






场景需求
有一篇文章,不在人工干预下,自动提取关键词。
基本理论
文章的关键词,最初的方法多是使用词语出现的频次(Term Frequency,缩写为TF)作为衡量的标准,但在实际应用过程中会出现一些无关紧要的关键词,如“我、你、他们”,“的”,“是”。
虽然这些毫无意义的助词、代词可以通过停用词来过滤掉,仍然会有一些有意义但不是关键词的干扰词语。那么有没有一种规则可以降低一些非常通用且常见词语的权值,而增加不那么常见词语的权值呢?
因此人们提出了新的规则,逆文档频率(Inverse Document Frequency,缩写为IDF),IDF可以降低一些非常通用且常见词语的权值,而增加不那么常见词语的权值。下面将就如何在一篇文章自动提取关键词做一个项目框架流程图。
思路流程图
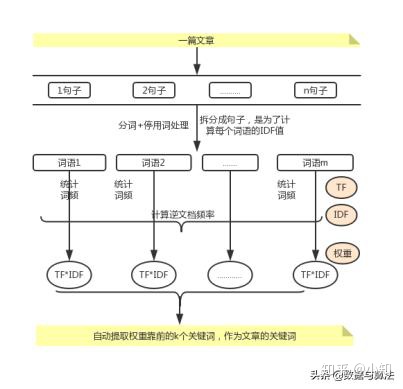
图 1:自动提取关键词原理图
计算公式
(1) 计算词频

(2) 计算逆文档频率

(3) 计算tfidf权重
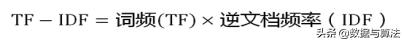
欢迎各位读者朋友们留言一起探讨学习!觉得文章对你有帮助,记得点赞、关注、转发喔!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









