






 支持向量机分类及在R中实现
支持向量机分类及在R中实现
 支持向量机( Support Vector Machine , SVM )是一类可用于分类和回归的有监督机器学习模型。 本篇简介 SVM 的分类功能。
支持向量机( Support Vector Machine , SVM )是一类可用于分类和回归的有监督机器学习模型。 本篇简介 SVM 的分类功能。
SVM分类原理
已知一个数据集包含M个对象N个变量,这些对象可划分为两类别。如果将对象以点绘制在变量空间中,则可获得N维空间。
SVM旨在多维空间中找到一个超平面(hyperplane),该平面能够将全部对象分成最优的两类:两类中距离最近的点的间距(margin)尽可能大。这些在间距边界上的点被称为支持向量(support vector),它们决定间距,分割的超平面位于间距的中间。
因此在一个N维空间(对应N个变量)中,可获得一个N–1维的最优超平面。如下展示了当变量数为2时的情形,超平面此时是一条直线。当变量数为3时,超平面是一个平面;当变量数N>3时,超平面是N-1维的超平面。
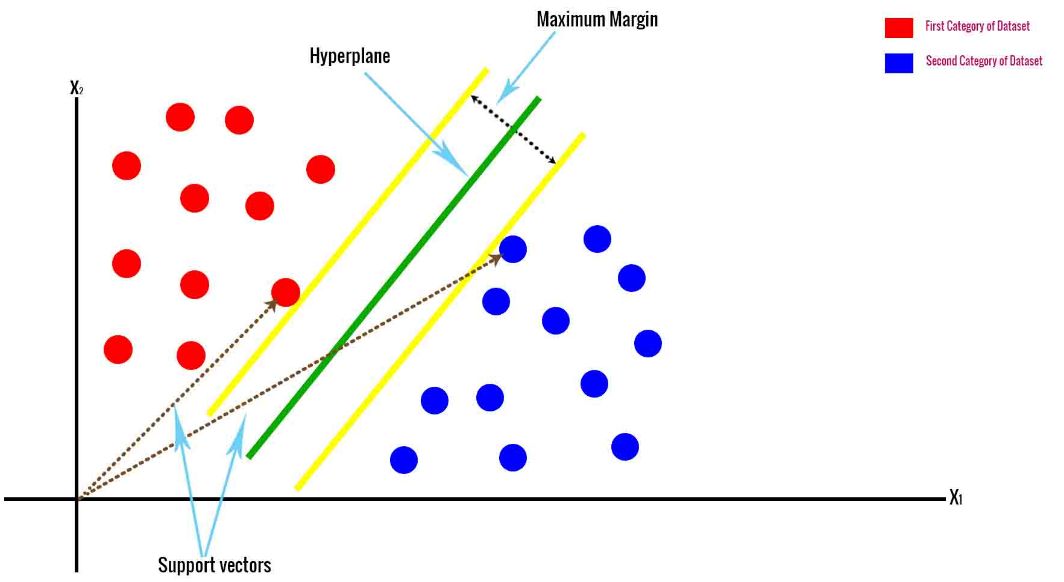
该图中,蓝色和红色的点分别代表两类别的对象,数据集通过超平面实现分类。SVM的计算过程可简单概括如下:
(1)将M个对象描述在N维变量空间中,SNM中也将对象称为向量(vector),首先使用两个最接近的类间向量计算间距,并获得最大间距(maximum margin);
(2)将最大间距分成两部分,获得超平面(hyperplane),超平面是N-1维的;超平面与两个最接近的类间向量等距,这些向量称为支持向量(support vector)。
(3)进而通过超平面实现对象分类。
由于此算法完全依赖于支持向量,因此将其命名为支持向量机。
不难看出,通过上述过程获得的超平面,实质上代表了一种线性决策面(linear decision surface)。在N维变量空
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









