







最近已有不少大厂都在秋招宣讲了,也有一些在 Offer 发放阶段。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
《AIGC 面试宝典》圈粉无数!
《大模型面试宝典》(2024版) 发布!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流
最近在学习大模型 RAG 相关,看了很多市面上流行的 RAG 工业落地框架(QAnything、RAGFlow、FastGPT、智谱 RAG、AnythingLLM、MaxKB、Dify 等等),这些产品在文档处理、召回、重排、LLM处理、交互体验上各有千秋。我计划写一系列相关文章,科普技术知识 + 测试这些产品。
今天就先介绍一下网易有道开源的 QAnything,顺手撸了一个知识库问答聊天页面(源码见文末),这个源码稍作修改,即可适用 N 多支持 api 调用的纯 Chat 或基于知识库的 Chat。

QAnything 简介
QAnything 是一个基于 AI 技术的本地知识库问答系统,它允许用户将各种格式的文档(如 PDF、Word、图片等)导入到本地知识库中,然后通过自然语言对话的方式与这些文档进行交互。这种方式极大地简化了信息检索和知识管理的过程,使得用户可以更加便捷地获取所需信息。
 QAnything 的应用范围非常广泛,几乎可以在任何需要管理和检索大量文档的场景中发挥作用:
QAnything 的应用范围非常广泛,几乎可以在任何需要管理和检索大量文档的场景中发挥作用:
-
企业知识管理:帮助企业整合内部文档,提高员工获取信息的效率。
-
个人学习助手:辅助学生或研究人员快速检索和理解大量学习资料。
-
客户服务:为客服人员提供快速准确的信息检索工具,提高服务质量。
-
法律和合规:协助法律专业人士快速查找相关法规和案例。
产品特性包括:
-
多格式文档支持:QAnything 能够处理多种文档格式,包括但不限于 PDF、Word、Excel、PowerPoint、图片等。这种广泛的格式支持确保了用户可以将几乎所有类型的文档纳入知识库。
-
本地部署:与许多云端服务不同,QAnything 支持完全本地化部署。这不仅保证了数据的安全性和隐私,也使得企业可以更好地控制和管理自己的知识资产。
-
智能问答:借助先进的自然语言处理技术,QAnything 能够理解用户的问题,并从知识库中快速定位相关信息,提供准确的答案。
-
上下文理解:QAnything 不仅能回答单个问题,还能在对话过程中保持上下文的连贯性,使得交互更加自然和高效。
-
可视化界面:QAnything 提供了直观的用户界面,使得文档管理和问答交互变得简单易用。
QAnything 的优势,官网总结的非常到位:1是自研RAG引擎,跨语言语义检索准确率业界第一;2是支持全离线私有化轻松部署(提供python和docker双开源版本)
QAnything 技术亮点
QAnything 模型方面包括ocr解析、embedding/rerank,以及大模型。
QAnything 系统方面包括向量数据库、mysql数据库、前端、后端等必要的模块。
整个引擎的功能完整,用户可以直接下载,不需要再搭配其他的模块即可使用。系统可扩展性也非常好,只要硬盘内存足够,就可以一直建库,支持无上限的文档。

-
文档处理:QAnything 的此模块使用了 PDF 文件解析,具体是通过 PyMuPDF 库来完成的,该库是目前效率最高的解析工具。在解析文档内容时,无论是文本文件还是图像文件,均使用 PyMuPDF 的 get_text 方法。需要注意的是,如果图像文件中不包含文字,使用此方法时将会出现错误。
-
召回模块:QAnything 向量库使用了 Milvus 的混合检索策略(结合 BM25 全文检索和向量检索),在检索过程中不设定任何阈值,直接返回前 100 个最相关的结果(TopK =100)。
-
Rerank 模块:QAnything 精确排序使用自定义的 Rerank 模型
Reranker是Qanything的亮点,主要解决知识库数据量增加事检索退化问题。使用二阶段 rerank 重排后能实现准确率稳定增长,即数据越多,效果越好。
 QAnything 使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异,从而多领域、多语种和跨语种RAG评测(下图)中bce-embedding-base_v1和bce-reranker-base_v1的组合是SOTA。
QAnything 使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异,从而多领域、多语种和跨语种RAG评测(下图)中bce-embedding-base_v1和bce-reranker-base_v1的组合是SOTA。

QAnything 安装使用
step0: 必要条件
| 系统 | 依赖 | 要求 | 说明 |
|---|---|---|---|
| RAM Memory | >= 20GB | ||
| Linux/Mac | Docker version | >= 20.10.5 | Docker install |
| Linux/Mac | docker compose version | >= 2.23.3 | docker compose install |
| Windows | Docker Desktop | >= 4.26.1(131620) | Docker Desktop for Windows |
step1: 下载项目
git clone https://github.com/netease-youdao/QAnything.git
step2: 进入项目根目录执行启动命令
-
执行 docker compose 启动命令
-
启动过程大约需要30秒左右,当日志输出"qanything后端服务已就绪!"后,启动完毕!
