







注:本文首发【极市平台】:比CNN更强有力,港中文贾佳亚团队提出两类新型自注意力网络|CVPR2020
hszhao/SANgithub.com

该文是香港中文大学贾佳亚老师团队投于
CVPR2020的一篇关于动态滤波器卷积的文章。对动态滤波器卷积实现不明白的小伙伴可能看该文会非常费力。本文首先在不改变原文意思的基础上进行简单的翻译与介绍,在后续的文章中本人将从另一个角度对该文进行解析并进行复现和转换,敬请期待。
Abstract
近期的研究表明:自注意力可以作为图像识别模型的基础模块而存在。作者探索了自注意力机制的变种并对其在图像识别中的有效性进行了评价。作者考虑了两种形式的自注意力机制:(1) pairwise self-attention,它是标准点积注意力的扩展,本质上是一组操作;(2) patchwise self-attention一种比卷积更强有力的的操作,其对应的模型明显优于标准卷积版本。作者还通过实验验证了所提表达方式的鲁棒性,并证实自注意力网络从鲁棒性和泛化性能方面均优于标准卷积网络。
看完上面这一段介绍,大家有没有感觉看的云里雾里,不知所云。这到底是个什么鬼?没关系,下面的原文翻译会让你更加的不知所云,拭目以待!
Method
在卷积网络中,网络中的OP有两个作用:(1) 特征聚合(feature aggregation),对局部近邻特征采用核参数进行加权得到输出特征;(2) 特征变换(feature transformation),它有后接线性映射以及非线性函数达成(即BatchNorm+ReLU)。
作者认为:前述两个功能可以解耦。如果可以采用一种特殊的机制进行特征聚合,那么采用感知器(它包含线性映射与非线性函数)进行逐点特征变换。作者主要聚焦于特征聚合部分进行研究。其实说白了就是尝试提出一种特殊的机制替代标准卷积。
常规卷积通过固定核进行特征聚合,即全图权值共享,不会随特征内容而自适应变化,同时参数量会随着聚合特征数量增加而增加。鉴于此,作者提出几种特征聚合机制并构建了一个高性能图像识别框架(它交错执行特征聚合(自注意力)和特征变换(逐点感知器))。
作者探索了两种类型的自注意力机制:(1) pairwise self-attention;(2) patchwise self-attention.
Pairwise Self-attention
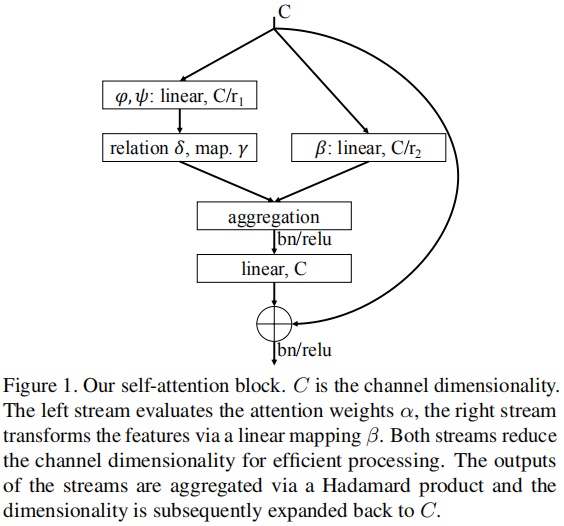
首先,给出Pair Self-attention的定义:
其中,
Hadamard乘积
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









