






- - 本文代码具有一定通用性,适用于股票/债券组合筛选,仅作学习交流,不构成投资建议,欢迎批评指正。本文参考链接:【精选】马科维茨模型的实例验证与思考(含Python代码)_kkkkkkel的博客-CSDN博客
一. 目标:美元高息环境下对中资美元债投资组合的初步筛选
2023年临近年末,国内经济仍然处于衰退-复苏过渡期,市场投资者风险偏好未完全切换。A/H股风险溢价率虽然已经处于过往3年均值的+1/+1.5倍标准差位置,但在潜在经济增速放缓和逆全球化等长期因素影响下,风险溢价中枢已经提高,该水位下仍然未达到安全的超配时间。
相比之下,美林时钟下衰退-复苏过渡期通常也是债券牛市末期,投资级别美债(下文以中资美元债为例)具备较高的投资价值。2年期/10年期美债目前在4.88%/4.44%水平,中资美元债投资级平均利差约在174bps,距离去年10月利差最高位有108bps距离。假设12月议息会议直接加息100bps且预计将保持超过1年,平均利差恢复至去年最高位,且投资级指数按照当前隐含违约率(彭博DRSK模型)违约且回收率为零的情况下,预计2024年末仍能录得正收益(约1.86%)。
本文主要目的为对中资美元债投资级债券池进行初步筛选,寻找在特定收益率水平下方差最小的投资组合,作为构建一个较总体指数β值更高的组合以作进一步的调整。中资美元债投资级主要跟随基准利率曲线变动,指数内部价格相关性极高,在一般组合交易过程中实际难以起到提高组合夏普比率的效果。
方法上是通过对中资美元债投资级债券池进行蒙特卡洛模拟,建立马科维茨均值-方差组合模型并筛选出有效前沿上的组合。本文通过对约600只存续时间超过1年,且久期在1年以上的中资美元债投资级债券进行筛选,随机选取20只债券构成等权重组合,随机生成n组该等组合,并保留相同收益率下方差最低的组合。
需注意,1)由于债券的特性,该债券组合内部相关性较高,因此该方法下仅能获得相对而言夏普比率更好的方案;2)此处筛选证券标的受到前述对久期的限制所以筛选面收窄,近两年发行量滑坡的城投主体存续债券久期总体下降,导致筛选面在这类型主体的覆盖相对不高。
二.回测结果:小幅提高风险收益率,收益主要来源于更高票息
(一)组合表现回测
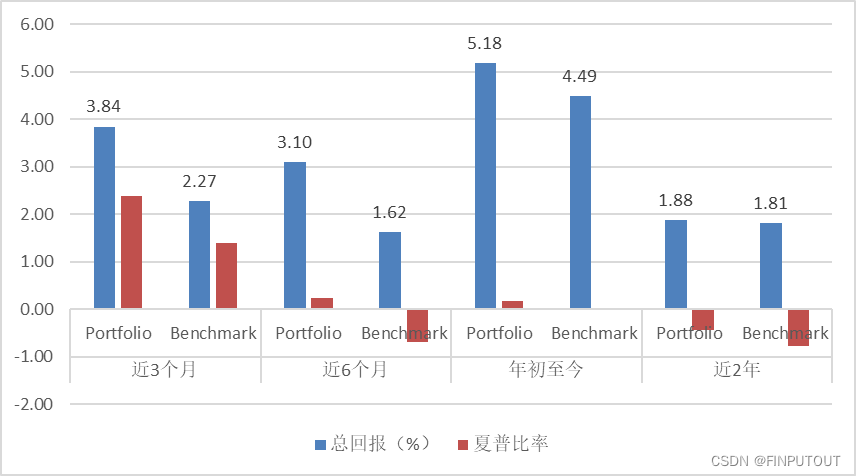
先看初筛下其中一个债券组合的回测结果,过往两年内不同时间节点看,组合较指数均有比较显著的回报提升和夏普比率的提升。在久期与指数接近的情况下,近3个月/6个月/1年在收益率上带来1.57/1.48/0.69个百分点的提高,夏普比率明显早于指数回正。虽然组合使用的数据是一年期内数据,但在两年周期内表现均出现了一定风险收益提高的效果。收益的提高当然还是主要来自总体风险的提高,相较于指数的β值在1.48-1.50间,这也是因为选取组合时选取了有效前沿上收益相对较高的点。
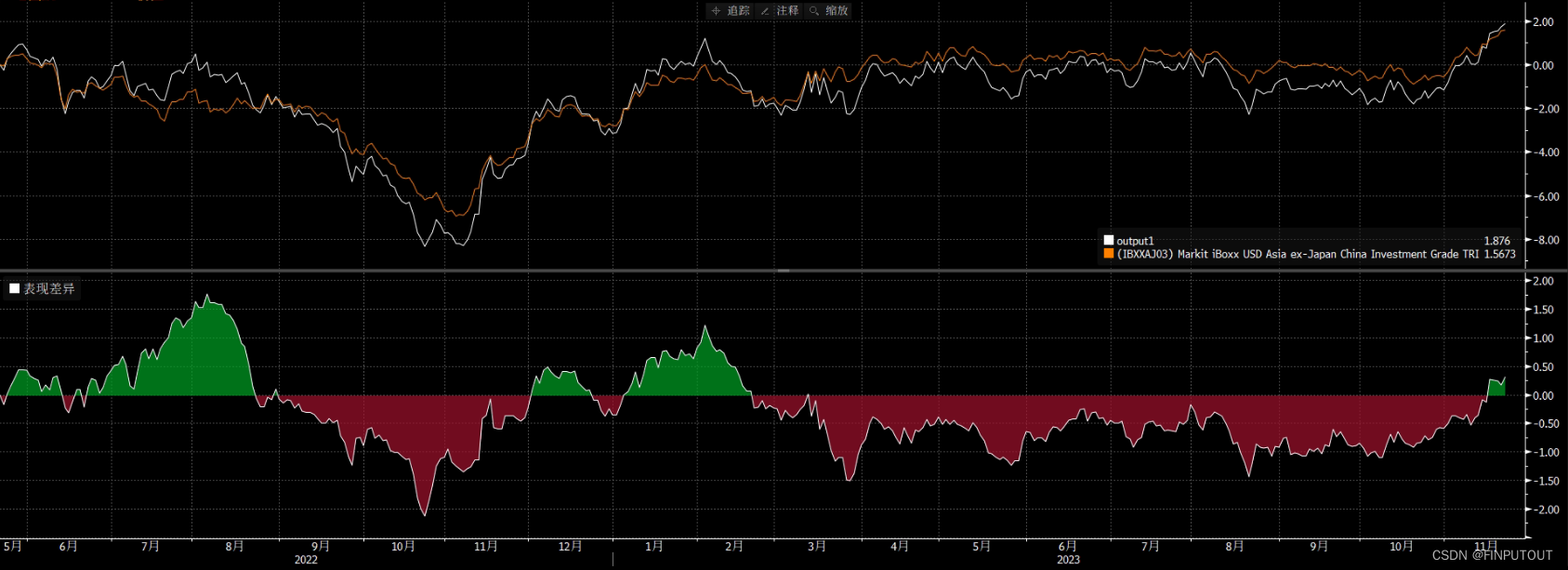
净价上组合显著跟随指数,息票差异是最主要的收益差异来源,组合平均息票高于指数1.07个百分点(总回报高于指数1.57个百分点),这也符合息票与预期收益成显著正相关关系的历史经验(Mosrgan Stanley Research:What Will Markets Return? 2024 Edition)。