cd QAnything
# 在 Linux 上启动
docker compose -f docker-compose-linux.yaml up
# 在 Mac 上启动
docker compose -f docker-compose-mac.yaml up
# 在 Windows 上启动
docker compose -f docker-compose-win.yaml up
step3: 开始体验
运行成功后,即可在浏览器输入以下地址进行体验。
- 前端地址: http://localhost:8777/qanything/
QAnything 核心功能
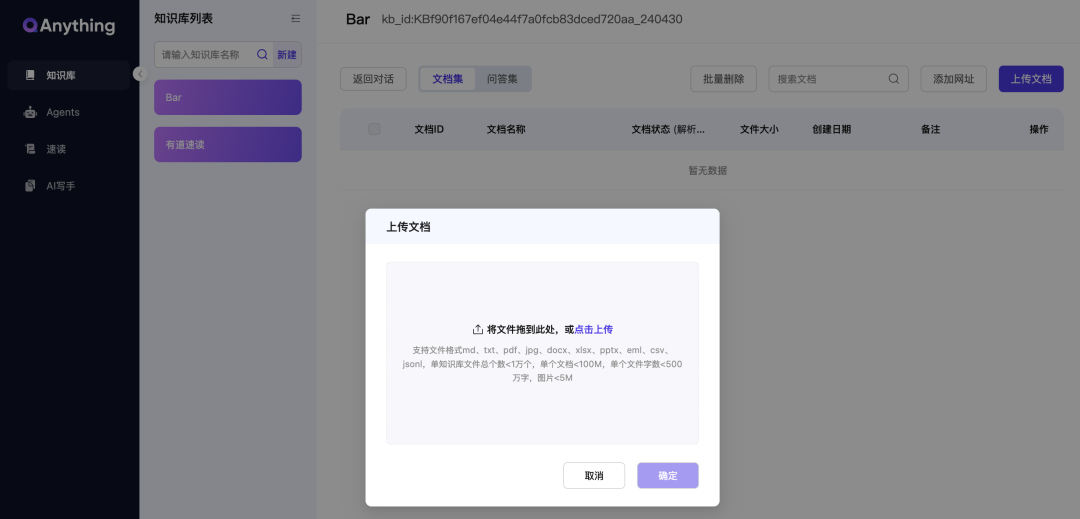
1、知识库
QAnything核心功能,分文档集和问答集。
支持:md、txt、pdf、jpg、docx、xlsx、pptx、eml、csv、jsonl,单知识库文件总个数<1万个,单个文档<100M,单个文件字数<500万字,图片<5M
对话框支持模型设置和是否开启多轮对话设置。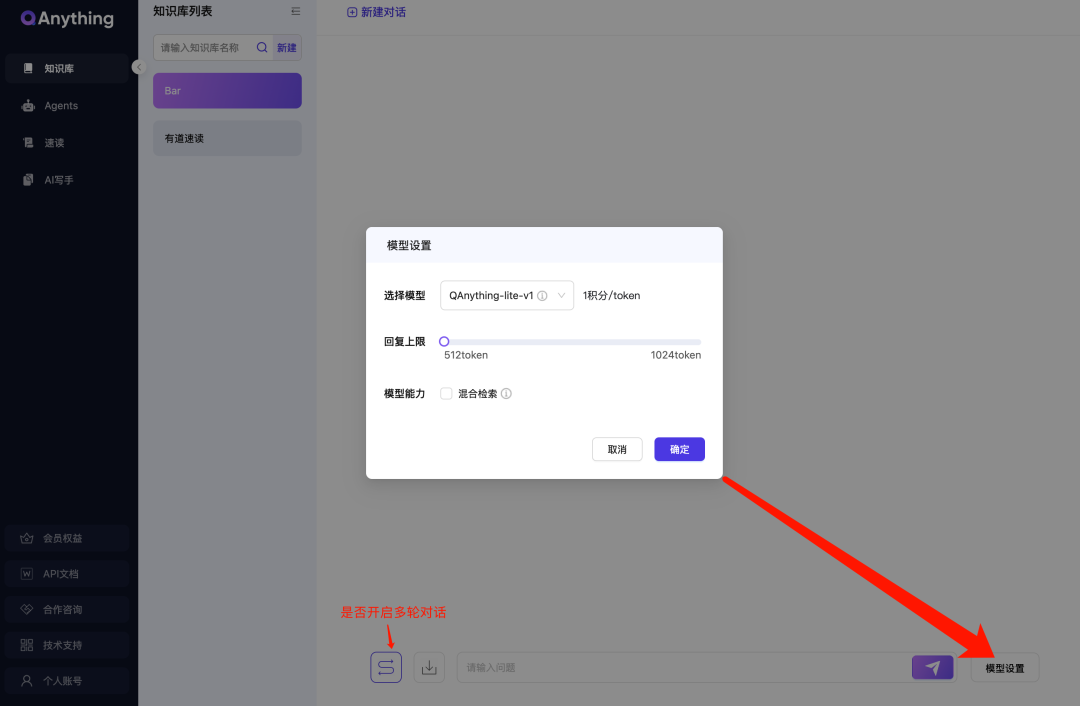
2、Agents
QAnything的Agents相对比较简单,也没有内置太多模板。
