







## 1:什么是Batch Normalization
Batch Normalization,简称BN,译为“批归一化”,是神经网络中一种特殊的层。Normalization是一个统计学中的概念,我们可以叫它归一化或者规范化,它并不是一个完全定义好的数学操作(如加减乘除)。它通过将数据进行偏移和尺度缩放调整,在数据预处理时是非常常见的操作,在网络的中间层如今也很频繁的被使用。
论文链接:Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
## 2:为什么要使用 Batch Normalization 解决(internal covariate shift)
什么是internal covariate shift:是由于每层输入的分布在训练过程中随着前一层的参数发生变化而发生变化,因此训练深度神经网络很复杂。由于需要较低的学习率和仔细的参数初始化,这会减慢训练速度,并使训练具有饱和非线性关系的模型变得非常困难。我们将这种现象称为内部协变量偏移(internal covariate shift),并通过归一化层输入来解决该问题。
内部协变量偏移(internal covariate shift)产生原因: 在神经网络中,前面的网络对输入数据的处理变化会导致后面网络层接受的数据分布发生变化,连续的变化会在在多层数据网络中各层之间参数变化引起的数据分布发生变化的现象,下面公式所示
: L层的数据变换
随着梯度下降的进行,每一层的参数 与
都会被更新,那么
的分布也就发生了改变,进而
也同样出现分布的改变。而
作为第 L+1 层的输入,意味着 L+1 层就需要去不停适应这种数据分布的变化,这一过程就被叫做Internal Covariate Shift。
Feature scaling 问题:Batch Normalization效果类似
-
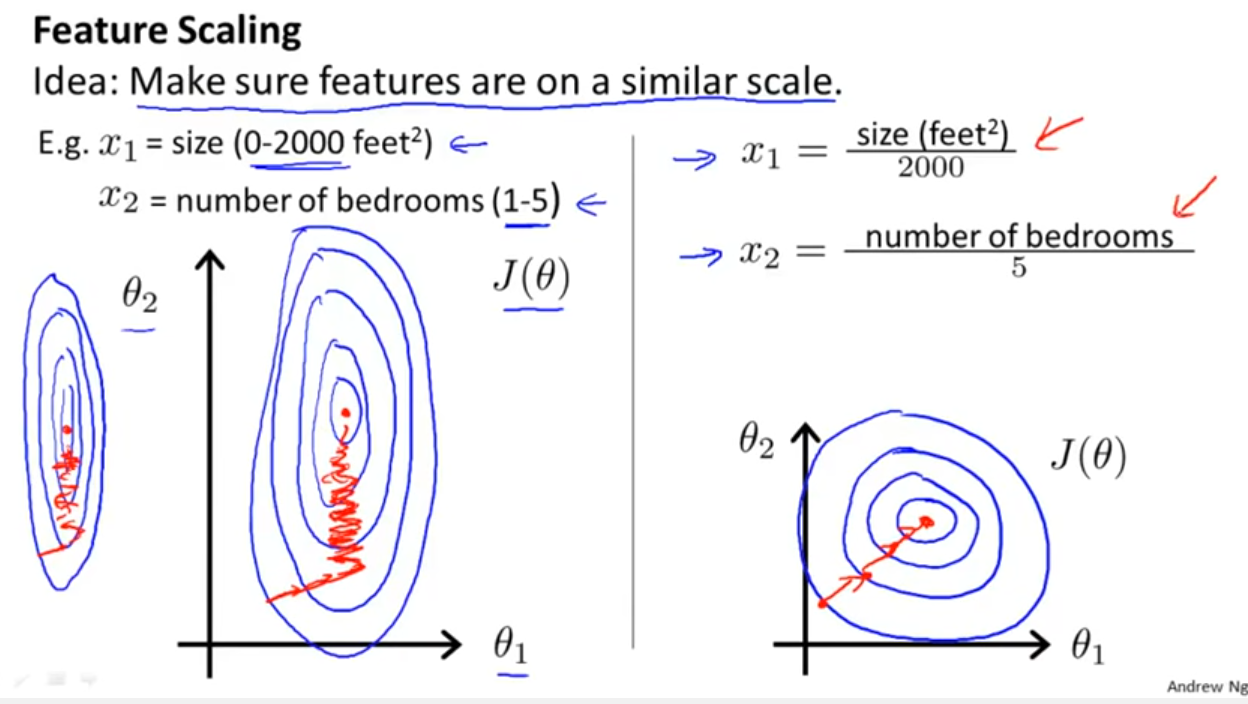
特征间的单位(尺度)可能不同,比如身高和体重,比如摄氏度和华氏度,比如房屋面积和房间数,一个特征的变化范围可能是[1000,10000][1000,10000],另一个特征的变化范围可能是[−0.1,0.2][−0.1,0.2],在进行距离有关的计算时,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
-
原始特征下,因尺度差异,其损失函数的等高线图可能是椭圆形,梯度方向垂直于等高线,下降会走z路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快,如下图所示,图片来自Andrew Ng。
## 3:Batch Normalization 计算过程
Train前向传播过程: 需要学习的参数
- 假设是L卷积层的输出是
- 求输入数据的均值
- 求输入数据的方差
- 对输入数据进行归一化处理, 得到BN层输入
其中
是为了避免分母为0。
- BN层的输出
之后就是进入激活函数内部了。
Test前向传播使用过程:但是当在投入使用时,往往只是输入一个样本,没有所谓的均值μ 和标准差σ2,那该怎么办呢?此时,网络中使用的均值μβ 是计算所有batch值的平均值得到,标准差σ2采用每个batch σ2的无偏估计得到。
Train反向传播过程:下图是论文给出的推到过程

第一步:分别对 求偏导数 对公式二的分解

第二步:对公式三的分解

第三步:对公式四的分解

参考: Batch Normalization学习笔记及其实现 - 知乎
## 4:Batch Normalization的作用以及优缺点
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
BN通过规范化与线性变换使得每一层网络的输入数据的均值与方差都在一定范围内,使得后一层网络不必不断去适应底层网络中输入的变化,从而实现了网络中层与层之间的解耦,允许每一层进行独立学习,有利于提高整个神经网络的学习速度。
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
在不使用BN层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过normalize操作可以让激活函数的输入数据落在梯度非饱和区,缓解梯度消失的问题;另外通过自适应学习 与 又让数据保留更多的原始信息。
(4)BN具有一定的正则化效果
在Batch Normalization中,由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
另外,原作者通过也证明了网络加入BN后,可以丢弃Dropout,模型也同样具有很好的泛化效果。
缺点:
从上面可以看出,batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。
这一个特性,导致batch normalization不适合以下的几种场景。
(1) batch非常小,比如训练资源有限无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
(2) rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。不过,困难并不意味着没人做,事实上现在仍然可以使用的,不过这超出了咱们初识境的学习范围。
















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









