





平时做开发时最烦人的除了项目不会做,恐怕就是环境依赖的问题了吧。
一个好好的项目,换个环境总是出问题,开源库一升级就挂掉,总有“坏人”搞掉自己的系统库,今天就来随便聊聊吧。
作者 | 言有三
编辑 | 言有三

如今开源生态甚好,享受着便利的同时自然也要承担一些烦恼,每一个开发人员都遇到过各种各样的库的问题,通常都跟版本有关,软硬件的都有,今天有三来随便聊聊怎么应对,仅仅只是个人习惯。
这里不是说bug噢,而是聚焦于版本依赖。
以深度学习方向为例,我们通常面对的就是Linux,Python相关的一系列深度学习开源库。
1 了解现状:有哪些烦人的小妖精
总有那么几个库,三天两天出问题。
1.1、NumPy

对于搞深度学习的人来说,bug出镜率最高的,很有可能就是它了,因为不同的开源框架,甚至是开源框架的不同版本,依赖的NumPy很有可能都不一样。
Numpy是不得不用的python科学计算基础库,被几乎所有的深度学习框架依赖,目前版本已经到1.6。
Tips:Numpy出问题,基本上就是版本问题,框架未必支持最新版,比如如下我遇到的tensorflow的问题。

tensorflow 1.10.0 has requirement numpy<=1.14.5,>=1.13.3, but you'll have numpy 1.16.2 which is incompatible.mxnet 1.4.0 has requirement numpy<1.15.0,>=1.8.2, but you'll have numpy 1.16.2 which is incompatible.解决方案就是不要用pip install numpy这样的方式安装最新版,而是加上版本号安装框架支持的版本,比如pip install -U numpy==1.14.1之类的。
1.2、CUDA/CuDNN

没个GPU恐怕深度学习是搞不起来的,而NVIDIA GPU和CUDA现在又是绑定的软硬件,CUDA有不少版本了,最新的已经是CUDA Toolkit 10.1了,而笔者的笔记本上用的还是CUDA 8.0,所以tensorflow用不了高于1.4版本。一个版本的CUDA匹配一个版本的CuDNN,具体可以查官网。
Tips:CUDA/CuDNN出问题,基本上也是版本问题,比如下面的这个,CUDA版本太低,tensorflow框架报错的问题。
libcudart.so.9.0: cannot open shared object file: No such file or directory由于CUDA已经是非常底层的硬件库了,建议没事就不要动,安装个9.0吧。
1.3、Protobuf

Google的protobuf是一种和平台、语言无关、轻便高效方便扩展的序列化数据结构的协议,被很多框架使用,比如caffe。
Tips:这位主也是闹bug的专业户,通常还是版本不对,类似于这样:
.build_release/src/caffe/proto/caffe.pb.h:12:2: error: #error This file was generated by a newer version of protoc which is incompatible with your Protocol Buffer headers. Please update your headers.这里我们要注意,说的是c版本的protobuf,就是可以运行protoc命令的,查看自己的版本很容易,protobuf --version。

Linux系统自带的protobuf通常都是2.6.1,而很多的库却依赖于高于2.6.1的版本,编译caffe需要的protoc版本需要2.6或者3.3,所以如果你装过其他依赖不同的开源库,很可能不知不觉将其环境破坏掉了。
这个时候最好的办法是自己找个目录另外弄一个,与系统的隔离,让一些包比如caffe编译的时候依赖上自己的这个库,版本的下载在此:
https://github.com/protocolbuffers/protobuf/releases2 自建环境:与别人的环境和平共处
Linux有什么好?除了安全之外,最大的莫过于帐号管理,大家可以共享一套硬件,一套基本的环境,却隔离各自的目录。
不过对于新手来说,还应该学会一件事,那就是与别人的环境隔离,就是说用自己的库,不用别人的,也不让别人用自己的库。
关于哪些库需要共享,哪些库不需要共享,我的建议是这样的(这里说的是有多个人用同一台服务器,如果是你一个人,怎么搞开心就好)。
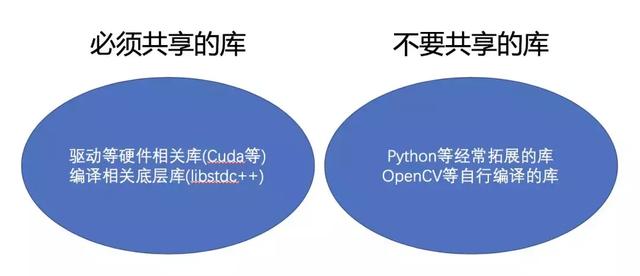
所以意思就是很明显了,自己装一套python环境,自己编译一些常用的库放在自己目录下,比如opencv,protobuf等。这样的好处有两个:
1、不是管理员也可以随意安装库了,比如python。拥有管理员权限有时候很危险的,尤其是在企业,万一一不小心误操作搞出点什么幺蛾子,轻则让大家的工作成果丢失,重则可能要辞职走人,这是一直在上演的故事。
2、可以不用担心别人更改系统环境而对自己造成影响。比如python,很多人用anaconda,就可以不使用系统的python。个人不使用anaconda,而是原生的python环境,那样可以完全掌控。
3 使用Docker:快速迁移环境

