






第一章节: 引言
在本章,通过对Hadoop和Spark的概述,使您对它们的框架,包括核心组件、数据怎样在MapReduce和Spark中流转;接下来,通过分析它们的运行框架以便更好理解应用怎样在Hadoop和Spark中工作的。另外,它们生态系统中的各个组件功能特点也将被一一说明。
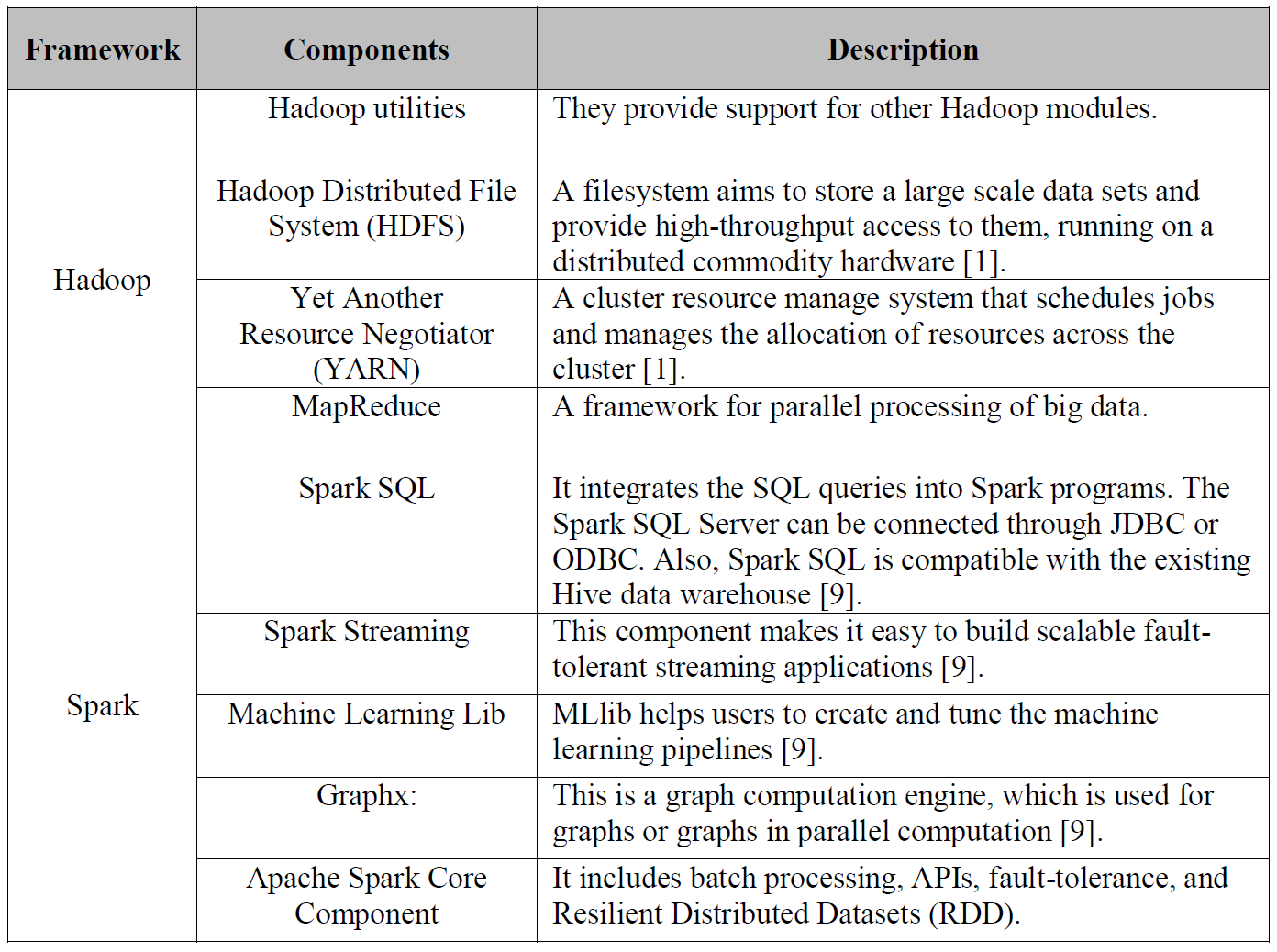
Apache Hadoop 是一种通过服务集群并使用MapReduce编程数据模型完成大数据的分布式处理框架,核心模块包括:MapReduce,Hadoop Utilites,YARN(Yet Another Resource Negotiator)和HDFS(Hadoop Distributed File System)。
MapReduce是一种提供平行计算的编程模型,具有位置感知计划(locality-aware scheduling),容错(fault-tolerance),和可扩展性(scalability);
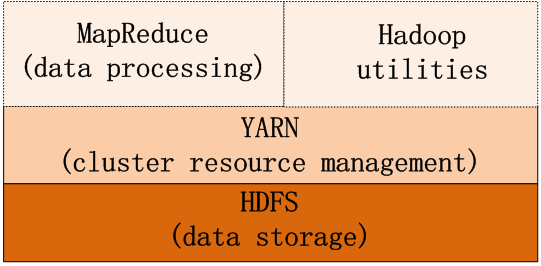
MapReduce把数据处理分为两个阶段:Map阶段和Reduce阶段,处理流程如下:
(1)每一个分割文件对应一个map任务,mapper首先将输入数据转化为中间数据,然后将结果输出到一个循环的内存缓冲中(默认100M);
(2)当这个缓冲中的数据接近阀值(默认80%),mapper开始将缓存中的内容写入本地磁盘的一个文件,但在数据写入之前,mapper将数据分成几个写入区,写入区的数据量对应于reducer的数量(或reduce task数量);同时,在数据分区期间,数据结果默认以key排序。
(3)在数据写入磁盘的同时,当完成在缓存中写入数据时,这个map任务被阻塞,直到缓存中的内容全部被清空。
(4)一旦mapper完成输出,reducer或reduce task(负责将相同key的中间结果收缩到一个更小的结果集)开始从mapper中抓取一个特定分区数据,这种将mapper的输出结果转换为reducer的输入称之为数据洗牌(data shuffling),即all-map-to-all-reduce personalized communication, Hadoop使用自己的算法实现了这种数据洗牌。
(5)洗牌一旦完成,reducer开始融合(merge)这些分区,然后reduce函数被调用处理这些融合的数据;
(6)最后,reduce函数将结果输出到HDFS上。
YARN在Hadoop里是一个集群资源管理框架,它包括两个主要的守护线程:一个计划job和task的管理器,即在集群之间分配资源;启动和监视容器的节点管理器;一个容器对应一个JVM实例,每个JVM实例为应用或tasks分配一定CPU、内存和其它资源;
HDFS是一个存储大数据的分布式文件系统,在分布式的数据块之间建立逻辑关系;它从应用数据中分离出文件系统元数据,将元数据存储在主节点(Name Node),应用数据存储在数据节点上(Data Node),并且HDFS在集群的节点上相互复制一定重复数量的数据块以提高系统的可靠性(以防节点的失败而导致应用不可用)。
Hadoop被认为是可靠的、可扩展的、可容错的,MapReduce虽然适合于处理大数据的应用,但对于不合适与迭代算法和低延迟的应用,因为MapReduce为了提供容错而依赖于持久化的数据,在运行分析查询之前,需将整个数据集加载到系统,这就是为什么Spark诞生的原因。
Spark也是一种处理大数据应用的集群计算框架和引擎,它在内存里构建了一个分布式的对象集合,即Resilent Distrubted Dataset(RDD),然后对这些数据集执行各类平行计算。Spark在迭代机器学习任务中的性能是MapReduce的10倍以上,甚至在某些迭代应用超过20倍。
Spark主要适用于实时数据流处理和迭代算法应用,RDDs是一种分布式内存抽象;每一个RDD是跨集群并可进行平行计算的、只读的、被分区的元素集合, 这种RDD的不可变性以为着修改任何一个RDD将创建一个新的RDD,且容易进行缓存和共享。当对RDD进行操作时,分区的数量决定了平行计算的层级;
RDDs可通过两种方式创建,从外部资源加载数据集,如HDFS,或在一个驱动程序(drive program)里对数据集进行并行分割(parallizing)。
