








-
I. INTRODUCTION
- 为什么模仿学习没有扩展到完全自主的城市驾驶?模仿学习的一个假设是:最优action可以直接从observation中推断出来。但实际上这个假设并不成立,比如说:“当汽车接近十字路口时,摄像机的图像不足以预测该汽车应该左转、右转还是直行”。从数学上讲,从图像到控制命令的映射不再是一对一的函数映射。因此,用神经网络处理时候会遇到困难,导致震荡。就算神经网络可以解决一些模糊性,但也可能得不到人类想要的结果,因为人类本身无法和网络交流。
- 本文中,我们用“条件模仿学习”来解决这个问题。在训练时,模型不仅给出了感官输入和控制信号,而且给出了“专家意图”的表示。测试阶段,把一个“指令”传给网络,从而解决神经网络映射的模糊性(这个指令由司机或者是乘客给出)。通过这种方式,就可以把网络和具体任务解耦,从而使得网络的表达能力专注于决策上。
-
II. RELATED WORK
- 模仿学习已应用于各种任务中,包括关节运动、自主飞行、导航行为建模、越野驾驶、以及道路跟随。从技术上讲,这些应用在输入表示、预测的控制信号、学习算法和学习表征有所不同。与我们的工作最相关的是Pomerleau、LeCun等人的系统和Bojarski等人的系统,他们使用地面车辆和训练有素的深层网络,通过摄像头输入来预测驾驶员的动作。这些研究集中在纯粹的反应性任务上,如车道跟踪或避障。相比之下,我们开发了一个命令条件式,使模仿学习能够应用于更复杂的城市驾驶。另一个不同之处在于,我们不仅学会了控制方向盘,还学会了加速和刹车,使模型能够完全控制汽车。
- 从多个角度研究了复杂任务分解为简单子任务的问题。在机器人技术中,运动原语被用作高级运动技能的构建模块。运动原语由参数化的动力系统表示一个简单的运动,如击打或投掷。相比之下,我们考虑的策略具有更丰富的参数化,可以处理更复杂的感知运动任务,这些任务将感知和控制结合起来,比如找到下一个右转的机会,然后在避开动态障碍的同时转弯。
- 在强化学习中,层次方法旨在构造多个层次的时间扩展子策略。options框架就是这种层次分解的一个突出例子。在这个框架中学习的基本运动技能可以在不同的任务之间转换。分层方法也与深度学习相结合,并应用于原始的感官输入。这些作品的主要目的是单纯地从经验中学习,自动发现层次结构。这是一个困难的问题,一般来说,这是一个开放的问题,特别是对于复杂的感觉运动技能,我们认为。相反,我们专注于模仿学习,并在演示过程中提供专家意图的额外信息。这个公式使学习问题更容易处理,并产生了一个人可控的策略。
- 与分层方法相邻的是学习多用途参数化控制器的思想。参数化目标已被用于机器人运动控制器的训练。Schaul等人[31]提出了一个通用的框架,用于在状态和目标之间共享参数化值函数来增强学习。Dosovitskiy和Koltun[9]研究了三维导航环境下参数化目标家族。Javdani等。[15]研究了一个机器人帮助人类并根据其对人类目标的估计改变其行为的场景。我们的工作分享了训练条件控制器的想法,但是在模型架构、应用领域(基于视觉的自主驾驶)和学习方法(条件模仿学习)上有所不同。
- 自主驾驶是[25]研究的热点。一般来说,方法的模块化程度各不相同。一方面是高度调优的系统,部署一系列计算机视觉算法来创建环境模型,然后用于规划和控制[12]。另一边是端到端方法,训练函数逼近器将感知输入映射到控制命令[4]、[27]和[36]。我们的方法是端到端的频谱,但除了感官输入,控制器还提供了指定驱动程序意图的命令。这解决了感知器映射中的一些模糊性,并创建了一个通信通道,可以像引导司机一样引导自动驾驶汽车。