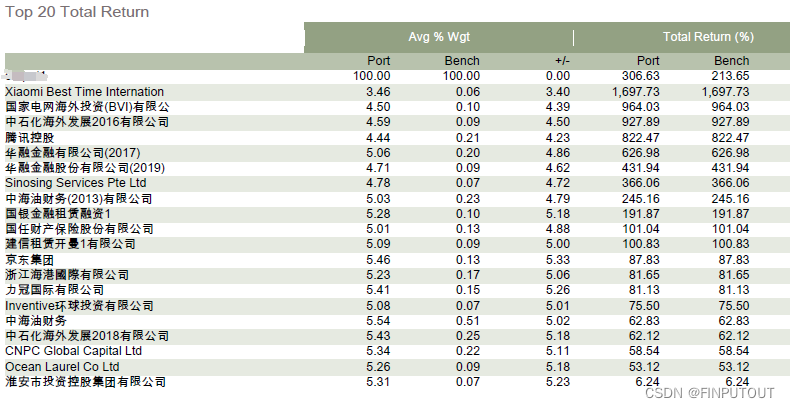
(二)组合标的
由于筛选过程中我们默认使用了等权重,因此组合中20只债券权重均在5%附近。组合中华融等金融公司的非永续债券、优质城投也是实际中资美元债投资中的受关注标的。
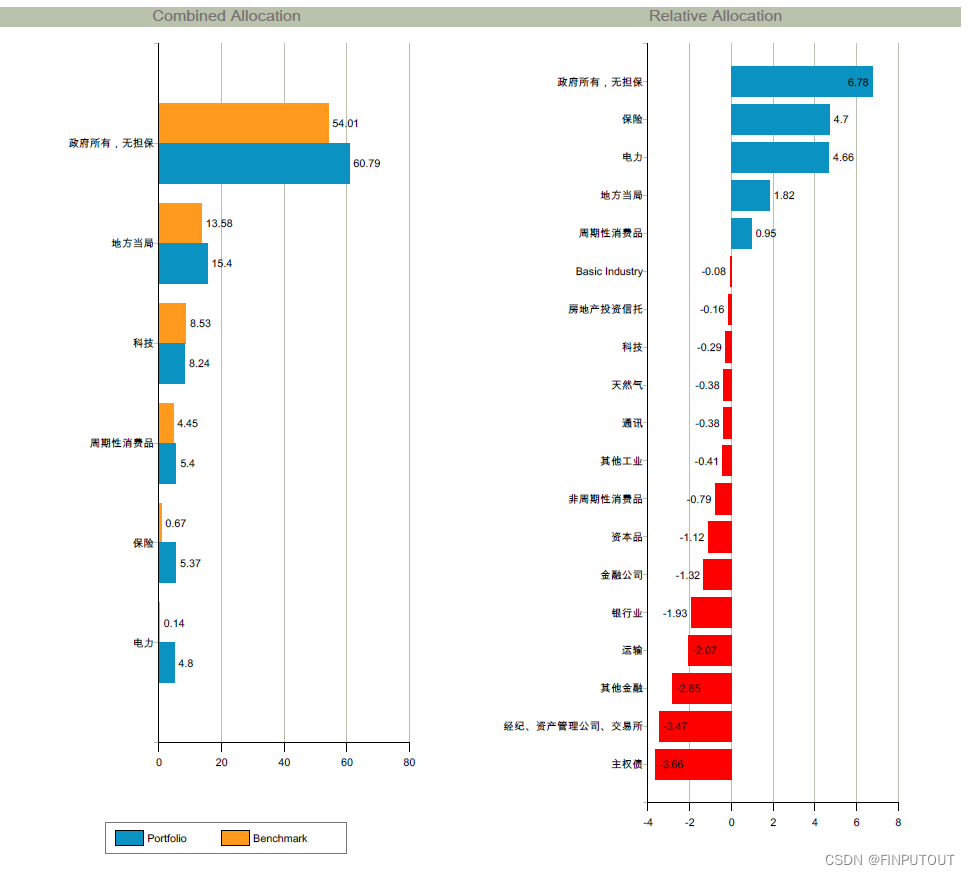
组合在行业分布上相较于基准指数有所取舍:更集中于国央企/城投类企业债券,国央企相关债券占比60.79%,略高于指数的54%;组合没有选取主权、券商和银行的信用质量更优债券(可能因部分银行AT1未被纳入投资级指数考量)。
三.具体方法
(一)数据
本文采用的数据为IBOXX中资美元债投资级指数(截至2023年10月)各成分证券近一年的每周末净价(中价)的,并按把应计利息加入至每周末净价从而构成复权后全价。该等处理是因为需要考虑到交易策略下债券的收益分别来自应计利息和价差变化,处理后所得的复权后全价价差变化率即可直接对应为收益率。
成分处理上考虑到数据完整性和可操作性,筛选成分债中存续时间超过1年,且久期在1年以上的中资美元债投资级债券,合计456只。
(二)组合筛选方法
主要方法是通过随机生成大量债券组合从而找到收敛的有效前沿。以任意20只债券为一组构成等权重的债券组合,随机生成20万个这样的组合,并保留在同一收益率下波动率最低的组合,从而找到一组有效边界上的结果。
导入数据,并填充空缺日期的价格数据,债券作为OTC交易,价格数据可能存在少量空缺,因为投资级OTC交易活跃度不及股票,价格波动率有限,所以这里采取向下填充。
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 从数据文件中读取证券价格数据
excel_data = pd.read_excel(r'C:\Users\Admin\Desktop\IGBOND\IGMAT3.xlsx')
# 向下填充价格数据
excel_data = excel_data.fillna(method='ffill')
# 创建时间序列
dates = pd.date_range(start='2023-01-01', periods=len(excel_data), freq='D')
# 将时间序列设置为索引
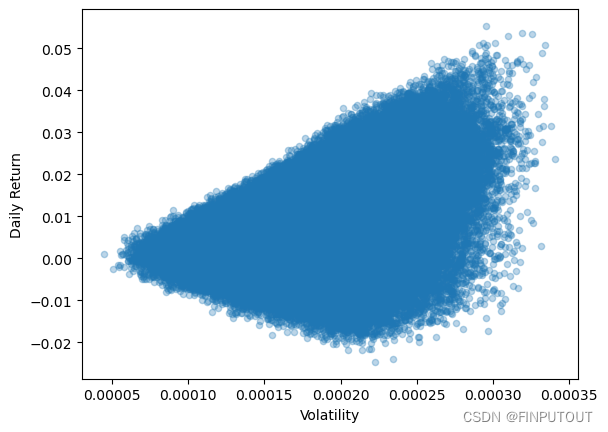
excel_data.set_index(dates, inplace=True)对所有证券附等权重,并随机构建200000个以20个为一组的债券组合,计算组合的波动率和平均每日收益率并生成散点图。马科维茨均值方差模型常被用于组合内的权重调整,其实这种组合下相当于允许部分证券的权重降至0。
# 对每个证券进行等权重赋值
normalized_data = excel_data.div(excel_data.sum(axis=1), axis=0)
