










自动驾驶一直是人工智能的重要应用领域,在人工智能技术飞速发展的今天,如何将最新的机器学习技术应用到自动驾驶模型的训练当中,已经成为人工智能研究的前沿问题。随着人们对 AI 的要求从感知型逐渐深化到决策型,AI 在自动驾驶任务中的应用能力也成为了衡量决策型 AI 技术发展的标准之一。
OpenDILab此前也建立了 DI-drive 这一基于真实自动驾驶AI case的评测和算法平台。本文章综述了各种决策 AI 方法在自动驾驶环境中的尝试,总结了它们针对自动驾驶任务所做的各种设计类型,同时也罗列了一些决策 AI 在现实世界部署的关键挑战。
自动驾驶任务流程简介
首先简单介绍一下自动驾驶的国际标准,即人们常说的 L1 到 L5 。自动驾驶国际标准最早是由美国国家交通和公路安全管理局(NHTSA)采用的汽车工程协会(SAE)制定的标准。该标准将自动驾驶系统的能力标准分为从 0 级(人类驾驶员拥有完全控制权)到 5 级(车辆完全自行驱动):
- 级别1(L1):驾驶员和自动驾驶系统共同控制车辆,自动驾驶系统只起到辅助的作用;
- 级别2(L2):自动驾驶系统开始独立控制车辆,但驾驶员必须随时准备进行干预;
- 级别3(L3):驾驶员可以不必专注于确保车辆的安全性,但系统随时可能要求立即响应,因此驾驶员仍然必须准备在有限的时间内进行干预;
- 级别4(L4):与级别 3 相同,但驾驶系统的安全性不需要驾驶员随时准备响应,因而驾驶员可以离开驾驶座或安全地入睡;

图片来源:36氪
现在 L4 的自动驾驶系统是各公司和机构的研究重点,也是人们所期望的人工智能驾驶系统所能达到的状态。一般来说,自动驾驶任务可以分解成如下几个模块:
- 环境感知
- 策略决策
- 轨迹规划
- 运动控制
其中,环境感知包括感知模块和定位模块,它们分别通过对车辆上不同传感器和 GPS 信号等进行分析和处理,得到语义级别的感知输出,可供后续模块来使用。
在此基础上,决策模块依据行驶目标和车辆当前位置做出一些高级驾驶决策,如加速减速、直行转向、跟车变道超车等行为策略。根据决策的具体内容,并结合周围环境中道路、障碍物的分布情况,路径规划模块会给出一条连续或离散的驾驶目标轨迹、目标速度或目标路径点。最后,运动控制模块会根据这些目标计算出跟随的控制信号,并根据巡线反馈来进行控制矫正。

自动驾驶流程图,图中感知模块被细分为了左边三部分,决策和规划合并为了第四部分。不同文献对自动驾驶任务的划分粒度不同,但整体流程不变。本图来自文献 [1]
一个自动驾驶的车辆首先需要了解自己周围的环境,找到自己在地图中的定位,才能依据驾驶目标进行决策。随着近些年深度学习方法在计算机视觉领域的突破进展,自动驾驶中的感知问题越来越多的采用深度学习模型依托大数据训练解决。
自动驾驶感知主要涉及的 CV 领域包括 2D 和 3D 的检测、分割、深度估计、运动估计和跟踪等,其主要用的输入包括单目和双目图像、雷达和激光雷达、惯性传感器和GPS等。感知模块所用的模型和方法论与其他CV任务基本相同,其中主要的挑战除了对驾驶这一特定场景的泛化外,还包括多模态的感知信息融合、利用时序特性更新感知信息、行人和障碍物的姿态和行为识别以及未来行动轨迹预测等。
感知模块是现在深度学习应用在自动驾驶当中最成熟的模块,不论是理论研究还是各大厂商在实际驾驶环境中的应用都已具有一定的规模,学术界在自动驾驶领域的文章中占比最多的也是关于感知问题的。然而在后续的如决策、规划、控制模块中,包含很多传统监督学习无法完成的任务。
一方面,环境的动态特性和不确定性需要驾驶策略学会针对各种不同的场景给出最佳的决策,这是很难通过有限的数据集学习到的;另一方面,驾驶策略的输出会作用在运行的环境中,改变车辆的状态和未来的感知结果。这些问题需要具有序贯决策能力的 AI 来学习在动态环境中进行探索和交互,并依据巡线情况和历史信息实时修改决策和动作内容。
以模仿学习和强化学习为代表的决策 AI 方法通过将驾驶问题建模为马尔可夫决策过程(MDP)来学习如何从环境表示中给出最优的行为。简而言之,决策 AI 方法将自动驾驶策略建模成了从环境的状态(State)到动作(Action)的实时映射,驾驶策略通过输出动作并应用在驾驶环境中,得到下一时刻的状态(State)和奖励(Reward)。
强化学习并非直接学习数据提供的标签动作,而是通过环境反馈的奖励来学习如何提高在指定任务上的性能,其优化目标是使得整个驾驶流程的折扣总回报(discounted reward)最大。在学习过程中,驾驶策略会选择一些动作并时不时的获得一些奖励,并朝着提高其生命周期内获得的累积奖励来进行迭代优化。随着时间的推移,驾驶策略通过建立起关于不同状态-动作对的预期收益的知识来增加其获取长期奖励的能力,以此来得到更好的驾驶性能。强化学习是当下机器学习研究中非常火热的领域,人们对其在自动驾驶的决策、规划与控制任务中的表现也充满了预期。
从模仿学习到强化学习:自动驾驶决策AI的发展
接下来,本文结合一些具体的研究成果简单梳理下决策 AI 在自动驾驶中的应用发展脉络和主要的类型。决策 AI 应用于自动驾驶主要分为两大派系,即分层的模块化(Modular)方法和端到端(End-to-end)方法。
前者将自动驾驶任务从感知、决策、规划、控制等不同角度分解为多个级别的模块,其中的一个或几个采用决策 AI 方法训练的模型替代,其他部分采用传统方法或传统方法与决策 AI 融合的方法提升性能并保障稳定性。端到端的方法无需做任务分解,直接用深度网络模型建立从感知信息到驾驶动作的映射。这两种设置的优劣目前尚无定论。