自己好不容易让环境稳定了,为了某个项目临时更改环境绝对不是一件很愉快的事情,不仅花费时间,还可能破坏稳定的系统。
这个时候,就可以上虚拟机了。关于虚拟机我们不介绍,而是介绍与之类似的Docker容器,现在运维们部署环境很多都是用Docker技术,我们这里还是针对个人用户。
相比虚拟机,我更推荐使用Docker,一,Docker容器上的程序,直接使用物理机的硬件资源,cpu、内存等利用率上有很大的优势。二,Docker镜像方便传播,使用别人的环境,找到提供好的Docker文件自动配置就行了。
如果真的需要在一个电脑上配置各种有冲突的环境,那就用Docker吧。
关于Docker技术本身这里就不做介绍,我们需要知道的是,它跟虚拟机差不多。
你可以将整个服务器的环境配置打包成一个文件随处带走,然后换一台电脑运行,这样两台电脑的环境都不会受到影响,直观理解就是这样,这也是两种我自己的用法。
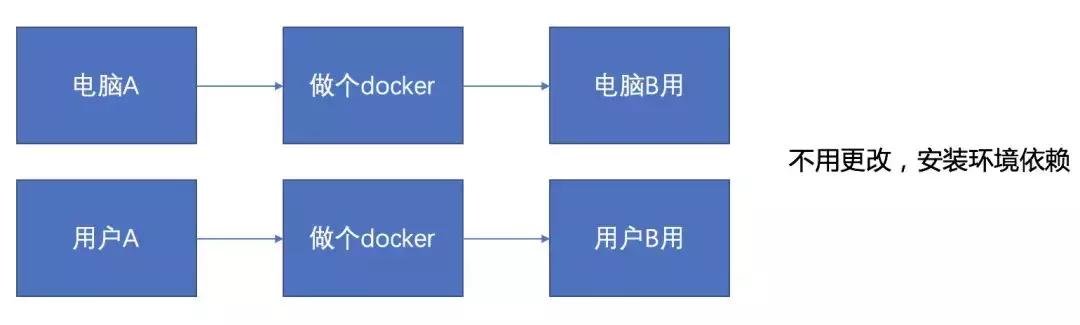
要用docker当然首先要安装,官网地址如下:
https://docs.docker.com/install/linux/docker-ce/ubuntu/(1) 以ubuntu16.04为例,首先要安装Docker命令,如果没有安装成功,可能是命令问题,去官网查看最新安装方法。或者是电脑配置太低,不支持。
//清除旧版本
sudo apt-get remove docker docker-enginesudo apt-get updatesudo apt-get install linux-image-extra-$(uname -r) linux-image-extra-virtual//添加repository sudo apt-get install apt-transport-https ca-certificates curl software-properties-commoncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"//安装最新版本sudo apt-get updatesudo apt-get install docker-ce //检查安装情况sudo docker run hello-world(2) 要使用显卡,必须安装NVIDIA Docker。因为我们就是为了跑深度学习项目,所以以后运行容器就从nvidia-docker开始run,不要再用docker命令run,那样没有GPU环境。
wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker_1.0.1-1_amd64.debsudo dpkg -i /tmp/nvidia-docker*.deb && rm /tmp/nvidia-docker*.debnvidia-docker run --rm nvidia/cuda nvidia-smi#测试安装是否成功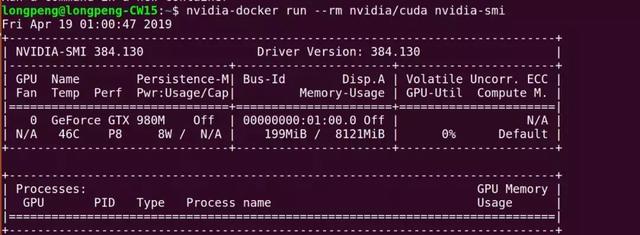
(3) 有了docker之后就可以使用或者制作自己的镜像了。
运行一个docker:
nvidia-docker run –it my_ubuntu bash如果run添加—rm选项,则是不运行后台模式,exit退出时,容器就会退出
导入镜像:
sudo nvidia-docker load --input my_ubuntu.tar 导出镜像:
docker save –o my_ubuntu.tar ubuntu_momo_multimedia(4) 挂载本机目录方便训练,这样就不用将数据放到容器中了。
nvidia-docker run –it –v /home/longpeng:/home/longpeng-outer nvidia/cuda bash/home/longpeng为本机目录, /home/longpeng-outer为挂载后的目录
