区域,导致在某些区域的过度集中。
为了解决这个问题,参考BiFormer引入了可变形点感知的区域划分,确保每个可变形点仅与少量的键值对进行交互。然而,单靠区域划分可能导致重要区域和不重要区域之间的不平衡。
为了应对这一问题,DBRA将每个可变形点作为一个代理查询,与语义区域的键值对计算注意力。这种方法确保每个重要区域只分配少数可变形点,从而使注意力能够分布在图像的所有关键区域。较少重要区域的注意力得以减少,而在更重要的区域则得以增加,从而确保整个图像的注意力分布达成平衡。
Model architectures
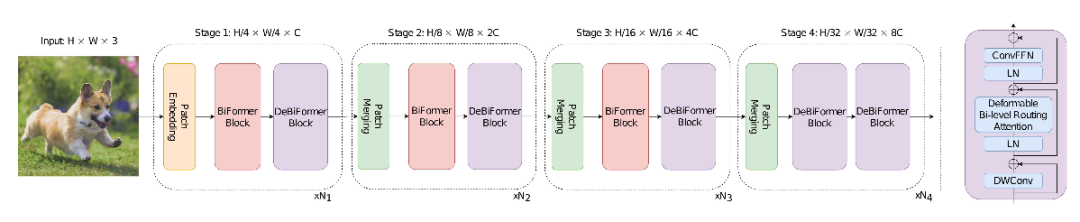
基于DBRA作为基本构建块,论文提出了一种新颖的视觉变换器,称为DeBiFormer。
