







1. Bagging
Bagging基于自助采样法,给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集中,使得下次采样仍肯能被选中,这样经过m次操作,我们得到m个样本的采样集,照这样,我们可采样出T个含m个训练样本的采样集,然后基于每个采样集训练一个基学习器,再将这些学习器进行结合。
在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。
2. 随机森林 RF
RF是以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择,即传统决策树在划分属性时是在当前节点的属性集合中选择一个最优属性,而在RF中,对基决策树的每个节点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
2.1 对于基学习器的“多样性”
Bagging 仅通过样本扰动,即通过初始训练集采样而来不同,RF不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛华性能可通过个体学习器之间的差异度的增加而进一步提升。
样本的随机抽样可以用均匀分布的随机数构造,如果有
l
l
l个训练样本,只需要将随机数变换到区间
[
0
,
l
−
1
]
[0, l-1]
[0,l−1]$,每次抽样时生成该区间的随机数,然后选择编号为该随机数的样本。对特征分量的采样时无放回抽样,可以用洗牌算法实现。
2.2 随机森林对于缺失值的处理
参考随机森林
根据随机森林创建和训练的特点,随机森林对缺失值的处理:
- 给缺失值预设估计值,比如数值型特征,一般选择中位数或众数作为估计值;
- 根据估计的数值,建立随机森林,把所有的数据放进随机森林跑一遍,记录每一组数据在决策树中分类的路径;
- 引入相似度矩阵,几率数据之间的相似度,判断哪组数据与缺失数据路径相似;
- 如果缺失值是类别变量,通过权重投票得到新的估计值,如果是数值型变量,通过加权平均得到新的估计值,如此迭代,直到得到稳定的估计值。
2.3 包外误差
训练每一棵决策树时都有部分样本未参与,利用未参与训练的样本作为测试样本,测试的误差称为包外误差(out of bag, 缩写为oob)。包外误差基本与交叉验证得到的误差一致,因此,包外误差可以作为泛华误差的估计。对于分类问题,包外误差定义为被错分的包外样本数与总包外样本数的比值。对于回归问题,所有包外样本的回归误差和除以包外样本数。
2.4 变量的重要性
随机森林可以在训练过程中输出变量的重要性,即哪个特征对分类更有用。实现的方法有两种:Gini法和置换法。
2.4.1 置换法的原理
如果某个特征很重要,那么改变样本的特征值,那样本点的预测结果就很容易出现错误。也就是说,这个特征值对分类结果很敏感。反之,如果一个特征对分类不重要,随便改变它对分类结果没多大影响。
对于分类问题,在训练某决策树时在包外样本中随机挑选两个样本,如果要计算某一变量的重要性,则置换这两个样本的这个特征值。假设置换前样本的预测值为
y
∗
y^*
y∗, 真实标签为
y
y
y, 置换之后的预测值为
y
π
∗
y^*_{\pi}
yπ∗。变量的重要性计算公式为
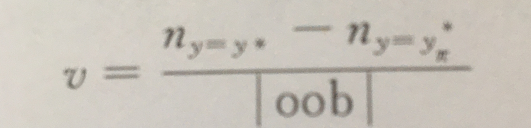
其中,
∣
o
o
b
∣
|oob|
∣oob∣为包外样本数,
n
y
=
y
∗
n_{y=y^*}
ny=y∗为包外集合中在进行特征置换之前被正确分类的样本数,
n
y
=
y
π
∗
n_{y=y^*_{\pi}}
ny=yπ∗为包外集合中特征置换之后被正确分类的样本数。二者的差反映的是置换前后的分类正确率的变化。
对于回归问题,变量重要性的计算公式为
ν
=
∑
i
∈
o
o
b
e
x
p
(
−
(
y
i
−
y
i
∗
m
)
2
)
−
∑
i
∈
o
o
b
e
x
p
(
−
(
y
i
−
y
i
,
π
∗
m
)
2
)
∣
o
o
b
∣
\nu = \frac{\sum_{i\in oob} exp(-(\frac{y_i-y_i^*}{m})^2)-\sum_{i\in oob} exp(-(\frac{y_i-y_{i,\pi}^*}{m})^2)}{|oob|}
ν=∣oob∣∑i∈oobexp(−(myi−yi∗)2)−∑i∈oobexp(−(myi−yi,π∗)2)
其中,
m
m
m为所有训练样本中标签绝对值的最大值。除以这个最大值是为了数值计算的稳定。
上面定义的均为单棵决策树的变量的重要性,计算每棵决策树的重要性之后,对该值取平均值得到随机森林的变量重要性,再对该值归一化,得到最终的重要性。
2.5 结合策略
假定集成包含T个基学习器 h 1 , h 2 , . . . , h T {h_1,h_2,...,h_T} h1,h2,...,hT,其中 h i h_i hi在示例 x x x的输出为 h i ( x ) h_i(x) hi(x)。
1. 平均法
对于数值型输出 h i ( x ) ∈ R h_i(x)\in R hi(x)∈R,最常见的结合策略是使用平均法
1.1 简单平均法
H ( x ) = 1 T ∑ i = 1 T h i ( x ) . H(x) = \frac{1}{T}\sum_{i=1}^{T}h_i(x). H(x)=T1i=1∑Thi(x).
