







step1: 导入库
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
step2 :读取数据
data = pd.read_csv('./dataset/Income1.csv')
step2 :scatter
plt.scatter(data.Education, data.Income)
plt.xlabel('Education')
plt.ylabel('Income')
plt.show()
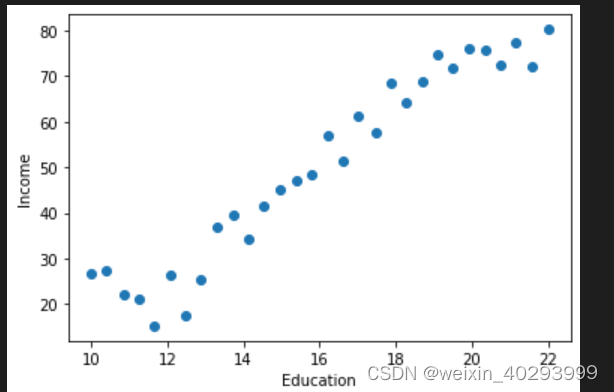
看这个形状,太适合线性回归了忍不住啊。
step 3: 构建模型,数据和损失函数 训练
from torch import nn
model = nn.Linear(1, 1)
loss_fn = nn.MSELoss()
# 数据预处理,并且统一数据类型
X = torch.from_numpy(data.Education.values.reshape(-1, 1)).type(torch.FloatTensor)
Y = torch.from_numpy(data.Income.values.reshape(-1, 1)).type(torch.FloatTensor)
opt = torch.optim.SGD(model.parameters(), lr=0.0001)
for epoch in range(5000):
for x, y in zip(X, Y):
y_pred = model(x)
loss = loss_fn(y, y_pred)
opt.zero_grad()
loss.backward()
opt.step()
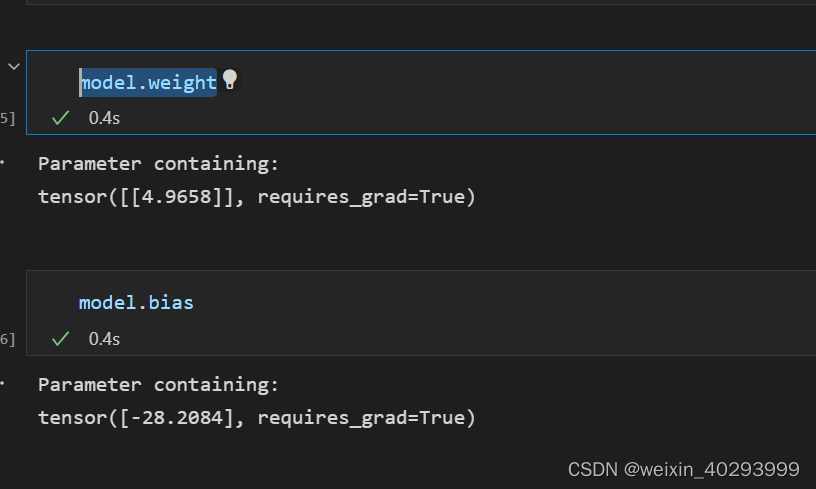
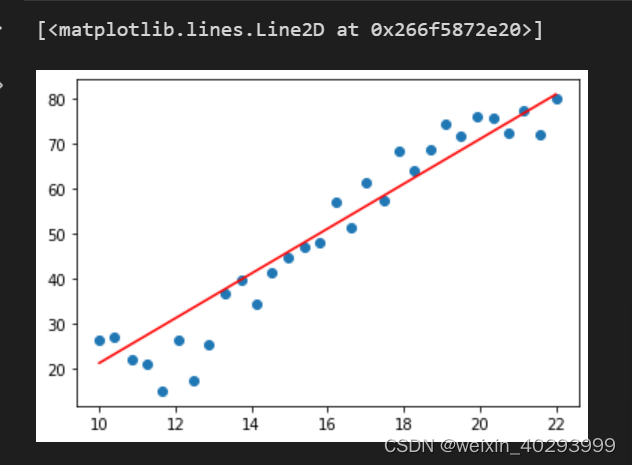
model.weight
最终效果:
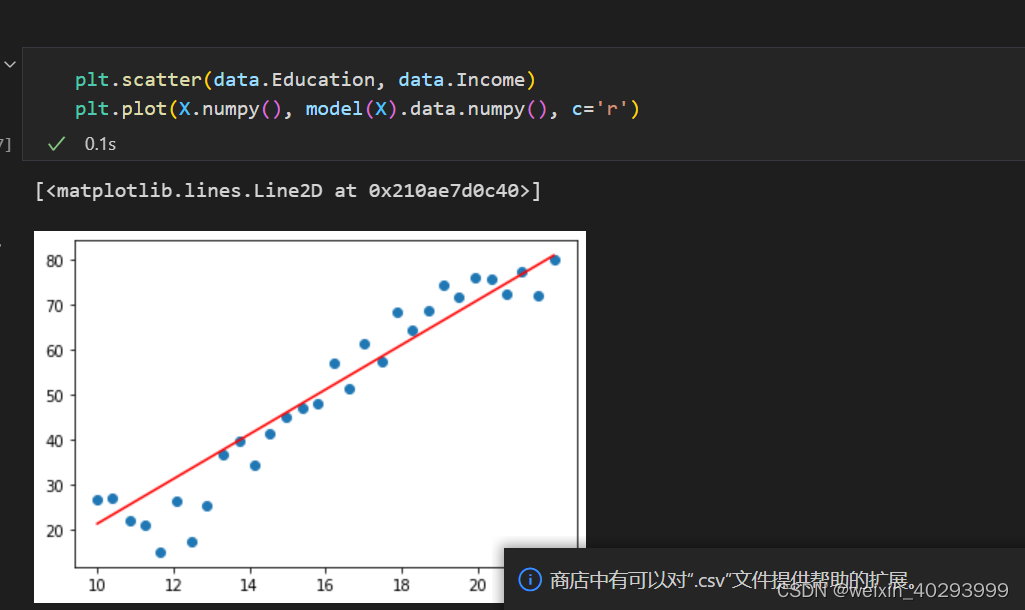
基本功还得练啊,好多都忘了.
git:https://github.com/justinge/learn_pytorch.git
这三项的顺序必须是 梯度清零, 反向传播,梯度下降优化
opt.zero_grad()
loss.backward()
opt.step()
for epoch in range(5000):
for x,y in zip(X,Y):
# 一行一个batch size, 所以一行梯度一清理,这次集散的梯度和下次的无关,是调整过后
y_pred = model(x)
loss = loss_fn(y,y_pred)
# 这三项的顺序必须是 梯度清零, 反向传播,梯度下降优化
opt.zero_grad()
loss.backward()
opt.step()
下面完成自定义版本:
分解写法
w = torch.randn(1, requires_grad=True)
b = torch.randn(1, requires_grad=True)
模型的公式:w@x+b
learn_rate = 0.0001
for epoch in range(5000):
for x,y in zip(X, Y):
y_pred = torch.matmul(x, w) + b
# 计算损失,自己手动计算
loss = (y-y_pred).pow(2).sum()
# 清零梯度
if not w.grad is None:
w.grad.data.zero_()
if not b.grad is None:
b.grad.data.zero_()
# backward()
loss.backward()
# opt.step()
with torch.no_grad():
w.data -= w.grad.data * learn_rate
b.data -= b.grad.data * learn_rate
plt.scatter(data.Education, data.Income)
plt.plot(X.numpy(), (torch.matmul(X, w) + b).data.numpy(), c='r')















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









