





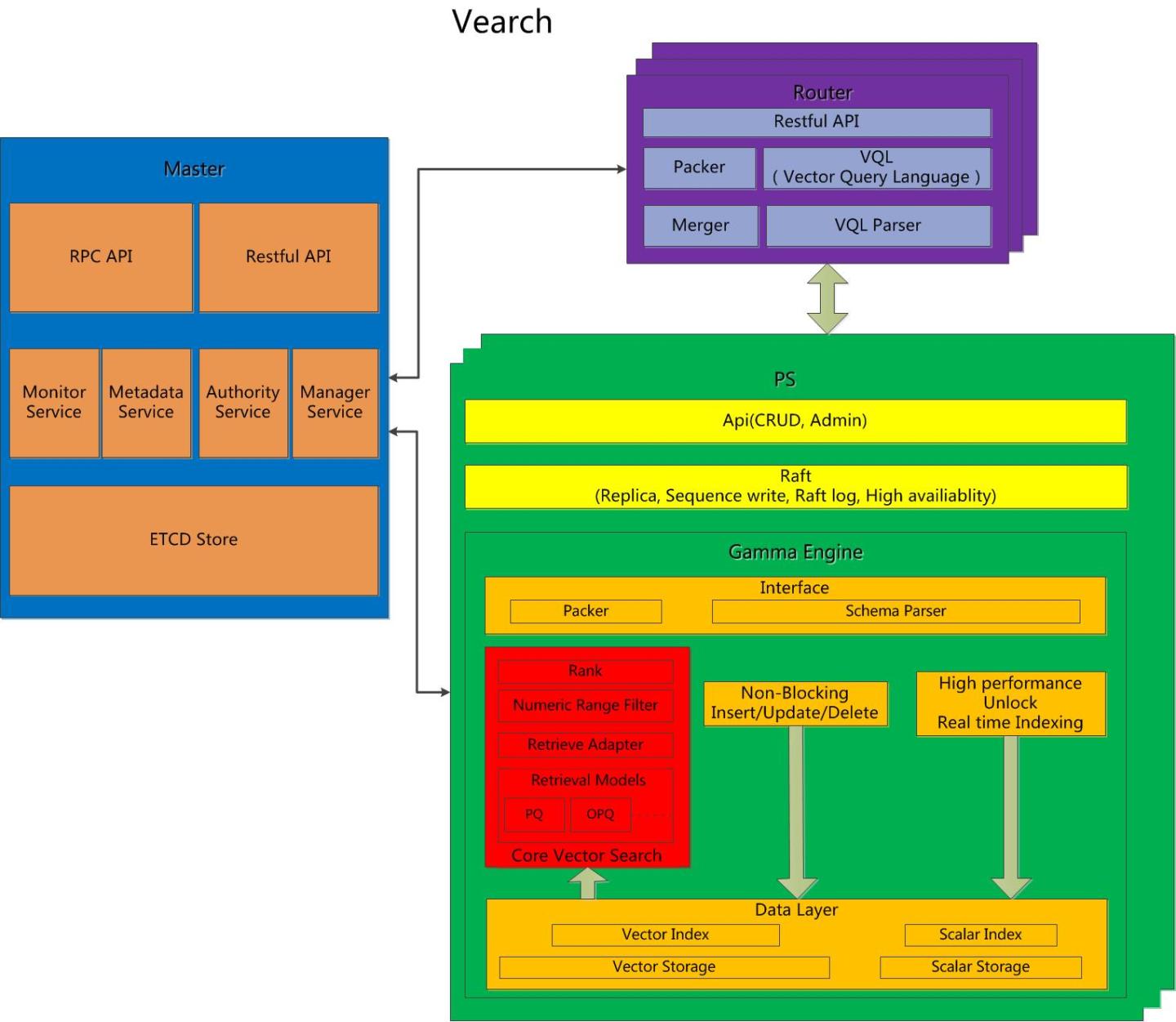
简介: Vearch是一个分布式向量搜索系统,可以用来计算向量相似度或用于机器学习领域 如:图像识别, 视频识别或自然语言处理各个领域。
代码地址:
https://github.com/vearch/vearchgithub.com部署流程:
https://github.com/vearch/vearch/blob/master/docs/Quickstart.mdgithub.com中文文档:
https://vearch.readthedocs.io/zh_CN/latest/overview.htmlvearch.readthedocs.io本文主要介绍GPU版的部署及使用
系统要求:
- CUDA版本大于等于9
- 显卡算力要求3.5以上
支持多张显卡,系统部署后,会自动占用所有显卡,在使用单卡时,GPU的速度是CPU的5-10倍,随着显卡数量增多,性能基本呈线性提升
Vearch的GPU版暂时不支持实时插入功能,所以建表并插入数据后,手动调用建索引命令:
{{ROUTER为了防止插入数据时触发建索引操作,建表时需指定index_size大于等于max_size
Faiss为了保证运算速度,设置了最大nprobe和最大召回数量GPU_MAX_SELECTION_K,其中CUDA版本小于9.2时,GPU_MAX_SELECTION_K为1024,CUDA版本大于等于9.2时,GPU_MAX_SELECTION_K为2048
按照文档部署服务,其中create space步骤需要指定retrieval_type为GPU,并且nprobe小于等于2048(CUDA版本大于等于9.2)
测试过程:
服务器配置:
CPU:Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz(56核)
显卡:Tesla P40(4张显卡),CUDA 10.2
内存:256G
- create database,创建数据库
- create space,其中engin参数为:"engine": {"name":"gamma", "index_size":15000000, "max_size":15000000, "nsubvector":64, "ncentroids": 2048}
- 插入1500万512维数据
- 使用ab进行压测,其中quick设置成false,不使用原始向量进行排序,在数据量巨大的时候,部分数据会存储在磁盘上,如果这时候还要计算相似度的精确值,将会拖慢系统速度。ab并发设置成1000,每次召回100条结果
建完索引后,显卡信息如下
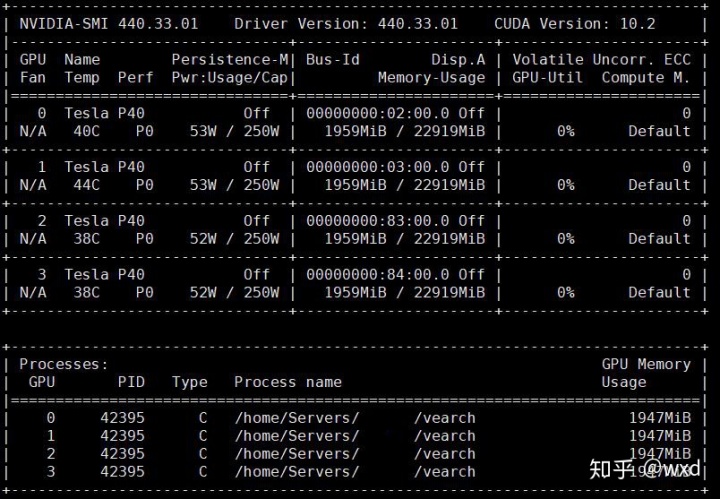
压测过程中

