









摘要
对于考察整个图的任务,比如分类聚类,还是得靠图核,但图核依赖人工(就是不能端到端呗?)
本文提出用神经嵌入学习任意大小图的分布表示,该嵌入是无监督得来的即与任务无关
1 引言
传统方法是将图表示成固定大小以适配机器学习算法
图核是通过递归的将G和G’归为子结构(如随机游走,最短路图元等)来计算一个核值也即相似性:在子结构上定义一个核函数(如,计算公共子结构数量),进而采用SVM分聚类
缺陷:①没有显式的图嵌入,这样需要嵌入向量的ML方法(如随机森林,神经网络)就没辙了(不都说是用SVM了吗,那干嘛还考虑RF和NN吗?)②子结构需要特定函数产生,也即是“人工手工制作的”(致命的泛化能力差)
于是考虑用神经自动学得的特征来替换
目前也有学习子结构嵌入的研究,但这些方法不能表示整个图,在后续实验中显示会得到次优结果
目前也有学习针对任务的图嵌入,比如通过图的类别标签的监督方法学习图嵌入,但这样①需要大量标签②其实是特定于数据集
受神经文档嵌入的启发,利用单词及其序列组成文档的方式学习嵌入(类似于bert?)
任务无关,可以用于种子监督任务seed supervised representation learning approaches [9].
与sub2vec[5]这样采样图中线性子结构(?)的方法不同,本文考虑非线性子结构(如随机游走核,最短路核),这样可以保持结构等价性,从而保证给结构相似的图产生相似的嵌入
2 问题
给定一组图G={G1,G2,…}和一个正整数δ(即期望嵌入大小),目标是学习每个图的δ维分布表示。所有图的表示矩阵表示为
Φ
∈
R
∣
G
∣
×
δ
Φ∈R^{|G|×δ}
Φ∈R∣G∣×δ。
记图G=(N,E,λ),其中λ是给每个节点映射唯一的标签。否则,G是无标签图。本文需要节点标签,如果没有则参考[10]用节点度做标签(同理可以给边标签)
给定一个图G和其子图sg,存在一个单射,将sg节点映射回G
本文提出根子图,即节点n的度为d,则该根子图包含所有从n起d跳内的所有节点
3 背景:SKIPGRAM词和文档嵌入模型
3.1 SKIPGRAM学习词嵌入
word2vec采用简单的前馈NN,即SKIPGRAM
出现在相似上下文中的词往往具有相似的含义,因此应有相似的向量表示。为了学习目标词的表示,word2vec将上下文定义为围绕目标词的固定数量的单词。为此,给定一系列词{w1,w2,…,wt,…,wT},必须学习其表示的目标单词wt和上下文窗口c的长度,SKIPGRAM的目的是求最大似然估计:
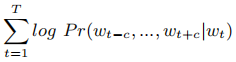
从而
P
r
(
w
t
−
c
,
.
.
.
,
w
t
+
c
)
=
Π
−
c
≤
j
≤
c
,
j
≠
0
P
r
(
w
t
+
j
∣
w
t
)
P r(w_{t−c}, ..., w_{t+c})=Π_{−c≤j≤c,j≠0}P r(w_{t+j }|w_t)
Pr(wt−c,...,wt+c)=Π−c≤j≤c,j=0Pr(wt+j∣wt)
根据目标词的独立性假设,
P
r
(
w
t
+
j
∣
w
t
)
P r(w_{t+j }|w_t)
Pr(wt+j∣wt)被记作
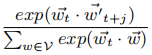
其中w和w’是词w的输入和输出向量,V是所有词的集合词库
3.2 负采样
P
r
(
w
t
+
j
∣
w
t
)
P r(w_{t+j }|w_t)
Pr(wt+j∣wt)可以通过好几种方式来学习。例如,像逻辑回归这样的分类器。但词库V非常大的话就麻烦了。
负采样可以缓解这一问题并训练SKIPGRAM模型。随机选择一个不在目标词上下文中的小子集,并在每次迭代中更新它们的嵌入,而不是考虑词库中的所有单词。
这样的训练可以保证:如果一个词w出现在另一个词w’的上下文中,那么与从词库中随机选择的任何其他词相比,w的向量嵌入更接近w‘。
一旦SKIPGRAM训练收敛,语义相似的单词被映射到嵌入空间中更近的位置,表明学习到的单词嵌入保留了语义。
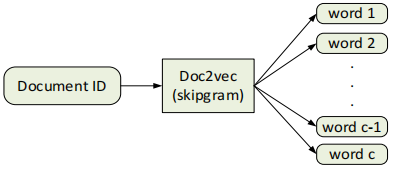
3.3 文档嵌入模型
doc2vec从学习单词嵌入扩展到单词序列。使用了一个SKIPGRAM模型的实例,称为段落分布向量的单词袋(PV-DBOW)(也即doc2vec SKIPGRAM),它能够学习任意长度的词序列的表示,如句子、段落,甚至整个大型文档
给定一组文档D={d1,d2,…,dN},从文档di∈d采样的一系列词c(di)={w1,w2,…,wli},doc2vec SKIPGRAM分别学习了文档di∈D和从c(di)采样的每个单词wj的δ维嵌入
该模型的目标即最大似然估计:
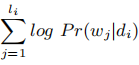
这样
P
r
(
w
j
∣
d
i
)
P r(w_{j }|d_i)
Pr(wj∣di)可被定义为
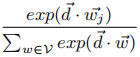
其中V是D中所有文档的所有单词的词库
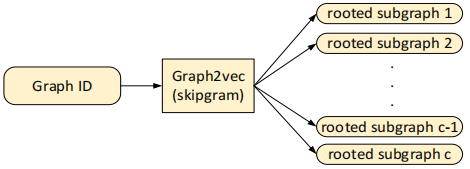
从而类比
图←→文档
根子图←→词
4 方法
4.1 Intuition
强调一下用根子图而不是如节点、路径等作为图子结构的用意:
①高阶子结构
与节点等简单的低阶子结构相比,根子图包含高阶邻域(就是多跳呗),这提供了更丰富的图的组成表示。因此,通过采样这种高阶子结构所学习到的嵌入将更好地反映图的组成。
②非线性子结构
与行走和路径等线性子结构相比,有根的子图能更好地捕捉到图中固有的非线性。这一事实在考虑图核时也很明显。例如,基于非线性子结构的WL核在许多任务上的性能明显优于随机游走和最短路径等基于线性子结构的核
结构上相似的图在嵌入空间中将彼此接近。从这个意义上说,类似于深度图核[7],图2vec的嵌入提供了到达数据驱动的图核的方法。
4.2 算法
类比文档模型,这边需要的输入也只有图词库,也即是每个节点的所有根子图作为词库
重头戏是提取根子图,并为所有根子图分配唯一标签,所以采用WL重新标签策略(WL图核也有使用该策略)
4.3