模块化方法和端到端方法的对比,本图来自文献[2]
一般来说,端到端的方法更符合对深度学习问题的建模形式,依托深度模型的强拟合能力和海量数据及计算资源得到高性能的驾驶策略,但端到端神经网络是一个黑箱模型,其输出的分布难以预测,针对一些复杂场景或边界情况的输出安全性难以保障。模块化的方法可以通过将自动驾驶流程分成不同的串行模块,指定不同模块的输入和输出模态,并通过一些安全检测机制来将输出限制在合理的范围内。同样的,模块化的设计思路会遇到一些复杂模态下的网络训练问题,多个网络共同作用在一个任务上也会导致网络训练难度大大增加。
模仿学习是当下应用在自动驾驶上最成功的决策 AI 方法。模仿学习的目标是从收集到的人类驾驶记录中学习驾驶员的行为。与强化学习一样,模仿学习也将自动驾驶策略建模为从环境状态(State)到动作(Action)的映射,这样一来人类的驾驶经验就可以被用作是这一映射的标签数据。
行为克隆(Behavior Cloning, BC)便是这样一种有监督的模仿学习方法,在文章 “End-to-end Learning of Driving Models from Large-scale Video Datasets” 中,便是采用这样的方法建立了端到端的驾驶模型,通过模仿学习从人类驾驶数据中学习策略。