RDDs的操作有两种类型:转换(transformations)和动作(actions), 转换即将一个RDD转化为另个一个RDD,但动作是基于RDD计算出结果并将其返回到驱动程序,最后写入外部的存储资源上。转换RDDs会被惰性评估(lazily evaluated),即Spark不会马上执行实际操作,而只是记录怎样处理或计算这些数据的元数据,一旦动作被请求,Spark才开始执行所有的实际操作(如果再次有新的动作请求,Spark会从头开始计算RDD,所以前一次动作生成中间结果数据可进行缓存或持久)。通过这种方式,Spark减少了在各个节点之间转换原始数据的次数,整个逻辑流程如下:

Spark可根据特定的环境为资源管理框架和文件系统提供多种可选的模式,比如当前有一个干净的集群服务器,可直接使用Standalone Cluster Manager来安装Spark集群;但如果已经有一个Hadoop的集群系统存在,Spark被要求访问HDFS上的数据,那最好让Spark运行在YARN上,而且YARN也提供一些安全策略和集成资源管理策略。

2. 运行架构
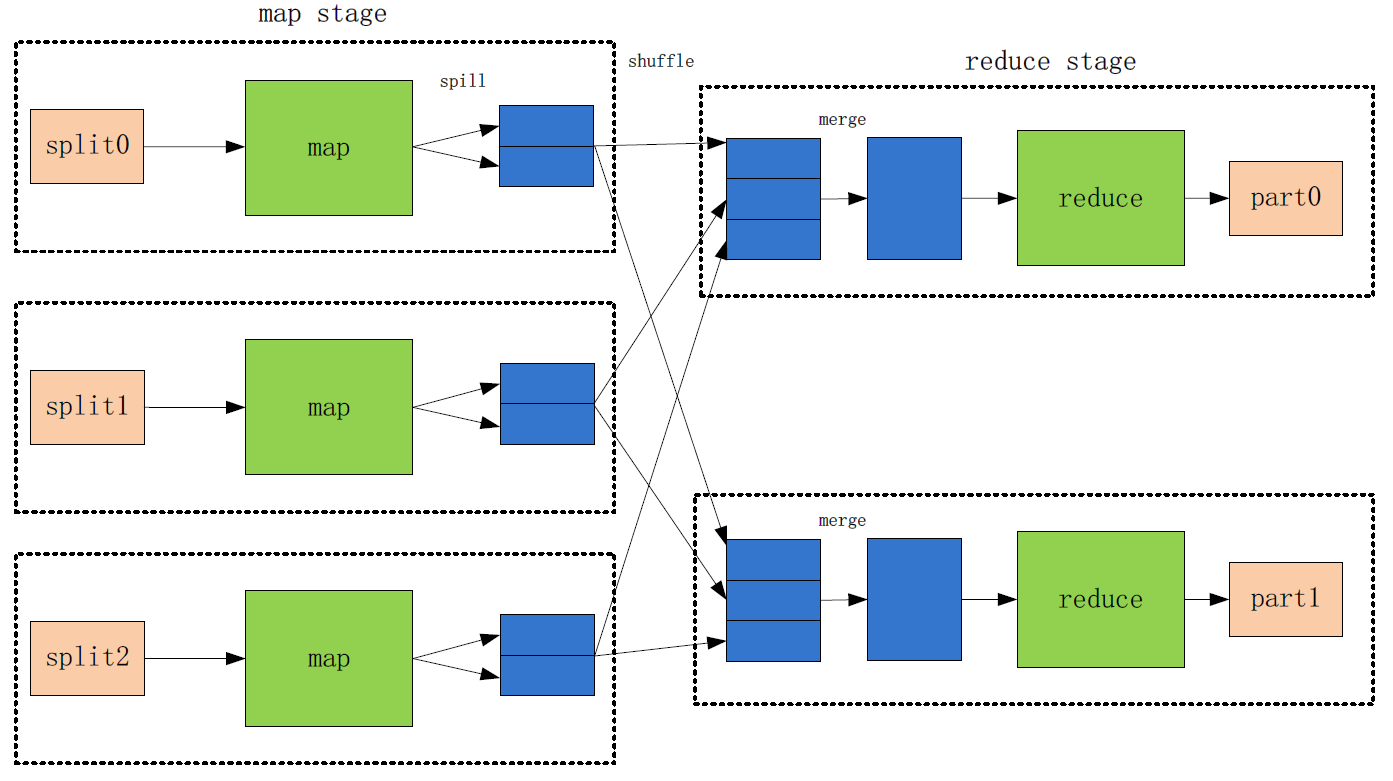
在Hadoop中运行一个MapReduce Jobd
首先一个driver program创建一个jobClient,这个jobClient请求资源管理器(ResourceManager)获取一个application ID;
一旦获取application ID, 则从HDFS复制资源,包括应用所需要的lib及配置文件等;
接着jobClient提交application到资源管理器,并且请求YARN scheduler在一个NodeManger节点分配一个容器,在这个容器里资源管理器会启动应用主程序(application master,负责初始化application job),并为每一个分割文件创建一个map任务和reduce任务;
如果这个job较小(小于10个map任务,一个reduce任务,每个一个输入文件的大小小于HDFS block),这个job会在本地节点执行平行计算;否则应用主程序会发送一个请求到资源管理器请求更多的容器运行MapReduce任务。
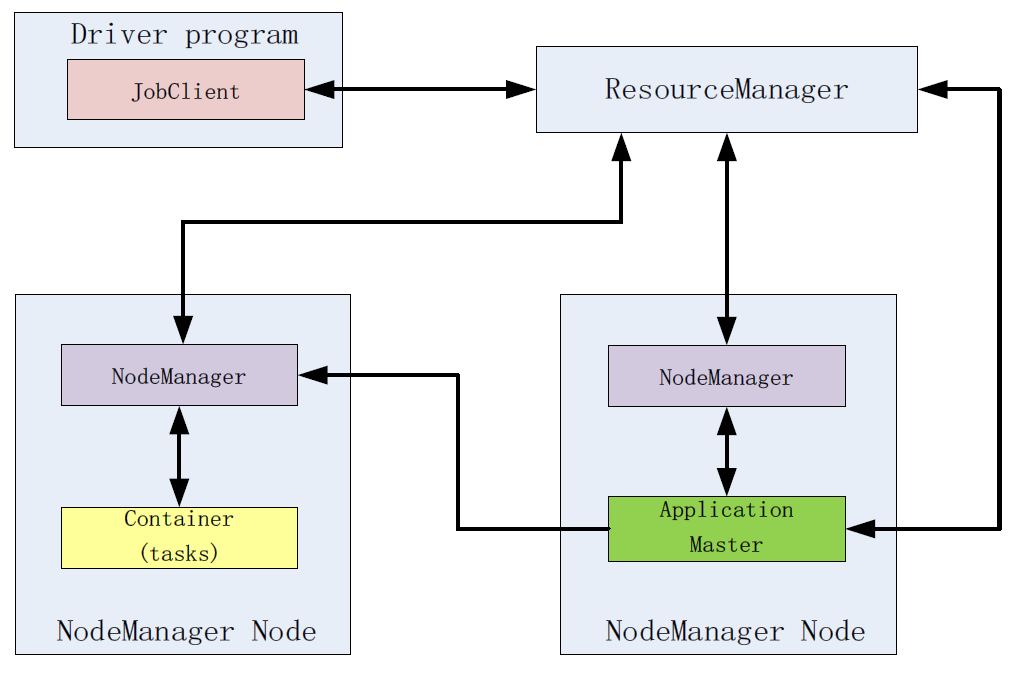
在Spark中运行一个driver program
Spark采用主从结构(master-slave architecture),spark包括一个中心节点central coordinator(driver)和一些工作节点worker(executor),driver可是一个main函数启动的进程,也可是Spark Shell启动的一个应用;
默认情况下,Spark以客户端模式(client mode)运行,即应用提交者在集群之外启动driver;工作节点(worker nodes)负责运行executor进程。
但driver也可以被放在worker节点上,但必须指定为集群模式(cluster mode);driver和executor是两个独立的进程。
driver有两个职责:一是转化用户程序为任务单元(task units,在Spark上运行的最小工作单元),二是在executor上计划任务;
Executor有两个角色:一是负责运行tasks并返回状态给driver,二是为RDDs提供基于内存的存储;
下图显示了一个driver program首先创建一个SparkContext,并连接到集群管理器(Cluster Manager),接着资源管理器为应用分配资源,如executors;接下来,应用代码被发送到executor;最后SparkContext派遣任务到executor去运行。

3. Hadoop和Spark各自生态系统
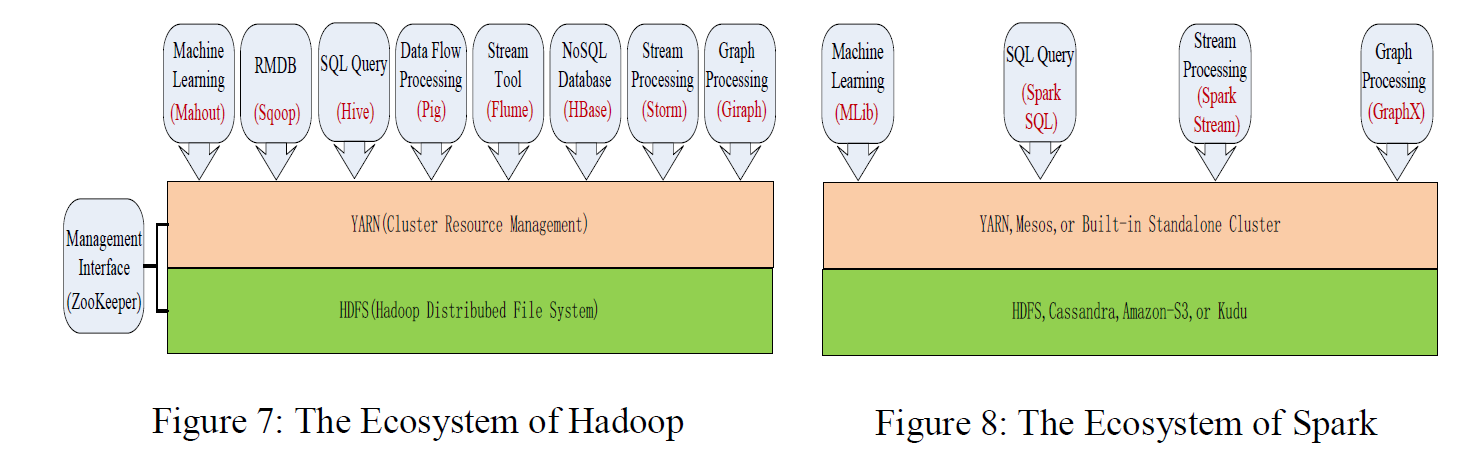
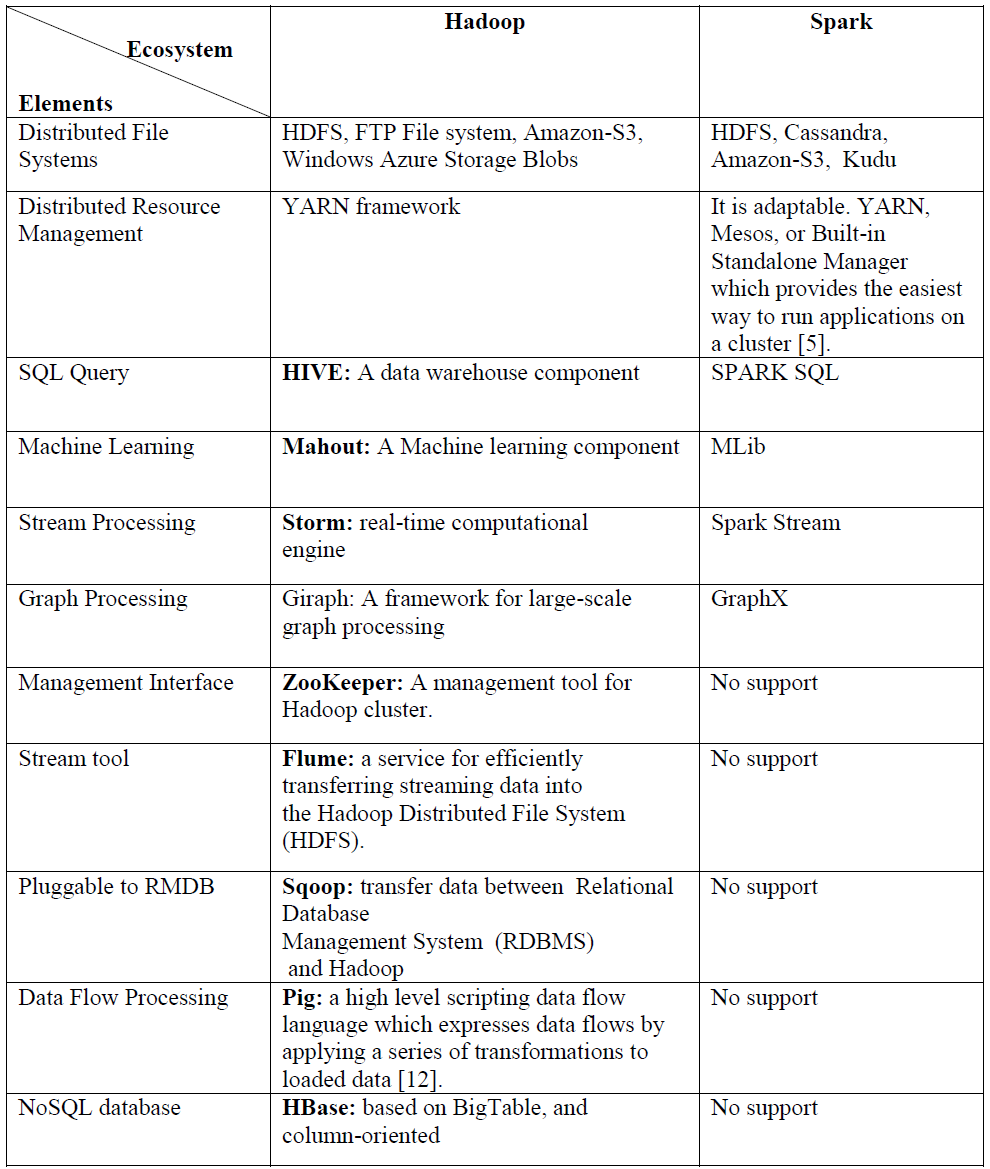
第二章: 性能评估
为了展示Spark比Hadoop有更快的性能表现,下面的实验工作在8个虚拟机节点中进行,每个节点分别安装部署有Hadoop和Spark,并在Hadoop和Spark集群节点中分别运行基于相同逻辑和算法的三个案例,最后将它们的运行结果所表现出来的性能差异以表格的方式展示。
2.1 实验环境
- 硬件配置(8个虚拟机节点)
| Hostname | IP | CPU | Storage |
| host1 | 10.59.7.151 | 每个节点配置: AMD quad-core Opteron 2348 @ 2.7GHZ | NFS raid array, WD Re 4TB 7200 RPM 64MB Cache SATA 6.0Gb/s 3.5" |