遵循了最先进的视觉Tansformer,采用四阶段金字塔结构。在第一阶段使用重叠的图像块嵌入,在第二到第四阶段使用图像块合并模块。这是为了降低输入的空间分辨率,同时增加通道数。随后,使用 个连续的DeBiFormer块来转换特征。
在每个DeBiFormer块中,开始时使用 的深度卷积,为了隐式编码相对位置的信息。随后,依次使用一个DBRA模块和一个具有扩展比例 的2-ConvFFN模块,分别用于跨位置关系建模和每位置嵌入。
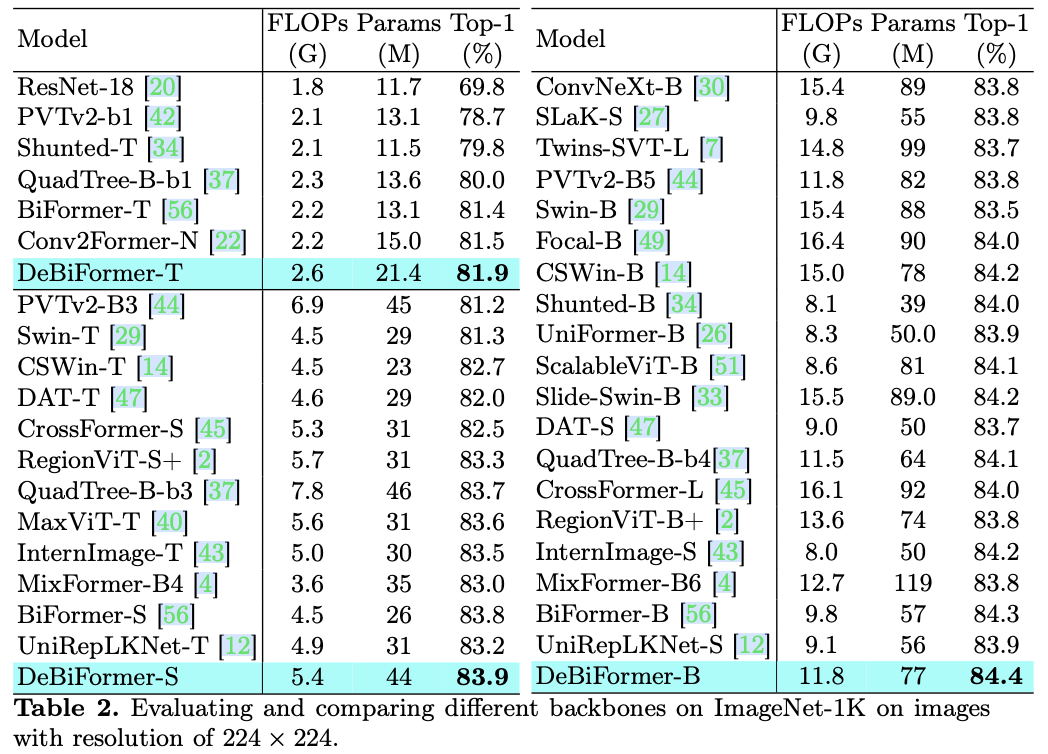
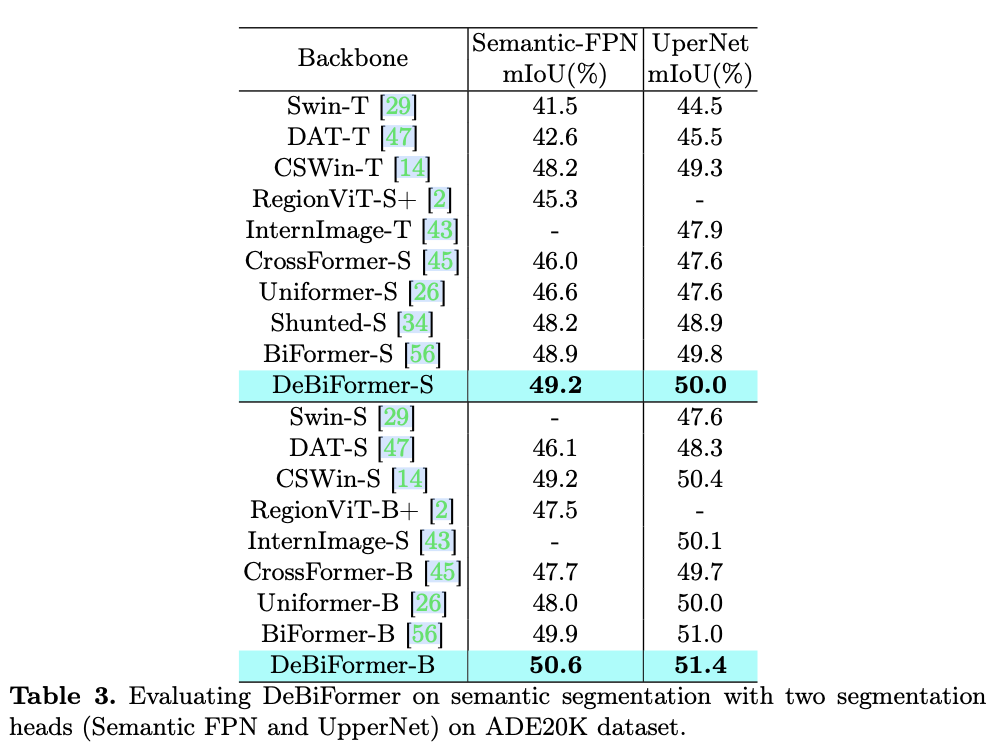
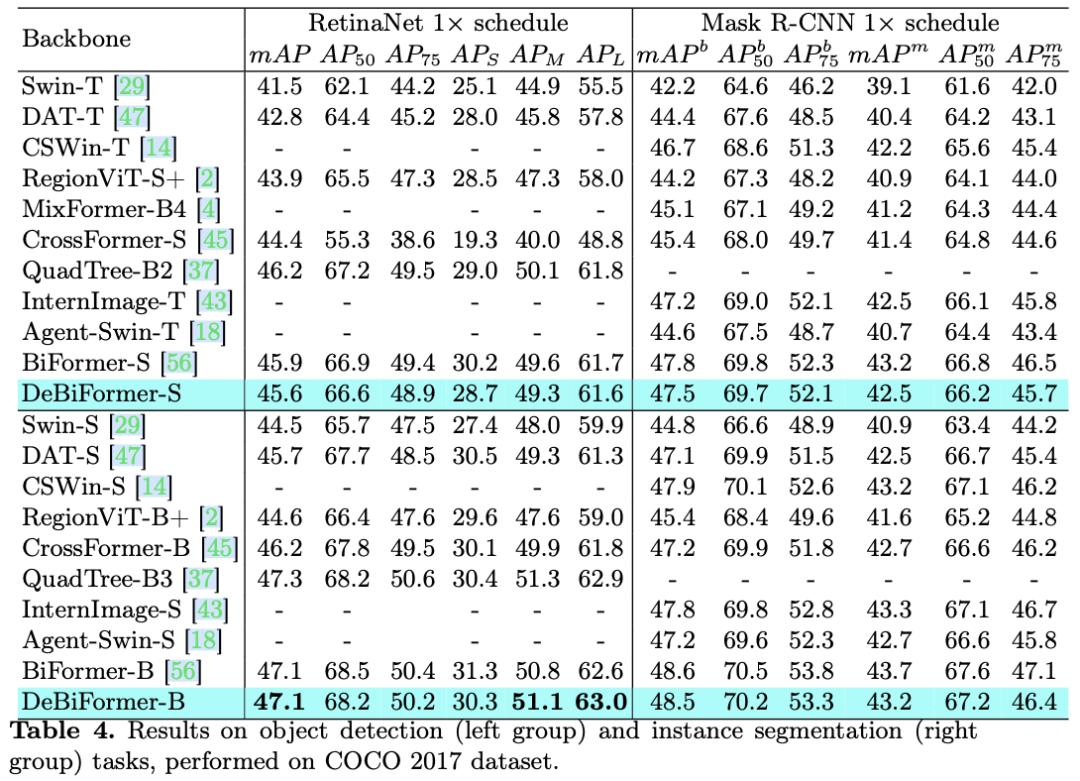
主要实验
何

















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