1.2 加权平均法
H
(
x
)
=
∑
i
=
1
T
w
i
h
i
(
x
)
.
H(x) = \sum_{i=1}^{T}w_ih_i(x).
H(x)=i=1∑Twihi(x).
其中
w
i
w_i
wi是个体学习器
h
i
h_i
hi的权重,通常
w
i
>
=
0
,
∑
i
=
1
T
w
i
=
1.
w_i>=0, \sum_{i=1}^{T}w_i=1.
wi>=0,∑i=1Twi=1.
一般而言,在个体学习器性能相差较大时宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
2. 投票法
对分类任务来说,学习器 h i h_i hi将从类别标记集合 c 1 , c 2 , . . . , c N {c_1, c_2, ...,c_N} c1,c2,...,cN预测出一个标记,最常见的结合策略是使用投票法。我们将 h i h_i hi在样本x上的预测输出表示为一个 N N N维向量 ( h i 1 ( x ) ; h i 2 ( x ) ; . . . ; h i N ( x ) ) (h_i^1(x);h_i^2(x);...;h_i^N(x)) (hi1(x);hi2(x);...;hiN(x)),其中 h i j ( x ) h_i^j(x) hij(x)是 h i h_i hi类别标记 c j c_j cj上的输出。
2.1 绝对多数投票法
H
(
x
)
=
{
c
j
,
i
f
∑
i
=
1
T
h
i
j
(
x
)
>
0.5
∑
k
=
1
N
∑
i
=
1
T
h
i
k
(
x
)
;
r
e
j
e
c
t
,
o
t
h
e
r
w
i
s
e
.
H(x)= \begin{cases} c_j, if \sum_{i=1}^T h_i^j(x) > 0.5\sum^N_{k=1}\sum^T_{i=1}h^k_i(x); \\ reject, otherwise. \end{cases}
H(x)={cj,if∑i=1Thij(x)>0.5∑k=1N∑i=1Thik(x);reject,otherwise.
即若某标记得票过半数,则预测为该标记,否则拒绝预测。
2.2 相对多数投票法
H
(
x
)
=
c
a
r
g
m
a
x
j
∑
i
=
1
T
h
i
=
1
j
(
x
)
.
H(x)=c_{\underset{j}{argmax}}\sum^T_{i=1}h^j_{i=1}(x).
H(x)=cjargmaxi=1∑Thi=1j(x).
即预测为得票最多的标记,若同时有多个标记最高票,则从中随机选取一个。
2.3 加权投票法
H
(
x
)
=
c
a
r
g
m
a
x
j
∑
i
=
1
T
w
i
h
i
=
1
j
(
x
)
.
H(x)=c_{\underset{j}{argmax}}\sum^T_{i=1}w_ih^j_{i=1}(x).
H(x)=cjargmaxi=1∑Twihi=1j(x).
与加权平均类似,
w
i
w_i
wi是
h
1
h_1
h1的权重,通常
w
i
>
=
0
,
∑
i
=
1
T
=
1.
w_i>=0, \sum^T_{i=1}=1.
wi>=0,∑i=1T=1.
3. 学习法
即通过另一个学习器来进行结合,个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习器。
Stacking是学习法的代表,Stacking先从初始数据集训练出初级学习器,初级学习器的输出被当作用于训练次级学习器的样例输入特征,而初始样本的标记仍被当作样例标记。。
在训练阶段,一般通过使用交叉验证或者留一法的方式,用训练初级学习器未使用的样本产生次级学习器的训练样本。以下以
k
k
k折交叉验证为例
初始训练集
D
D
D被随机划分为
k
k
k个大小相似的集合
D
1
,
D
2
,
.
.
.
,
D
k
.
D_1, D_2,...,D_k.
D1,D2,...,Dk.令
D
j
D_j
Dj和
D
‾
j
=
D
−
D
j
\overline{\text{D}}_j=D-D_j
Dj=D−Dj分别表示第
j
j
j折的测试集和训练集。给定
T
T
T个初级学习算法,初级学习器
h
t
(
j
)
h^{(j)}_t
ht(j)通过在
D
‾
j
\overline{\text{D}}_j
Dj上使用第
t
t
t个学习算法而得。对
D
j
D_j
Dj中每个样本
x
i
x_i
xi,令
z
i
t
=
h
t
j
(
x
i
)
,
z_{it}=h_t^{j}(x_i),
zit=htj(xi),则由
x
i
x_i
xi所产生的次级训练样例的示例部分为
z
i
=
(
z
i
1
,
z
i
2
,
.
.
.
,
z
i
T
)
z_i=(z_{i1}, z_{i2}, ..., z_{iT})
zi=(zi1,zi2,...,ziT),标记部分为
y
i
y_i
yi. 于是,在整个交叉验证过程结束后,从这
T
T
T个初级学习器产生的次级训练集是
D
′
=
(
z
i
,
y
i
)
i
=
1
m
,
D^{'}={(z_i, y_i)}^m_{i=1},
D′=(zi,yi)i=1m,然后
D
′
D^{'}
D′将用于训练次级学习器。
参考:
- 《机器学习》周志华
- 《机器学习与应用》雷明















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