| host2 | 10.59.7.152 | ||
| host3 | 10.59.7.153 | ||
| host4 | 10.59.7.154 | ||
| host5 | 10.59.7.155 | 每个节点配置: AMD 12 core Opteron 6174 @ 2.2 GHZ | local disk, WD Re 1TB 7200 RPM 64MB Cache SATA 6.0Gb/s 3.5" |
| host6 | 10.59.7.156 | ||
| host7 | 10.59.7.157 | ||
| host8 | 10.59.7.158 | ||
| 每个节点硬盘大小: 100G 每个节点内存大小: 6G | |||
- 软件配置
| Software Name | Version |
| Operating System | Ubuntu 12.04, 32-bit |
| Apache Hadoop | 2.7.1 |
| Apache Spark | 1.4 |
| JRE | Java(TM) SE Runtime Environment (build 1.8.0_66-b17) |
| SSH | openssh_5.9p1 |
| virtualization platform | VMware vSphere 5.5 |
在这个实验中,Hadoop和Spark都部署在8个虚拟节点上,主节点(master node)IP是10.59.7.151,其它从节(slave node)点或工作节点为:10.59.7.152 ~ 10.59.7.158. 对于Hadoop系统,名称节点(namenode)进程和YARN集群管理器在主节点(master node)上被启动,每一个从节点负责启动它自己的所属的数据节点(datanode)进程 。对于Spark 系统,主进程和内置的独立集群环境在主节点(master node)上启动,每一个工作节点(work node)负责启动执行进程(executor process)。Hadoop和Spark的网络拓扑结构图如Fingure 9所示:
Figure 9: The Network Deployment of Hadoop and Spark
2.3 案例评估
这个实验使用了三个案例,每个案例使用不同数量的迭代,但他们运行过程中都基于相同的执行算法,而且也是基于完全相同的硬件配置,以及Hadoop和Spark各自默认的软件环境配置,这样运行结果才能保证其可行性和合理性。
2.3.1 案例1:Word Count—Sorted by Keys
第一个案例是经典的Work count,首先由一个程序从字典文件里随机读取5000个英文单词,再以每行写一个单词生成数据源文件;下面的Table 3是做为这个案例以及下一个案例Word Count–Sorted by Values的数据大小:
Table 3: Datasets for Word Count–Sorted by Keys
| Sample Name | Sample Size |
| wc_100M.txt | 99.96MB |
| wc_500M.txt | 499.72MB |
| wc_1G.txt | 999.44MB |
| wc_2G.txt | 1.95GB |
- 数据样例
 正在上传…重新上传取消正在上传…重新上传取消
正在上传…重新上传取消正在上传…重新上传取消
Figure 10: The Data Sample of Word Count–Sorted by Keys
- 算法描述
在Figure 11中列出了Word Count案例分别在Hadoop和Spark中实现的两个算法Algorithm 1和Algorithm 2。
算法Algorithm 1(Hadoop)的流程如下:
首先map函数使用一个token(例如空格)依次分割每行数据,然后输出键值对格式的数据例如< <word>, 1>作为reduce函数的输入数据。在reduce函数被调用前,数据中的键(key)按默认的字典排序,接着reduce函数统计不重复单词的个数,最后reduce函数输出结果到HDFS上。
算法Algorithm 2(Spark)的流程如下:
首先,一个RDD对象被创建,这个对象使用函数textFile()从HDFS上加载数据源,然后转换函数(transformation functions),例如flatMap()、map()、及reduceByKey()以延迟调用的方式先记录数据怎样被处理的过程的元数据,最后,一旦像saveAsText()函数被触发调用时,所有转换函数才被真正调用输出实际的中间结果。