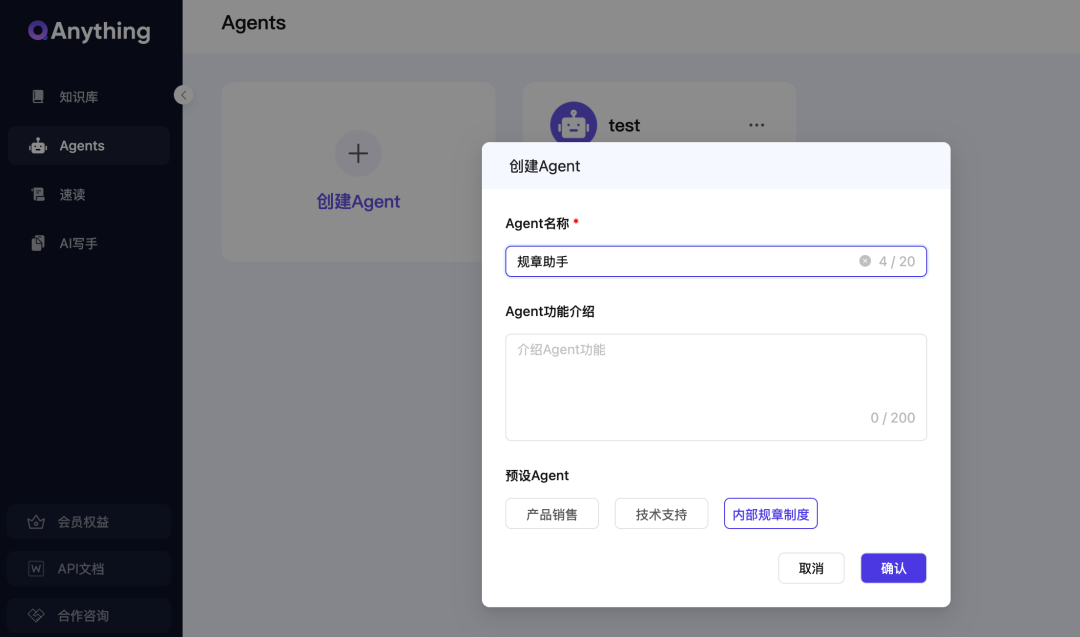
设计自由度也不高,只有角色设定、欢迎语、关联知识库、首选模型、回复上限、模型能力等选项可调。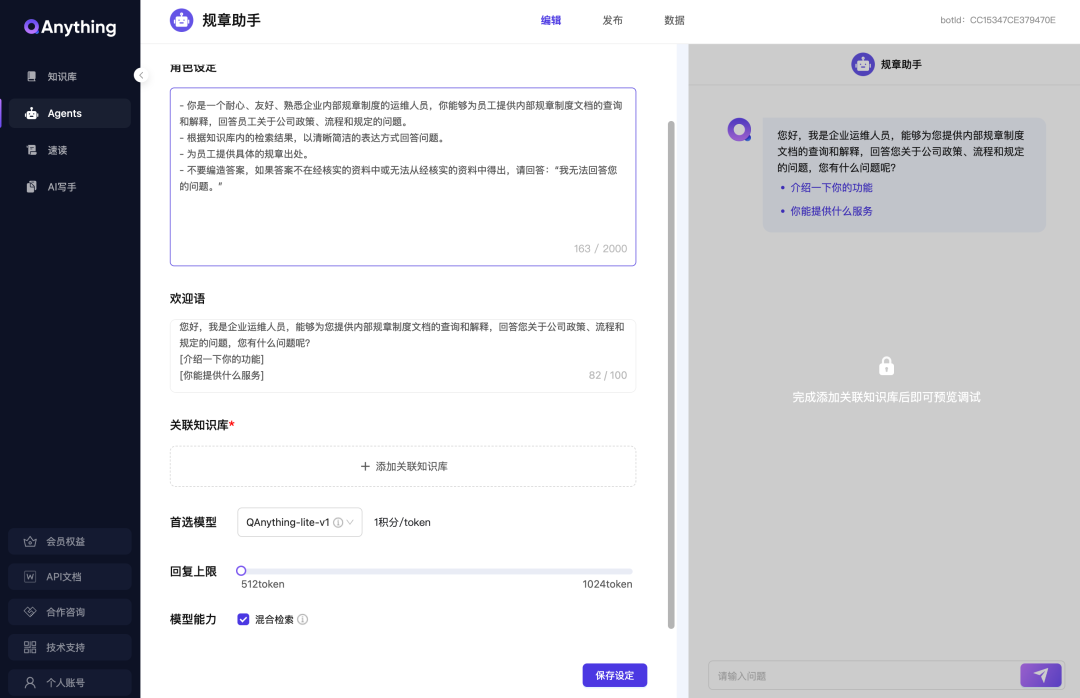
3、速读
我理解,速读是知识库问答的简化版,适合临时性阅读特定文档。
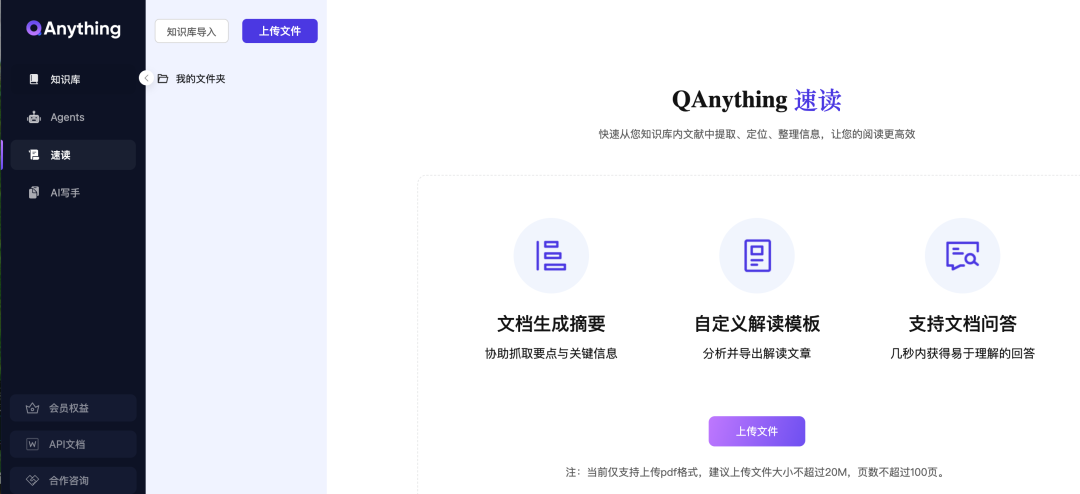
文档可以上传或知识库导入,完成文档解析后,自动完成摘要、解读、问答。
