







更多AI大模型应用开发学习内容,尽在聚客AI学院
一、AI大模型开源生态体系解析
1.1 核心组成与演进趋势
开源技术栈分层架构:
基础层:PyTorch/TensorFlow/JAX →
框架层:Transformers/DeepSpeed →
工具层:Hugging Face Hub/Datasets →
应用层:Diffusers/Accelerate关键数据:
-
Hugging Face Hub模型数量:50万+
-
社区开发者:200万+
-
日均API调用量:20亿+
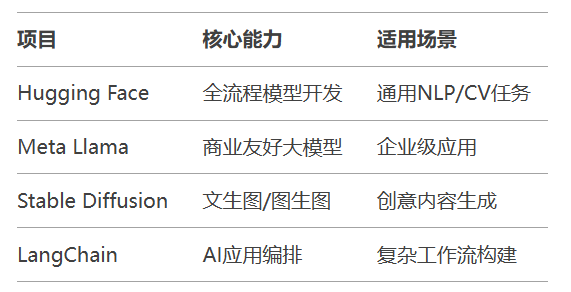
典型开源项目对比:
二、Hugging Face核心操作全解
2.1 环境搭建与配置
全平台开发环境方案:
# Conda环境(推荐)
conda create -n hf python=3.10
conda activate hf
pip install "transformers[torch]" datasets accelerate
# Docker镜像
docker pull huggingface/transformers-pytorch-gpu
docker run -it --gpus all -v $(pwd):/workspace huggingface/transformers-pytorch-gpu
# 验证安装
python -c "from transformers import pipeline; print(pipeline('text-generation', model='gpt2')('Hello,')[0]['generated_text'])"关键环境变量配置:
# 设置模型缓存路径
export HF_HOME=/data/huggingface
# 指定镜像加速
export HF_ENDPOINT=https://hf-mirror.com
# 设置代理
export http_proxy=http://127.0.0.1:7890
export https_proxy=http://127.0.0.1:78902.2 Hub仓库操作命令大全
模型管理:
# 下载模型
huggingface-cli download gpt2 --cache-dir ./models
# 上传模型
huggingface-cli upload your-username/your-model ./model_path/
# 搜索模型
huggingface-cli search "text classification" --sort downloads
# 模型转换
python -m transformers.onnx --model=bert-base-uncased --feature=sequence-classification数据集操作:
# 加载数据集
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc")
# 推送数据集
dataset.push_to_hub("your-username/your-dataset")三、Transformers编码开发实战
3.1 全流程开发模板
基础模型调用:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tokenizer("Artificial intelligence is", return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0]))自定义训练循环:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
fp16=True,
logging_steps=100
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()3.2 高级功能开发
模型量化部署:
from transformers import AutoModelForSequenceClassification, pipeline
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
pipe = pipeline("text-classification", model=quantized_model)四、数据处理与工具集应用
4.1 数据预处理规范
文本数据处理:
from datasets import load_dataset
from transformers import AutoTokenizer
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def preprocess(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length"
)
processed_dataset = dataset.map(preprocess, batched=True)图像数据处理:
from torchvision.transforms import Compose, Resize, ToTensor
transform = Compose([
Resize((224, 224)),
ToTensor(),
lambda x: x.repeat(3,1,1) if x.shape[0]==1 else x
])
dataset = load_dataset("cifar10")
dataset = dataset.map(lambda x: {"image": transform(x["img"])})4.2 核心工具集应用
加速训练:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, dataloader = accelerator.prepare(
model, optimizer, dataloader
)
for batch in dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()模型解释:
from transformers import pipeline
from interpret_text.explainers import UnifiedInformationExplainer
explainer = UnifiedInformationExplainer(model)
explanation = explainer.explain_instance(
"This movie is fantastic!",
tokenizer=tokenizer,
n_important_tokens=5
)五、工业级开发最佳实践
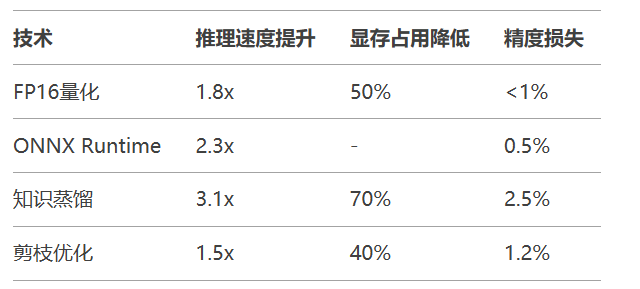
5.1 模型优化指标对比
5.2 持续集成方案
# .github/workflows/hf-ci.yml
name: HF CI
on: [push]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: 3.10
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run tests
run: pytest tests/
- name: Model Validation
env:
HF_TOKEN: ${{ secrets.HF_TOKEN }}
run: |
python validate.py \
--model bert-base-uncased \
--dataset glue mrpc掌握Hugging Face生态需要持续实践,更多AI大模型应用开发学习内容,尽在聚客AI学院。


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