Figure 11: Algorithms of Word Count in Hadoop and Spark
2.3.2 案例2:Word Count—Sorted By Values
正如上述案例1所示,默认情况下,Work Count的输出结果默认是以键(key)字典排序的。在下面例子,如Figure 12所示,默认排序函数被重载,以值(value)的统计次数来排序;整个程序通过3个job来完成:第一个job输出如案例1中的相同中间结果,第二个job用来交换键值对(key-value pairs),然后将统计次数按数字整型来排序,最后第三个job用来分组第二个job生成的中间结果,并每组以字母字典排序,整个过程如数据样例中所示:
- 数据样例
正在上传…重新上传取消
Figure 12: The Data Sample of Word Count–Sorted by Values
- 算法描述
- 基于案例1的输出结果,交换Mapper中的键值对;
- 重载Mapper中的比较器,以数字类型排序统计次数;
- 以相同统计次数分组运行的中间输出数据;
- 交换每组中的键值对;
- 每组键(key)再以字母字典排序;
- 合并被分组的数据;
- 输出最终结果。
2.3.3 迭代算法(PageRank)
这里之所以选用PageRank来说明 Hadoop 和Spark之间的性能差异,主要有如下原因:
- PageRank算法的实现包含多次迭代计算;
- 在Hadoop中,每次迭代计算,MapReduce总是在map或reduce操作完成后,将中间结果写入HDFS;
- Spark将中间结果写入内存缓存;
很显然,像PageRank这样的应用, Spark的所表现出来性能会远远超过Hadoop。
- 算法描述
PageRank 算法是伴随着搜索引擎的发展而出现的。该算法实际是计算一种概率:即用户在一个网页上随机点击一些链接,然后变得厌烦,又随意跳到另一个页面的概率。因此,它是一种用来计算整个网站中链接结构的质量排名,并以此来提高搜索结果的准确性,这也是Google搜索引擎评估网页质量排名的方法。
基本上,PageRank的核心思想如下:
- 如果一个页面被大量其它页面引用,那它就比一个较少被引用的页面要更重要,并且这个页面也就有较高的排名;
- 如果一个页面被一个排名较高的页面引用,那它的排名值也将得到提升;
- 这个算法在多次迭代计算后,最终找出所有链接排名的稳定值;
PageRank的排名值的计算公式如下,这也是Google的创始人Brin和Page在1998年提出的:
Ri=d*j∊S(Rj/Nj)+1-d正在上传…重新上传取消
Ri正在上传…重新上传取消 : 链接 i的PageRank值
Rj正在上传…重新上传取消 : 链接 j的PageRank值
Nj正在上传…重新上传取消 : 链接j 指向它邻居节点的链接数量The number of outgoing links of link j pointing to its neighbor links
S

正在上传…重新上传取消 : 指向链接i的链接集合;The set of links that point to the link i
d正在上传…重新上传取消 : 阻尼因子(damping factor,通常取值d=0.85)
2.3.4 样例数据准备及运行结果
Table 4中的样例数据用来评估PageRank应用分别在Hadoop和Spark上的性能表现,所有的数据来源于Stanford Large Network Dataset Collection。
Table 4: Datasets for PageRank Example
| Sample Name | Sample Size | Nodes | Edges |
| web-NotreDame.txt | 20.56MB | 325,729 | 1,497,134 |
| web-Google.txt | 73.6MB | 875,713 | 5,105,039 |
| as-Skitter.txt | 142.2MB | 1,696,415 | 11,095,298 |
- 数据样例
在Figure 13中显示的数据样例来自web-Google.txt文件,每一行代表一个有方向的边或链接指向,左列表示链接的起始点,右列表示链接的目的点。
正在上传…重新上传取消正在上传…重新上传取消