其中解读很有意思,它内置了模板,可以从文档中提炼背景、方法、实验、结论。也可以自己根据文档类型创建合适的模板。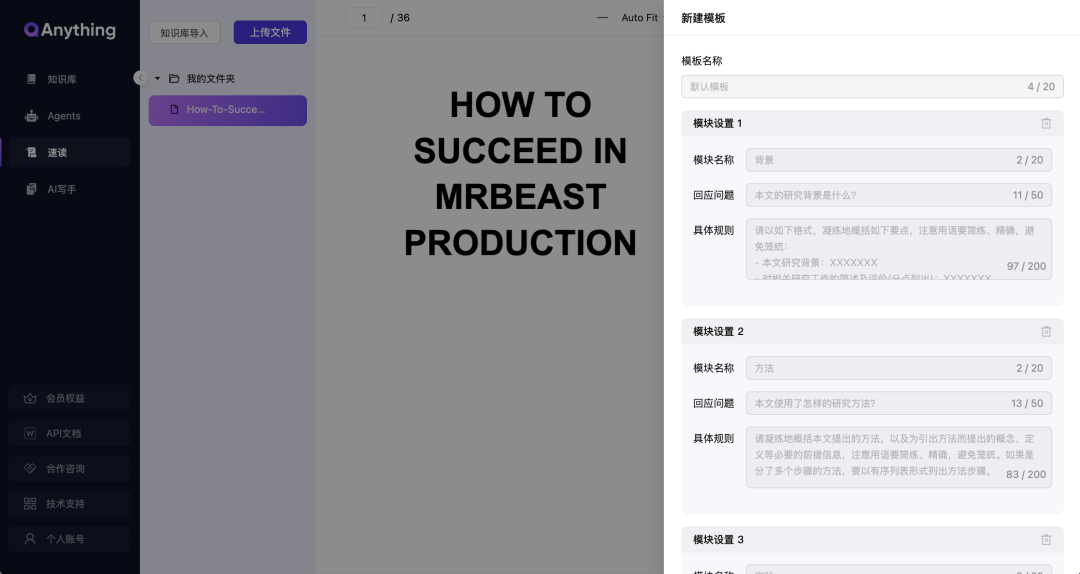
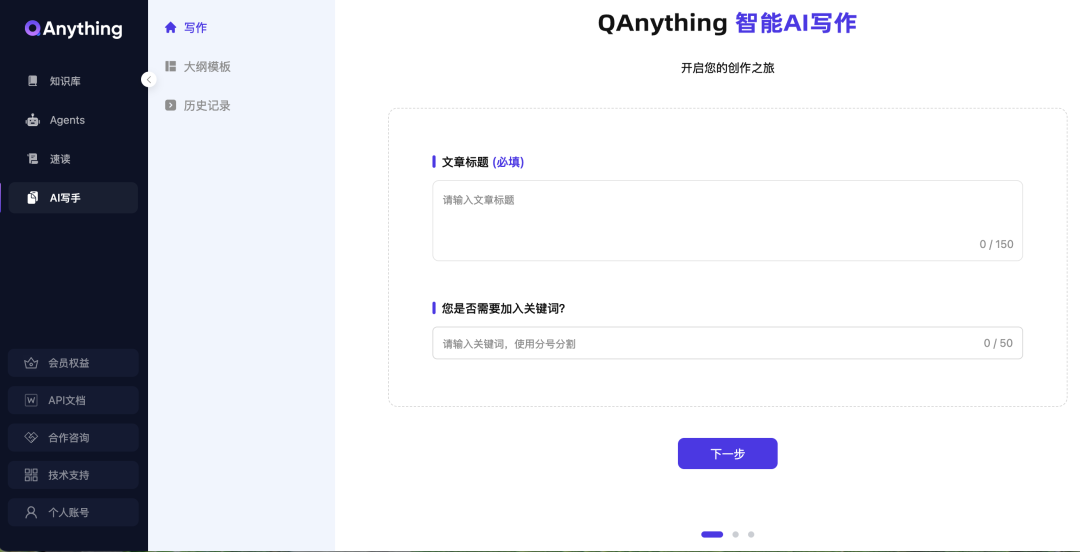
4、AI写手
智能 AI写作有几个步骤:1️⃣、直接输入标题,加入关键词;2️⃣、通过AI智能生成大纲,或使用大纲模板;3️⃣、选择是否关联知识库。
大纲模板可以手动输入/直接导入,也可以AI生成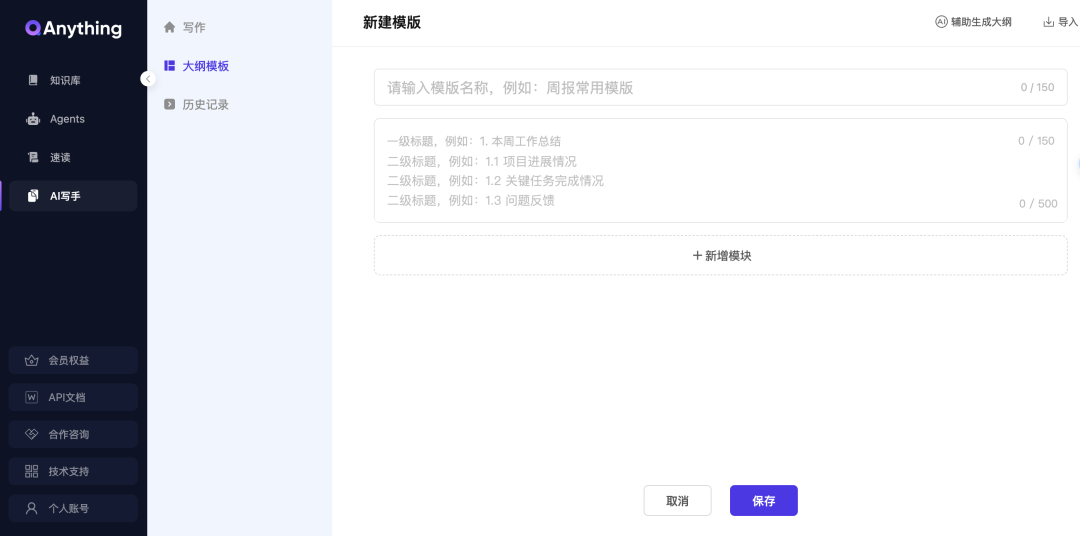
