







腾讯互娱Turing Lab从创建开始,每周在内部进行分享读书会,对业界的技术研究和应用进行讨论。在此通过公众号形式把相关有趣内容也推送给对新技术和业界趋势感兴趣的朋友。
和大量的所谓技术公众号不同,尽管以AI为重心,但我们的分享不局限于AI论文,而是涉猎所有前沿技术领域,和自动化流程、数据处理、人工智能、架构设计相关的有趣内容均会分享,希望各位在周末闲暇时有空阅读了解。
分享人:许家誉 腾讯互娱 研究员
1. 概述强化学习的主要作用是在复杂未知情况下,控制agent实现某个具体的目标。强化学习可以解决做出一系列决策的问题,例如训练算法完成某个游戏,如何控制机器人在复杂的环境中运动等。强化学习和标准的监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。
OpenAI Gym是一个用于开发和比较强化学习算法的工具。它无需对agent的先验知识,并且采用python作为主要开发语言,因此可以简单的和TensorFlow等深度学习库进行开发集成,可以直观的将学习结果用画面直观的战术出来。例如Gy'm cartpole-v0游戏就是模拟倒立摆,通过左右调整使其不落下,传统我们是使用pid等算法进行控制实现。
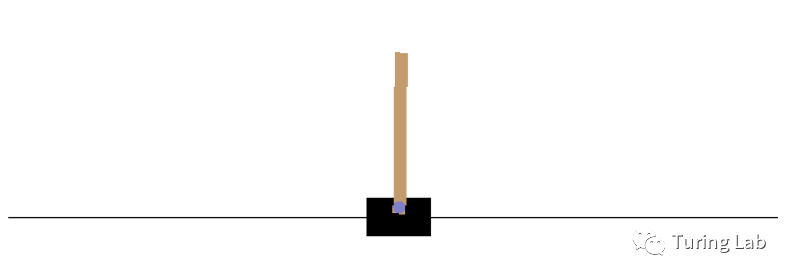
安装gym
pip3 install gymGym安装完成后,可以通过以下例子使其运行起来。其中env.step根据action行为返回observation,reward,done, info四个值。Observation是一个四维的向量,表示小车的位置,小车的速度,木棒的角度,木棒的速度。每一个环境都有 action_space,observation_space,他们的类型都是Space。Discrete空间允许随机确定的非负数,在这个案例中就是0,1,如果我们随机进行控制,系统只能维持约10 time steps的平衡。
import gymenv = gym.make("CartPole-v0") #使用CarPole环境进 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