- 研究了[5]、[14]、[24]、[34]、[35]等机器人动作的人体导引。这些工作解决了解析自然语言指令的难题。我们的工作不涉及自然语言交流;我们将命令限制在预定义的词汇表中,比如“在下一个十字路口向右拐”、“在下一个十字路口向左拐”和“保持直线”。另一方面,我们的工作涉及到使用深度网络的端到端视觉驱动。该领域的系统仅限于模仿专家,无法在部署[4]、[6]、[27]、[36]之后自然地接受命令。我们将这种能力引入基于端到端视觉驱动的深度网络。
-
III. CONDITIONAL IMITATION LEARNING
- 考虑一个控制器,它通过离散时间步长与环境交互:在每个时间步t,控制器接收到一个观察ot并采取动作at。模仿学习的基本思想是:训练一个能够模仿专家的控制器。训练数据是由专家生成的action-observation-pairs。
- 简单的来说,就是一个监督学习,最小化:
-

- 这背后隐含的假设是:专家的行动可以完全由observation解释——即存在一个:将ob映射到action的函数
 。如果这个假设成立,并且给定足够的数据,一个拟合器确实能够拟合函数E。这就解释了模仿学习在诸如“跟随车道”等任务中的成功。然而,在更复杂的场景中,这个假设就不成立了。考虑一个正在接近十字路口的司机。驾驶员的后续操作不是通过ob来解释的,而是受到驾驶员“自身内部状态”的影响,例如“预期目的地”。这类“潜在状态”,决定了相同的ob可能导致不同的行动。当然,这可以按照随机性进行建模,但随机模型会忽略行为的根本原因。此外,即使一个训练好的控制器确实学会转弯和避免碰撞,它仍然不能算是一个有用的驾驶系统——它会在街道上游荡,在十字路口做出武断的决定;乘客将无法告诉控制器应该去哪,也无法向控制器发出有关转弯的命令。
。如果这个假设成立,并且给定足够的数据,一个拟合器确实能够拟合函数E。这就解释了模仿学习在诸如“跟随车道”等任务中的成功。然而,在更复杂的场景中,这个假设就不成立了。考虑一个正在接近十字路口的司机。驾驶员的后续操作不是通过ob来解释的,而是受到驾驶员“自身内部状态”的影响,例如“预期目的地”。这类“潜在状态”,决定了相同的ob可能导致不同的行动。当然,这可以按照随机性进行建模,但随机模型会忽略行为的根本原因。此外,即使一个训练好的控制器确实学会转弯和避免碰撞,它仍然不能算是一个有用的驾驶系统——它会在街道上游荡,在十字路口做出武断的决定;乘客将无法告诉控制器应该去哪,也无法向控制器发出有关转弯的命令。 - 为了解决这个问题,我们通过一个向量h建模专家的内部状态,h会和ob共同决定动作at。向量h可以包含关于专家意图、目标和先验知识的信息。
- 于是,新的公式可以写成:
-
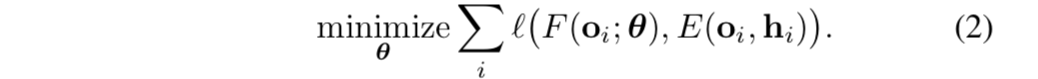
- 很明显,专家的行为由 o 和 h 的共同决定。
- 我们通过这种方式把h传入控制器:c = c(h)。训练时,命令c由专家提供。c不需要代表“潜在状态h的所有内容”,而应该偏向于和“专家决策的有关的信息”。在测试时,可以使用指令来影响控制器的行为;这个指令可以来自于人工或者是一些内部的规划模块。
- 于是,训练数据的格式变成了
 。“以命令为条件的模仿学习”的目标是:
。“以命令为条件的模仿学习”的目标是: -
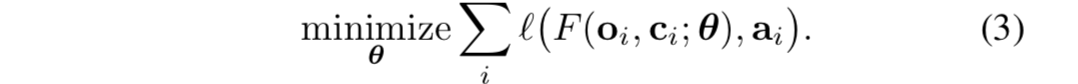
- 与目标2相比,学习器还接受了“专家潜在意图”,结合这些“额外潜在意图”对动作进行预测。如图2所示:
-

-
IV. METHODOLOGY
-
A. Network Architecture