Figure 13: The Data Sample of PageRank
下面举例说明怎样通过上述的样例数据来计算PageRank值。首先每个链接的PageRank初始值为1.0,最终值的计算过程如下:
正在上传…重新上传取消正在上传…重新上传取消
Figure 14: The Example of Calculating the Rank Value of a Link
2.4 运行结果评估
2.4.1 性能测评
对于上述三个案例,它们分别在Hadoop和Spark平台中运行多次并进行比较。为尽量保证一个公平的比较,我们使用的策略如下:
-
-
- Hadoop 和 Spark 平台运行在相同的集群虚拟机上;
- Hadoop 和 Spark 都使用HDFS作为文件存储系统;
- 三个案例的实现基于相同的编程语言和算法来实现;
- 最后,分别利用Hadoop Application Web UI and Spark Application Web UI 计算显示每个案例运行的时耗,如Figures 15 and 16所示:
-
正在上传…重新上传取消正在上传…重新上传取消
Figure 15: Spark Application Web UI
正在上传…重新上传取消正在上传…重新上传取消
Figure 16: Hadoop Application Web UI
既然这篇论文侧重点不是关注获得PageRank的最终稳定收敛值,那在Table 4的中数据集将分别在Hadoop和Spark平台上使用15次迭代计算,以确保Hadoop和Spark之间的性能差异能明显展示出来。
2.4.2 运行结果的比较
在这个项目中,每个案例都被重复10次以上的测试,以获取平均的运行计算结果。有时由于网络的不稳定,每次一个小的任务执行可能会有几秒的误差,或一个较大任务会有十几秒或几十秒的误差存在。 Tables 5, 6, and 7 显示了每个案例分别在Haoop和Spark上基于不同的数据集的平均运行时间的比较,观察结果如下:
-
-
- 在第一个案例Word Count,对于一个较小的数据,例如小于Hadoop默认的block size 128M,在Spark和Hadoop上运行的时长比率比较稳定,这是因为不管是在Hadoop或Spark中,数据都运行在本地节点;然而,随着数据的增大,例如数据被分割成多个block,在Spark和Hadoop将呈现一个递增式的性能比率。这里,性能比率定义如下:
-
PR=某个数据集在Spark中的运行时长相同数据集在Hadoop中的运行时长正在上传…重新上传取消正在上传…重新上传取消
Table 5: Running Times for the Case Study of Word Count(案例一)
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Hadoop | 58 secs | 1 min 12 secs | 1 min 48 secs | 2 mins 25 secs |
| Spark | 16 secs | 23 secs | 25 secs | 30 secs |
| PR=3.63 | PR=3.13 | PR=4.32 | PR=4.83 |
Table 6: Running Times for the Case Study of Secondary Sort(案例二)
| Data size System | 100 MB | 500 MB | 1 GB | 2GB |
| Hadoop | 1 min 43 secs | 1 min 56 secs | 2 mins 27 secs | 3 mins 2 secs |
| Spark | 12 secs | 22 secs | 23 secs | 30 secs |
| PR=8.58 | PR=5.27 | PR=6.39 | PR=6.07 |
Table 7: Running Times for the Case Study of PageRank(案例三)
| Data size System | 20.56 MB NotreDame | 67.02 MB | 145.62 MB as-skitter |
| Hadoop | 7 mins 22 secs | 15 mins 3 secs | 38 mins 51 secs |
| Spark | 37 secs | 1 min 18 secs | 2 mins 48 secs |
| PR = 11.95 | PR = 11.58 | PR=13.86 |