算法由两个主要组件组成
①首先,对给定图中每个节点周围生成根子图
②其次是学习给定图嵌入
如算法1所示,打算在第e轮次学习数据集G中所有图的δ维嵌入。
首先随机初始化数据集中所有图的嵌入
随后继续提取每个图中的每个节点周围的根子图
并迭代地学习(即细化)相应图在一些轮次的嵌入
4.3.1 提取根子图

输入根节点n,原图G,以及预期子图的度d
输出预期子图
s
g
n
(
d
)
sg_n^{(d)}
sgn(d)
递归出口d=0,不要子图,只输出节点n的标签λ
对于d>0,根据宽度优先得到n的邻居,对每个邻居再得到其对应的d-1子图,记录进
M
n
(
d
)
M_n^{(d)}
Mn(d)
得到n的d-1子图后与排序后的
M
n
(
d
)
M_n^{(d)}
Mn(d)拼接得到最终结果
4.3.2 负采样Skipgram
考虑词库SGvocab巨大,通过负采样计算
P
r
(
s
g
n
(
d
)
∣
Φ
(
G
)
)
P r(sg^{(d)}_n |Φ(G))
Pr(sgn(d)∣Φ(G))这个后验概率
在每个训练周期,给定一个图Gi∈G与其上下文的一组根子图,c(Gi)=c={sg1,sg2,…},我们选择一组固定数量的随机选择的子图作为负样本c’={sgn1,sgn2,…sgnk}这样保证c’是词库的子集,k<<|SGvocab|和c∩c’={}
负样本是一组k个子图,每个子图都不存在于需要学习嵌入的图Gi中,而是存在于子图的词库中(也就是在所有原图组成的综合子图集合中选取,这里面是有不属于原图Gi的子图的)。
负样本的数量k是一个可以通过经验进行调整的超参数
为了有效的训练,对于每个图Gi∈G,首先训练目标—上下文对(Gi,c),并更新相应的子图的嵌入。随后,我们只更新负样本c’的嵌入,而不是整个词库。
4.3.3优化
随机梯度下降(SGD)
4.4用例
图分类
给定一组图G和对应的类别标签集Y,本文可以获得G中所有图的嵌入,再将其提供给RF、NN和SVM等通用分类器进行分类。
其他的方法如图核和子结构嵌入,都没有这种灵活性,它们的核矩阵只能用于核分类器(如SVM),而不能与通用分类器一起使用。
图聚类
计算出嵌入就可以与通用的聚类算法如k-means、AP等关系聚类算法相结合来实现这一点
而图核和子结构嵌入只能用关系聚类算法















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