基于 QAnything 的 API 的前端应用
QAnything 平台可以很方便的调用和管理 API(知识库管理、Agent管理、流式问答),主要亮点是:
-
数据互通:QAnything 平台的数据和 API 完美互通,数据流转无障碍。
-
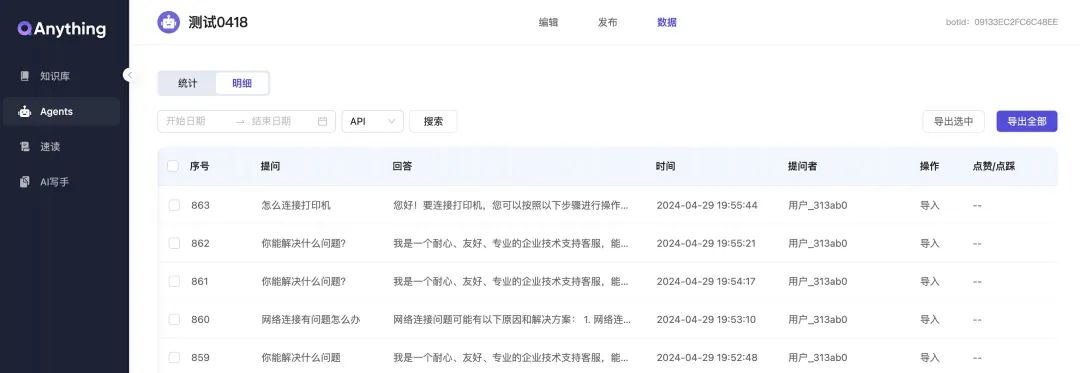
问答展示:针对 API 实际调用的问答数据进行展示,并可以人工做问答修正。
-
FAQ 管理:接口中增加了对 FAQ 的增删改查功能。
-
多平台接入:基于”问答秘钥“接口调用,可实现小程序等渠道的快捷接入。
应用场景