# 构建200000个组合
num_portfolios = 200000
portfolio_list = []
for _ in range(num_portfolios):
selected_securities = np.random.choice(normalized_data.columns, size=20, replace=False)
portfolio = normalized_data[selected_securities]
portfolio_list.append(portfolio)
# 计算每个组合的波动率和每日收益率
volatility_list = [portfolio.mean().std() for portfolio in portfolio_list]
daily_return_list = [portfolio.mean().pct_change().mean() for portfolio in portfolio_list]
# 创建新的表
result_df = pd.DataFrame({
'Portfolio Name': [f'Portfolio {i+1}' for i in range(num_portfolios)],
'Volatility': volatility_list,
'Daily Return': daily_return_list
})
# 显示图形
result_df.plot('Volatility','Daily Return',kind='scatter',alpha=0.3)
plt.show()最终得到的散点图为子弹型,符合常见的均值方差模型特征。经测试,本次所用的底层数据大概在10000次随机组合已经有比较明显的结果收敛现象。
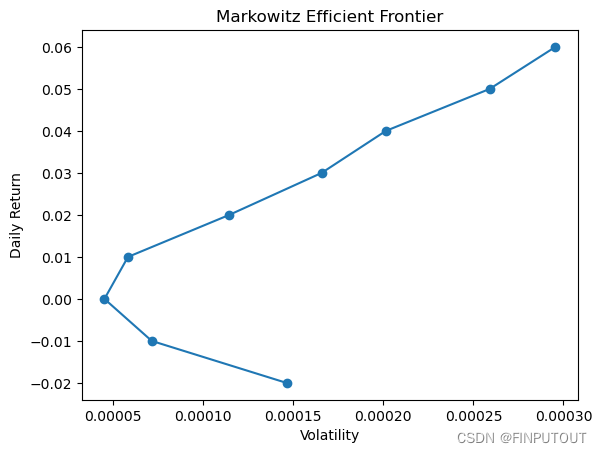
降低收益率数据的小数点位数方便对比,仅保留相同收益率下波动率最低的点,从而得到有效边界,输出为折线图。
# 收益率位数均降至小数点后两位,方便对比
result_df['ReturnsRound'] = round(result_df['Daily Return'], 2)
# 找出每个相同Daily Return下最低的Volatility点
min_volatility_points = result_df.groupby('ReturnsRound')['Volatility'].min()
# 画出马科维茨曲线
plt.plot(min_volatility_points, min_volatility_points.index, marker='o', linestyle='-')
plt.title('Markowitz Efficient Frontier')
plt.xlabel('Volatility')
plt.ylabel('Daily Return')
# 显示图形
plt.show()
从有效边界上的结果输出对应的债券组合,并输出到Excel中,这里可以获得多个可选组合。