如前面所述,Spark的RDD是基于内存存储进行运算处理的,而Hadoop的MapReduce基于磁盘操作数据,这样Spark无疑会比Hadoop会表现出更好的性能。然而,在Spark中,需要通过指定参数spark.executor.memory为每一个执行器(executor)分配合适的内存。因此,如果给Spark的每个执行器(executor)分配不同内存,随着迭代次数的递增,相同数据集的运行结果也将有一定的性能差异,如Table 8, 9, and 10 中比较的运行结果。
-
-
- 对于较小的数据集或较少的迭代次数,内存增加对性能的提升并没有帮助,如Tables 8 and 9所示。
- 随着数据集的增长以及迭代次数的增加,通过递增设置spark.executor.memory的值,运行结果也将表现出显著的性能提升,如Table 10所示。
-
Table 8: Running Times for Word Count–Sorted by Keys on Spark
| Data size
Memory usage (GB) | 100 MB | 500MB | 1GB | 2GB |
| 3 | 16 secs | 24 secs | 25 secs | 29 secs |
| 2 | 16 secs | 24 secs | 24 secs | 30 secs |
| 1 | 16 secs | 23 secs | 25 secs | 31 secs |
Table 9: Running Times for Word Count–Sorted by Values on Spark
| Data size
Memory usage (GB) | 100 MB | 500 MB | 1 GB | 2 GB |
| 3 | 16 secs | 24 secs | 25 secs | 31 secs |
| 2 | 17 secs | 23 secs | 27 secs | 29 secs |
| 1 | 15 secs | 23 secs | 24 secs | 31 secs |
Table 10: Running Times for PageRank on Spark
| Data size
Memory usage (GB) | 20.56 MB NotreDame | 67.02 MB | 145.62 MB as-skitter |
| 3 | 36 secs | 78 secs | 162 secs |
| 2 | 37 secs | 78 secs | 180 secs |
| 1 | 33 secs | 114 secs | 780 secs |
即使基于相同的内存使用,Spark仍然比Hadoop表现出更好的性能(Hadoop默认为每个map任务设置1G的内存),主要原因源自以下几个因素:
- Spark的工作负载比Haoop在单位时间内有较高的磁盘访问数量;
- Spark比Hadoop有更高的内存带宽性能;
- Spark比Hadoop有获得更高的IPCs;
而且,在Spark中,任务计划是基于事件驱动模式,而Hadoop使用心跳模式去跟踪任务,这样会引起周期性的几秒延迟,从而带来性能损失。另外,在Hadoop中,一些基本的初始化需求,如job的建立,启动的任务等也带来一定的性能损耗。总之,对于那些存在多次迭代计算的应用,Spark的性能表现将呈现压倒性的优势,因为在Hadoop中的多个job也不能共享数据,并且要频繁访问HDFS。
第三章:调优Hadoop和Spark
Hadoop为集群和应用提供超过上百个默认参数配置,Spark也可让用户为应用调优配置很多属性。由于各个参数之间内在的联系,修改一些默认值可能会对性能产生重要的影响。例如,在Hadoop中,假设map任务数量合适,而reducer数量设置一个比较高的值,任务就会在集群中被并行处理,但是在mapper和reducer之间数据洗牌(shuffling data)的处理就会长生大量的系统开销,因为数据洗牌阶段包括网络数据传输与交换,数据内存合并和磁盘合并。然而,如果reducer的数量设置为1,那网络的宽带将会限制大量数据的交换,以致降低了整个应用的系统性能;所以,无论Hadoop还是Spark,各参数或属性的优化配置不仅取决于应用的特点,而且和集群所在硬件环境本身有大的关系。
这里,我们先以Word Count–Sorted by Key案例为例,分别在Hadoop和Spark中,调节一些参数配置后观察其性能是怎样逐步得到改善。为了比较每一步运行结果的变化,我们先观察Hadoop和Spark各自在默认的参数设置的条件下,运行结果耗时如下:
Table 11: The Running Times with Default Configuration Settings
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Hadoop | 55 secs | 1 min 44 secs | 1 min 59 secs | 3 mins 53 secs |
| Spark | 18 secs | 26 secs | 28 secs | 34 secs |
3.1 调优Hadoop
- Optimization I: 数据压缩
默认情况下,Hadoop提供三种类型的数据压缩支持: gzip, bzip2 和LZO, 每一种类型有不同压缩比率和速度。在这个案例中,如果我们适当调整如下参数,随着处理数据的递增,性能也将获得更多的提升;而对于较小的数据处理,由于压缩和解压缩的系统开销,性能反而会有所下降:
- mapreduce.map.output.compress = true (false by default)
- mapreduce.map.output.compress.codec = gzip
Table 12: The Running Times with Optimization I in Hadoop
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| 1 min 3 secs | 2 mins 4 secs | 2 mins 10 secs
| 3 mins 23 secs |
- Optimization II: 改变内存管理和YARN 参数配置
从Hadoop的默认参数运行结果来看,我们可得到如下两个结论:
- Map阶段在整个运行过程中耗费的时间最长;
- 随着数据的递增,reduce阶段耗费的时长也变得越来越多;
在map阶段,mapper输出首先被缓冲到内存,然后达到缓存阀值,则输出数据到磁盘。这个mapper结果输出到磁盘的代价由两个因素决定:内存缓存大小(memory buffer)mapreduce.task.io.sort.mb 和缓存阀值的大小mapreduce.map.sort.spill.percent。因此,我们先优化map阶段,在mapred-site.xml中设置如下参数:
- 增大循环内存缓冲到500M(默认100M):mapreduce.task.io.sort.mb;
- 设置在并行处理中洗牌复制(shuffling copies)的数量为20(默认为5): mapreduce.reduce.shuffle.parallelcopies;
- 减少数据输出到磁盘,设置:mapreduce.map.sort.spill.percent = 0.95 (默认为0.8);
再次运行案例Word Count–Sorted by Keys,我们发现性能要比默认设置参数时好很多,但是如果数据小于block的大小,例如100M,因为数据处理总是在本地处理,所以运行时间几乎是没什么变化的,如下表所示:
Table 13: The Running Times with Optimization II in Hadoop
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Hadoop | 53 secs | 1 min 18 secs | 1 min 43 secs | 2 min 27 secs |
- Optimization III: 修改分割区配置
Reduce 任务的数量设置也是Hadoop中MapReduce的关键参数配置,所以优化reducer的数量会对系统的性能有所提升。在Hadoop中,默认只有一个reducer,即一个分割区。
增加reducer的数量可提升负载均衡和降低失败的损耗,但是也增加了节点间网络通信的损耗。合适的reducer数量应设置为: 0.95 or 1.75* (节点数 * 每个节点最大的容器数量)
因子0.95 意味着所有的reduce任务能立即启动,并且开始准备传输map的输出结果;因子1.75意味着处理较快的节点将完成他们的第一轮reduce任务,并且发起第二波reduce,这样将会获得一个更好的负载均衡。
在这次实验环境里,每个节点的内存为6G,但每个工作节点在启动一些必要的进程或守护进程后(例如Hadoop中节点管理器进程,数据节点的进程,以及Spark中工作节点进程),可用内存不到3.5G,参数配置如下:
mapreduce.map.memory.mb = 1204M //每个节点
mapreduce.reduce.memory.mb = 2560M //每个reducer容器
因此,在一个节点中只能最多启动两个mapper容器和一个reducer容器,所以,案例中合适的reducer容器数量应该是6~8 or 12~14。然而,基于optimization II, 尝试设置不同的recuder容器的数量,最好的性能提升结果如下表所示:
Table 14: The Running Times with Optimization II and III in Hadoop
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Hadoop | 53 secs (reducer = 1) | 1 min 16 secs (reducer = 1) | 1 min 34 secs (reducer = 6) | 2 mins 23 secs (reducer = 13) |
3.2 调优Spark
Spark提供三中数据压缩类型支持: lz4, lzf, and snappy,默认使用snappy来压缩RDD分区。
- Optimization I: 改变内存管理
默认情况下,driver进程的核数量是1,内存设置为1GB,每个executor进程使用的内存数量设为1G。为了充分利用内存以提高计算的效率,为RDD分配足够的内存以避免执行任务的可能崩溃,这里我们设置: spark.driver.cores = 2,
spark.driver.memory = 2G,
and spark.executor.memory = 3G,
获得的最佳性能如下表:
Table 15: The Running Times with Optimization I in Spark
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Spark | 15 secs | 25 secs | 26 secs | 31 secs |
- Optimization II: 数据分割
在这次实验中,无论Hadoop还是Spark,只有一个数据分区用来输出运行的中间结果。当存在一定数量的map任务时,这种方式由于网络瓶颈而降低了系统性能。 因此,一个合适的分区有助于性能的提升。在Spark中,每个RDD的分区数量是由map的任务数量决定的,也就是说,每个mapper容器输出对应一个RDD分区。在Spark中重分区数据是个相当昂贵的操作,所以在基于optimization I的基础上,使用默认分区获得如下的性能体现:
Table 16: The Running Times with Optimization I and II in Spark
| Data size
System | 100 MB | 500 MB | 1 GB | 2 GB |
| Spark | 16 secs | 23 secs | 24 secs | 29 secs |
第四章:结论
从三个案例中,Spark的性能远远优于Hadoop,尤其是在涉及多次迭代计算的应用;通过几个重要参数的调节,Spark和Hadoop的性能也会有显著的提升。 首先,Spark 默认在内存中进行RDD传输与转换, 但是Hadoop主要侧重于数据的高吞吐量而不是job执行的性能,例如MapReduce由于数据复制、磁盘I/O、以及序列化而导致的性能损耗。而且,为了达到有效容错,RDD为跨集群的数据复制或共享状态提供粗粒度转换,而不是细粒度的更新,这就意味着Spark通过数据转换构造了一个有血统关系的RDD数据结构,而不是实际的结果数据。例如,如果一个RDD的分区丢失,这个RDD可以找回它自身是怎样来源于其它RDD的相关信息。最后,也是一个重点,Spark内部设计比Hadoop有更多的优化,例如磁盘每秒访问的数量,内存带宽利用率,以及IPC率。
Spark之所以在性能上远远优于Hadoop,很大程度上是以消耗大量内存为代价的。但是Spark不太适合异步细粒度状态更新的应用;而且,如果没有足够的内存而且性能不是强制要求的,Hadoop则更适合这样的应用;对于响应时间要求优先,或涉及多次迭代计算的应用,并且有充足的内存资源,Spark是个更好的选择。

















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