基于 QAnything 的 API 接口可以轻松赋能多种应用场景:
-
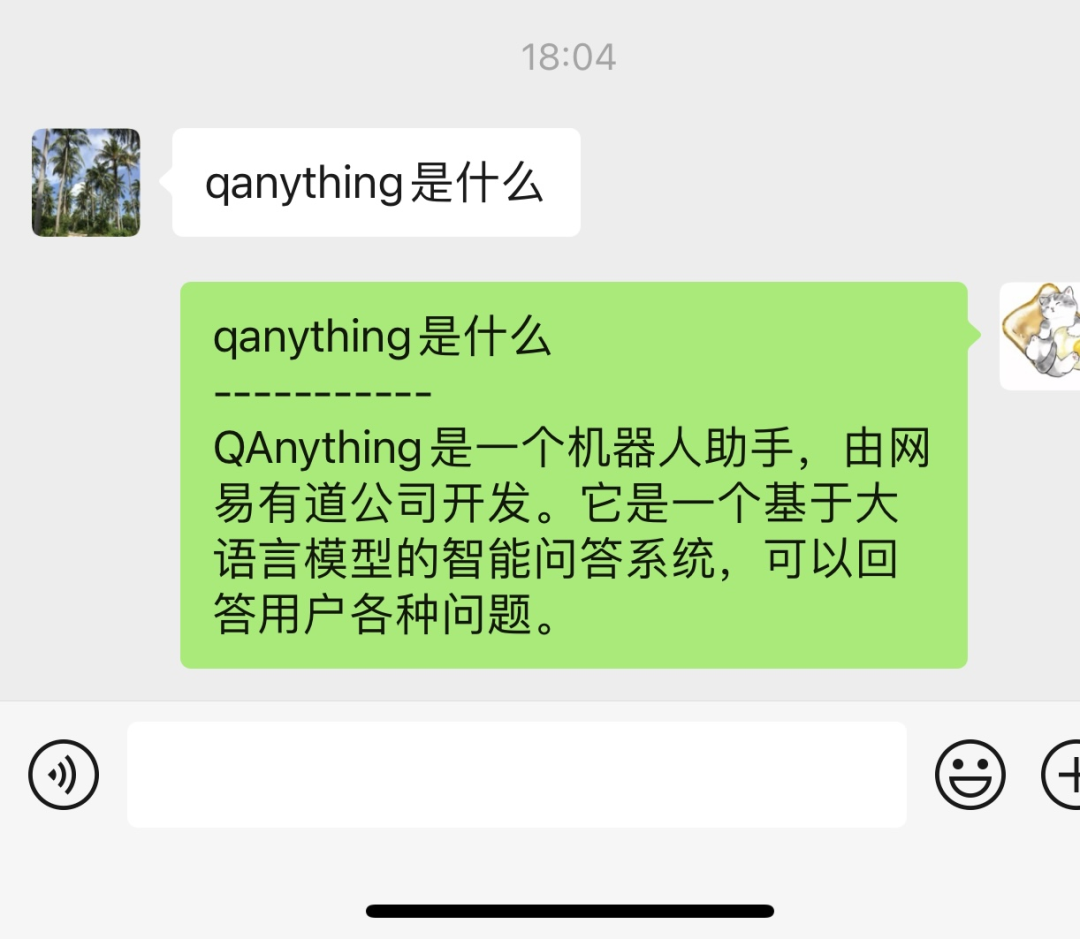
场景 1:可以在 QAnything 平台上配置管理知识库和 Agent,将配置好的 Agent 通过”问答秘钥“接入到小程序、微信、企业微信业务系统中,可以做为销售顾问、售后咨询机器人等。
-
场景 2:使用 QAnything 的”管理秘钥“来进行知识库、文件、Agent 的增删改查管理,可以搭建一个属于自己企业的知识库问答系统。
准备 api key、kb_id