# 将 min_volatility_points 转换为 DataFrame
min_volatility_points_df = min_volatility_points.reset_index()
# 将 result_df 和 min_volatility_points_df 按照 ReturnsRound 列进行合并
merged_df = pd.merge(result_df, min_volatility_points_df, on= 'ReturnsRound')
# 筛选出波动率相等的行,即为最低波动率的组合
lowest_volatility_portfolios = merged_df[merged_df['Volatility_x'] == merged_df['Volatility_y']]
# 打印结果
print(lowest_volatility_portfolios)
# 从lowest_volatility_portfolios中提取Portfolio Name列
portfolio_names = lowest_volatility_portfolios['Portfolio Name']
securities_dict = {}
# 遍历组合名称列表
for portfolio_name in portfolio_names:
# 获取组合对应的索引
portfolio_index = int(portfolio_name.split()[-1]) - 1
# 获取组合包含的证券名称
securities = portfolio_list[portfolio_index].columns
securities_dict[portfolio_name] = securities
# 将字典转换为 pandas Series
securities_series = pd.Series(securities_dict, name='Securities')
# 创建一个新的 DataFrame 来存储证券名称
securities_df = pd.DataFrame(securities_series.tolist(), index=securities_series.index)
# 创建一个新的 DataFrame 来存储结果
final_df = pd.DataFrame({
'Portfolio Name': securities_series.index,
'Volatility': result_df.set_index('Portfolio Name').loc[securities_series.index, 'Volatility'],
'ReturnsRound': result_df.set_index('Portfolio Name').loc[securities_series.index, 'ReturnsRound']
})
# 将证券名称的 DataFrame 添加到结果 DataFrame 中
final_df = pd.concat([final_df, securities_df], axis=1)