- 假设每个ob:o = 〈i,m〉 ,包括一个 图像i 和一个低纬 向量m (我们称为measurements)。控制器F用一个深度网络表示,网络 输入 图像i,measurements m,命令c,并产生 一个动作at作为输出。动作空间可以是离散的、连续的,也可以是这些的混合。在我们的驾驶实验中,动作空间是连续二维的——转向角和加速度。加速度可以是负的,这相当于刹车或倒车。命令c是由一个由“one-hot-向量”表示的 分类变量。
- 我们研究了将“命令c”融合进网络的两种方法。第一个架构如图(3)a所示,网络将“命令c,连同图像,测量值”一起作为输入——这三个输入分别由三个模块处理:图像模块I(I)、测量模块M(M) 和 命令模块C(C)——图像模块是卷积网络,其余两个模块是全连接网络。然后这些模块的输出串联成一个联合表示。
-
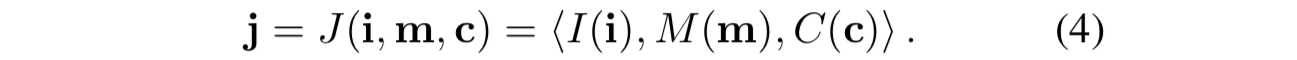
- 控制模块为一个完全连接的网络,输入是“联合表示”,并输出一个动作a (j)。我们将这个架构称为“命令输入架构”。
- 然而,这种网络有一个设计弊端就是:网络在学习的时候,并不能保证,“指令”一定会被考虑进去,从而在实践中导致性能不佳。
- 为此,我们设计了一个额外的架构,如图3(b)所示——图像和测量模块和之前相同,但是删除了命令模块。
- 取而代之的,我们假设一组离散的命令 C = { c0 , . . . , cK } ——(包括一个默认命令c0,对应于无命令情况),为每个命令ci引入一个专门的分支Ai。命令c充当一个开关——作用是“决定使用哪个分支”。网络的输出是这样的:
-
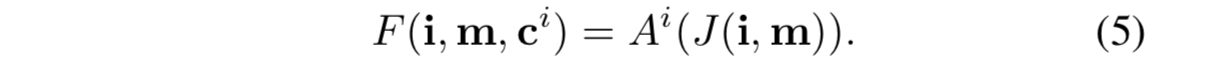
- 我们把这个架构称为“分支架构”。分支Ai必须学习对应着“不同子命令的子策略"。在驾驶场景中,一个模块可能专门负责车道跟踪,另一个模块负责右转弯,第三个模块负责左转弯。所有模块共享感知流。
-
B. Network Details
- observation的维度是200×88的图像。对于测量m,我们使用了汽车的当前速度(其实这个测出来的量充满了噪声,尽量避免使用为好)。所有网络都由具有相同架构的模块组成(例如,卷积模块在所有条件下都是相同的)。不同之处在于模块和分支的配置,如图3所示。
- 图像模块由8个卷积层和2个全连通层组成——第一个卷积核是5,其他卷积核大小是3。第一、第三和第五卷积层的步长为2。通道数从第一个卷积层的32个增加到最后一个卷积层的256个。全连接层包含512个单元。除图像模块外的所有模块都是为标准的多层感知机。激活函数为relu,激活函数后使用BN归一化。全连接层后应用50% 的dropout,卷积层后面应用20% dropout。
- 动作是一个二维向量——转向角s和加速度a : a = 〈s, a〉。预测的动作记为a,ground truth 动作记为 agt,每个样本的损失函数定义为:
-
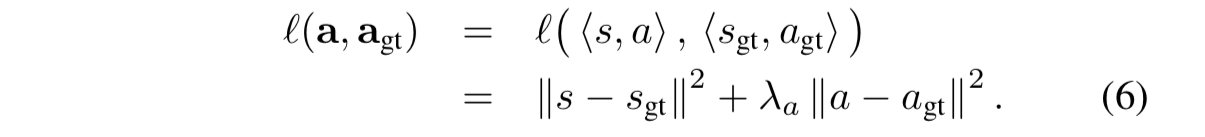
- 所有模型均使用Adam优化器进行训练,batch-size为120,初始学习率为0.0002。对于command-conditional models,每个batch中——每个命令具有相同的样本数量。

-
C. Training Data Distribution
- 在模仿学习时,一个关键因素:是如何收集训练数据。最简单的解决方案是从专家演示中收集轨迹。但这通常会导致不稳定的策略,因为仅在专家轨迹上训练出的模型,可能无法学会从扰动或漂移中恢复。