(5) 定制版本,保存本次的环境,还可以进行导出。
nvidia-docker commit ID user-version 提交版本,不推荐使用该方式导出定制镜像,会出现超级大的包,有定制需求可使用dockerfile!nvidia-docker run –it user-version bash 再次登录,与上次不同的就是版本号(6) 自定义镜像/Dockerfile撰写,如果在当前目录下有一个编写正确的Dockerfile文件,就可以用docker build -t命令生成包进行发布了。
一般来说,如果这个系统安装的库都可以通过http协议下载,对外发布直接用这个dockerfile就可以了。但是有的时候,某些库只能离线加载配置,比如Matlab,无法在线用命令一键安装完,就可以发布真正的离线包。
如下就是在当前目录发布ubuntu:v3离线包,有了包以后,别人就可以加载使用。
docker build -t ubuntu:v3 .一个格式正确的dockerfile文件通常如下:
FROM longpeng-docker_opencv3LABEL maintainer " "RUN apt-get install -y cmake && pip3 install numpy && cd / && git clone https://github.com/Itseez/opencv.git && cd opencv #&& git checkout 3.2.0 #&& cd ~ #&& git clone https://github.com/Itseez/opencv_contrib.git #&& cd opencv_contrib #&& git checkout 3.2.0 #&& cd ~/opencv && mkdir build && cd build && cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D OPENCV_EXTRA_MODULES_PATH=/opencv_contrib/modules -D BUILD_EXAMPLES=ON .. && make -j4 && make install && cd / && rm -rf opencv && rm -rf opencv_contrib FROM就是从一个已有的镜像开始。RUN后面就接着要跑的命令,不需要用sudo,因为docker中默认就是root权限。可以看到在这里我们安装了numpy,cmake,编译了opencv,基本上就跟在平常的Linux环境下工作是一样的。
4 应对环境依赖的一些小情绪
大家改bug也是一步一步在实战中增强经验的,谁也不是一开始就能心平气和地接受,从小白走到大师兄的段位,心态也自然会有一些变化。
纯净的小白,好不容易找到了一个开源项目开始跑起来了,一跑之后发现没有出结果,只好干着急等人来解决。
成长为少年郎之后,就开始各种百度什么的搜索匹配答案,找到了便是万事皆休,找不到就接着找。
到了有识青年后,打开Google上去stack overflow就是一把梭,寻找点赞数最高的,有时候还翻翻github issues等地方。
到了大师兄级别,一眼就洞穿真相不需要浏览器,可能还会动起改改这个项目的心思。
不知道你现在的心态怎么样了,毕竟依赖的问题可能是一辈子的事啊。
总结
万事皆有利弊,享受着开源项目带来的便利,也要忍受它带来的麻烦,希望大家都能尽快成为游刃有余的高手,提高工作效率。















 34万+
34万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