# 重置索引
final_df = final_df.reset_index(drop=True)
final_df.to_excel(r'C:\Users\Admin\Desktop\IGBOND\output4.xlsx') 此处选取其中一个组合进行后续结果验证,由于每个收益率仅会对应波动率最低的点,因次可以以收益率值为索引导出对应组合,并生成相关性矩阵。从矩阵可以看到组合证券间普遍仍然存在显著的正相关关系,但加入了如阿里巴巴/中海外发展/国家电网等相关性相对较低的标的。
# 找到要查找的日收益率值
target_return = 0.04
# 找到该日收益率值对应的最小波动率值
target_volatility = min_volatility_points[target_return]
# 找到该日收益率值对应的最小波动率值的索引
target_index = min_volatility_points[min_volatility_points == target_volatility].index[0]
# 找到该日收益率值对应的最小波动率值的组合
target_portfolio = portfolio_list[volatility_list.index(target_volatility)]
# 计算相关性矩阵
df_corr = target_portfolio.corr()
# 绘制df_corr的矩阵热力图
plt.figure(1)
sns.heatmap(df_corr, annot=False, vmax=1, square=True)
# 调整字体大小
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 调整图像大小
plt.figure(figsize=(10, 8))
# 显示图片
plt.show() 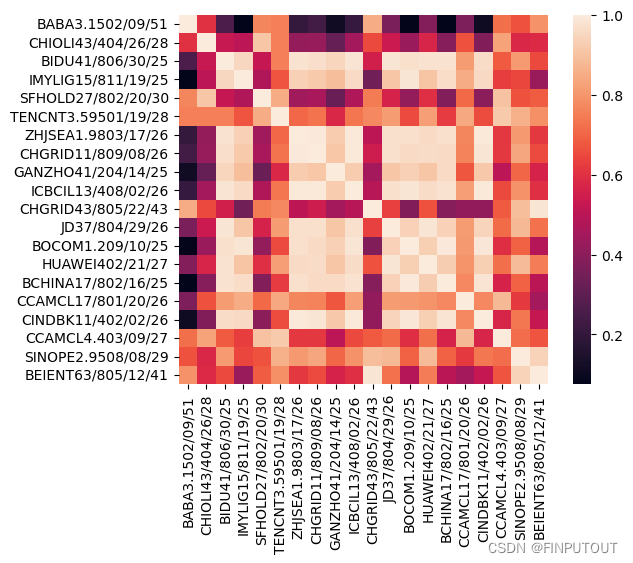
四.模型限制:从过去看未来的局限性
本文主要是体现一种思路,我们可以从有效边界上的组合进一步分析寻找降低模型波动性,提高风险收益率的方向,如加入互联网/优质国央企地产,同等情况下倾向于高票息等。但该模型是基于过往一年数据找到夏普比率更优的组合,并非是对未来走势的预测,即便在该模型下对时间分段拆分来回测可以获得较好的结果,逻辑上仍然存在过去推未来的局限性。
组合也没有对内部不同标的进行持仓占比的调整,从最简单的角度去修改上述思路其实也可以找到更不同的持仓比例,如在代码开头统一权重的基础上允许同一标的的叠加,那么更符合组合要求的标的被加入篮子的次数自然可能增加。
我们发现最终的组合结果分布上并没有出现向单个或单类主体过度集中的情况。该方法未对行业/个体设置集中度限制,这是因为在中资美元债投资级指数的各成分互相之间价格就存在极高的相关性。通过增加不同主体债券的投资从而分散风险,达到“鸡蛋不放在同一个篮子里”的效果本身可能就是一个伪命题。

















 7776
7776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