- 为了克服这个问题,训练数据应该包括这样的ob——从扰动中恢复。“DAgger系统”的方案——训练控制器的过程中,专家保持这样的循环状态:对控制器不断进行测试,得到轨迹样本后,由专家不断地重新标记。在“Bojarski的系统”中——他使用了三个摄像机的方案(一前&一左&一右):【此处为啥三个摄像机没看懂】
- 本文中,我们的方案——也使用三个摄像机——然而我们发现这样学习出的策略不够健壮。因此,为了进一步扩充训练数据集,我们记录了一些数据,同时也将噪声注入专家控制信号中,让专家通过控制从这些干扰中恢复过来。不使用“带噪声的样本对进行训练”,而是使用“驾驶员对噪声做反应”的样本进行学习。
-
D. Data Augmentation
- 为了增加泛化性能,我们在网络训练过程中进行在线增强。对于要呈现给网络的每个图像,我们应用一组“具有随机采样大小的变换”的随机子集。这些转换包括对比度、亮度和色调的变化,以及高斯模糊、高斯噪声、椒盐噪声的添加,以及区域删除(屏蔽图像中随机的一组矩形,每个矩形约占图像面积的1%)。
-
-
V. SYSTEM SETUP
- 我们在模拟城市环境和以及真实环境中(1/5比例的卡车)评估了我们的方法。在这两种情况下,观测图像都是由一个中央相机和两个横向相机记录的,两个侧向摄像机相对于中心旋转了30度。所记录的控制信号为二维:转向角和加速度。转向角在-1和1之间,分别对应于全左和全右。加速度也在-1和1之间缩放,其中1表示完全正向加速度,-1表示完全反向加速度。
- 除了观察(图像)和操作(控制信号),我们还记录司机提供的“指令”。我们使用四种命令:继续(沿着路走)、向左(在下一个十字路口向左拐)、直(在下一个十字路口直走)和右(在下一个十字路口右拐)——我们用one-hot编码表示以上命令。在训练数据收集过程中,当接近十字路口时,驾驶员使用物理方向盘上的按钮(仿真时)或遥控器上的按钮(实际的小车时)来指示与预期行动方向相对应的命令。当汽车明确接下来将要做的动作时,司机将发送该命令给控制器。这些指令反映出了“高级人员或者规划器会怎么引导系统”。
-
A. Simulated Environment
- 我们使用CARLA模拟器来验证假设,其中包含了两个城镇。如图5,在城镇1进行训练,在城镇2进行测试。
-

- 为了收集训练数据,我们向驾驶员展示一个分辨率为800×600像素的第一人称视角(中心摄像头)。驾驶员使用物理方向盘和踏板控制模拟车辆,并使用方向盘上的按钮提供命令输入。司机将车速控制在每小时60公里以下,并努力避免与汽车和行人相撞,但忽略了交通灯和停车标志。我们用三个模拟摄像机记录图像,也记录其他测量数据,如速度和汽车的位置。这些图像经过裁剪,去掉了天空的一部分。CARLA还提供了额外的信息,如行驶的距离、碰撞以及违规行为检测——如行驶到对面车道或人行道上。
-
B. Physical System
- 真实环境中的实验设置如图6所示。我们装备了一辆现成的1/5比例卡车(Traxxas Maxx)和一台嵌入式计算机(Nvidia TX2),三个低成本网络摄像头,一个运行APMRover固件的飞行控制器(Holybro Pixhawk),以及其他配套的电子设备。TX2从网络摄像头获取图像,并与Pixhawk共享双向通信通道。Pixhawk接收来自TX2或人类驾驶员的控制,并将其转换为低电平PWM信号,用于卡车的速度控制器和转向伺服系统。
-
1) Data collection:
- 。。。关于真实环境的内容先跳过。。。。















12-07
 807
807
807
03-25
458
458
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