开发基于 QAnything 的 API 的前端应用,需要提前准备好API。
路径:个人账号-创建api
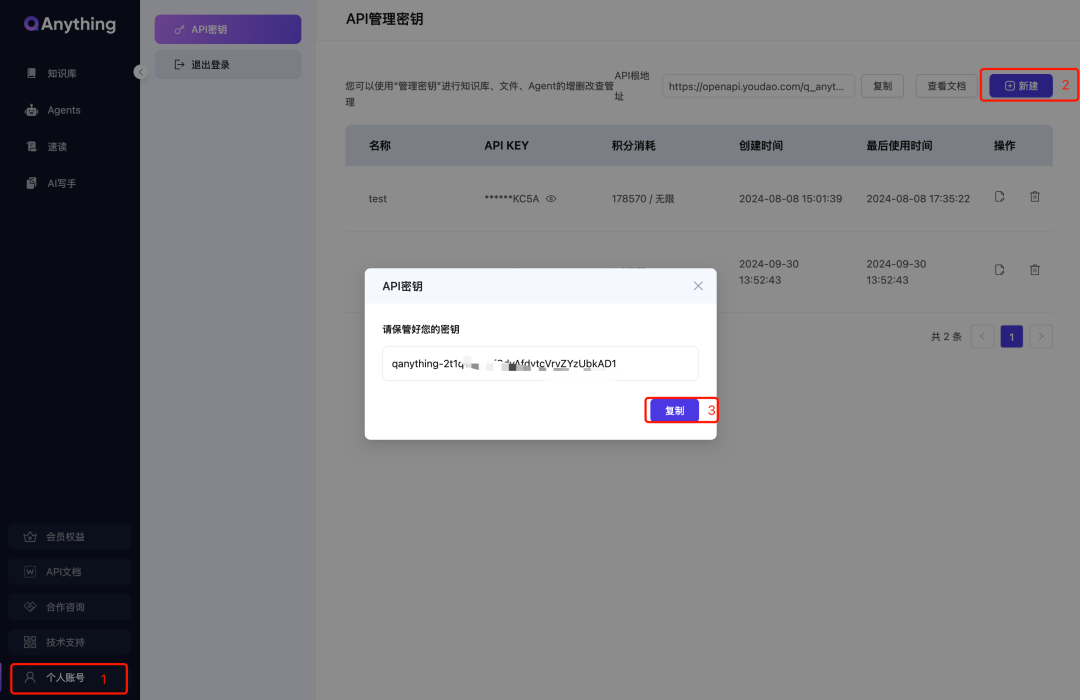
api调用地址:https://openapi.youdao.com/q_anything/api
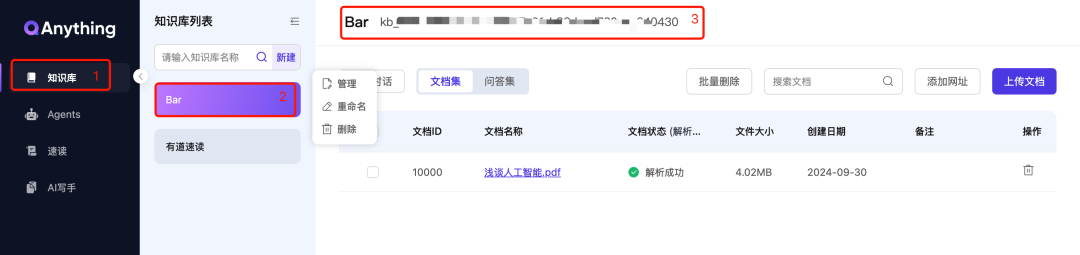
最后准备知识库kb_id,路径:知识库、鼠标点击知识库名,管理

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