CPU占用

GPU占用只有20%左右,说明在1500万数据量情况下,性能还有很大富裕
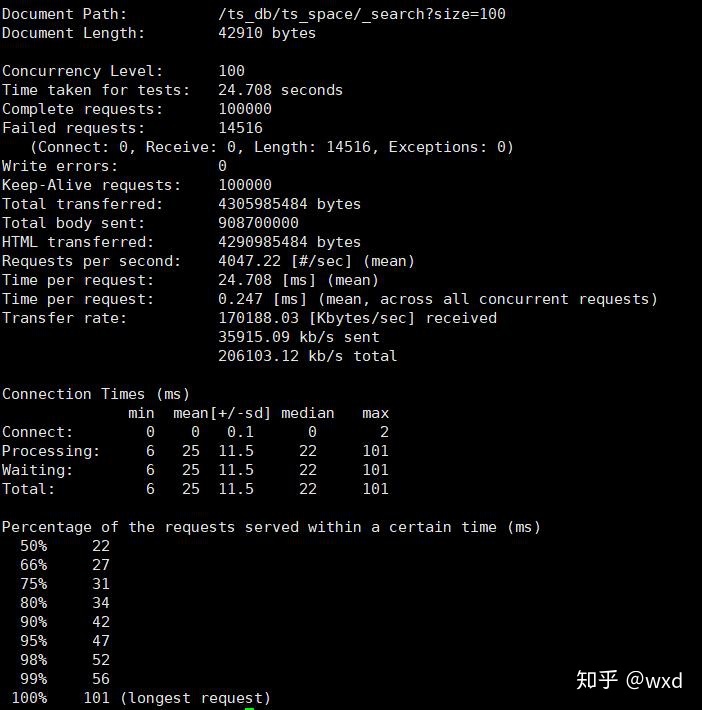
上图是ab的输出结果,QPS达到了4047,tp99为56毫秒,平均响应时间为24毫秒(图中的Failed requests全部为Length,这个是因为返回结果有耗时took字段,每个请求的耗时不可能全部一样,所以这些失败并不是真正的请求失败)
Q&A:
- 建完索引后,能不能继续插入数据呢?
答:能继续插入数据,只是新插入的数据只能在再次调用建索引命令_forcemerge后才能被搜索出,并且建索引的过程中不能进行搜索。
2. 索引何时dump?
答:建索引后自动dump,如果多次建索引,则保留最新的dump文件。















 6511
6511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