端到端模仿学习方法,图片来源文献 [3]
ChauffeurNet [4]是 Google Waymo 提出的一个成功应用于实车的模仿学习自动驾驶方法。ChauffeurNet 建立了一系列共同作用的网络结构,包括提取特征的 FeatureNet,用于获取自车目标路径的 AgentRNN 以及预测他车路径的 PerceptionRNN 等。通过设计一系列模仿学习的 Loss,从专家数据中学习出效果良好的驾驶策略。ChauffeurNet 采用了 Waymo 公司内部路测和仿真得到的大量数据进行训练,最终应用在了实车驾驶系统中,进行了闭环评估。
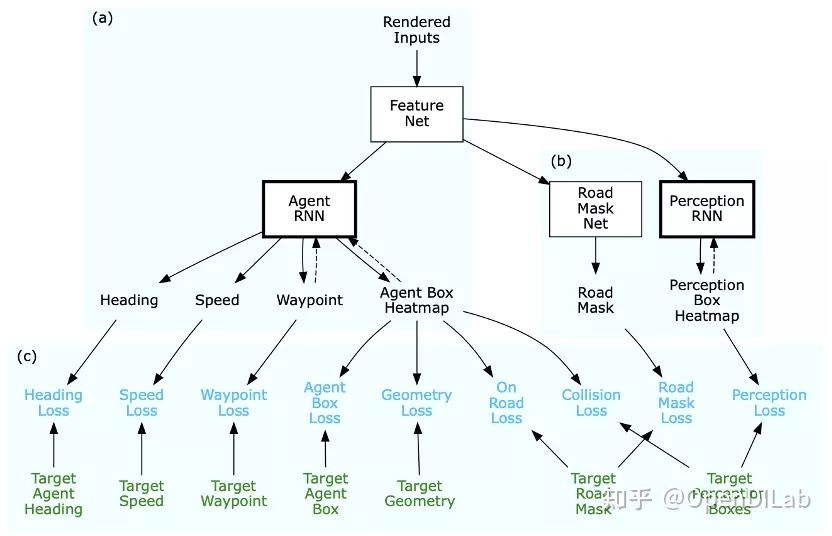
ChauffeurNet 策略网络结构图
在以自动驾驶仿真器为基础构建的算法中,有一类非常成功的方法名为 Conditional Learning。其基本思路是策略分为一个主干网络和若干个不同的分支输出,环境的状态被表示为感知信号和一个离散的决策信号,包括直行、转向、跟随等命令,策略网络会依据环境输入的命令在多个分支输出中选择一个作为实际的输出。在训练时也会根据数据里的决策信号只更新对应分支里的网络参数,但不同分支会共享主干部分参数。Conditional Imitation Learning [5] 是这一系列方法的鼻祖。在 Carla 自动驾驶仿真器中可以较方便地获得条件决策信号,因此后续采用 Carla 仿真器的方法大都沿用了这一设计,如 CILRS [6] 在 CIL 的基础上添加了和速度有关的处理,更深的网络结构等。
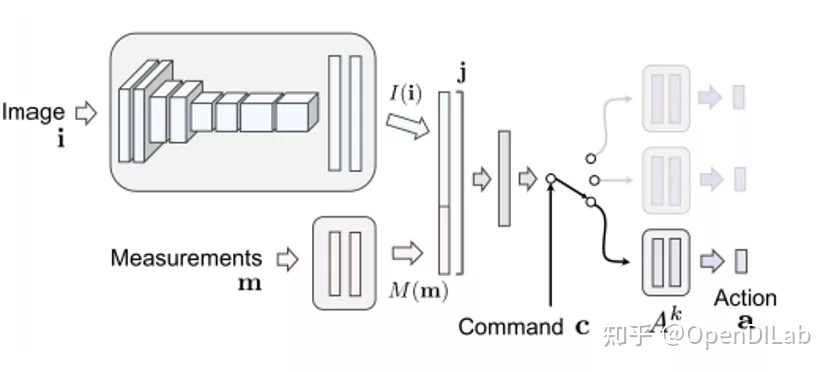
CIL 模型结构
Learning by Cheating(LBC) [7] 是另一个表现优秀的模仿学习算法。LBC 提出采用两阶段的“欺骗学习”形式来提升模仿学习的精度,首先在俯视图(Bird-eye View)输入的特权模型(cheating model)上模仿学习一个性能较好的驾驶策略,随后用前置图片输入的目标模型去学习特权模型的输入,两者的输出均为自车预期的后续驾驶路径。LBC 通过引入俯视图这一特权信息,降低了模仿学习的难度,取得了现阶段 Carla 仿真环境中 state-of-the-art 的效果。

LBC 训练原理
强化学习方法目前正处在探索前进阶段。由于强化学习网络更新的复杂性,对自动驾驶任务来说,即便是在仿真器上,从头开始训练一个纯粹的强化学习模型也是很难的,解决方案一般来说有两种思路,一种是先采用模仿学习训练一个初始化的模型权重,再在其基础上用强化学习训练得到更好的性能,如 CIRL [8]。另一种是先用监督学习方法训练一些以感知结果为label的网络,再将其骨干部分作为特征提取器,用特征作为环境的状态训练强化学习模型,如 Implicit Affordance [9] 方法。
“Learning to Drive in A Day”[10] 是一个成功将端到端的强化学习方法应用在实车驾驶环境中的工作。该方法将驾驶员视角的图像和状态作为输入,设计了 Actor-Critic 结构的强化学习端到端模型,直接输出车辆控制信号。其先在一个简单的仿真环境中训练,随后迁移到实车环境中完成训练。最终实现了可以在一个没有他车、行人的乡村环境中安全巡线的实车驾驶系统。

Learning to Drive in A Day
决策AI方法在自动驾驶中的挑战
在本节中,我们在介绍前述方法的基础上,总结了一些将决策 AI 方法应用在实际的自动驾驶系统中面临的一些挑战和未来的改进方向。
模仿学习中的偏离问题
模仿学习作为一大类决策 AI 的方法,已在自动驾驶任务的仿真、实车环境中取得了一定的成果,然而其根本问题——累计误差导致的分布偏移 依然难以得到解决。一般来说专家数据中难以穷举实际驾驶中所有可能遇到的情况,缺少对于极端状态和异常状态的反应,因此在模型运行当中,由于环境的动态特性和噪音导致的驾驶轨迹与专家轨迹的偏移会逐渐累积,最终导致巡线失败,这大大降低了驾驶系统的安全性。现阶段主要采用的方法包括在数据中添加扰动、做数据聚合(DAgger)、生成对抗模仿学习(GAIL)等。
强化学习中的采样和优化问题
采样效率问题一直是强化学习的一个重要挑战,对自动驾驶来说这一挑战更加严峻。自动驾驶任务的环境依赖于现实的物理模型。在实车环境中,采样速率与实际世界运行速率一致;在仿真环境中虽然可以通过并行化加速,但在复杂的仿真器中仍然面临比较多的困难,并且对计算资源有较大的限制。现在的驾驶方法多采用模仿学习或先训练感知模型作为强化学习的初始化模型来降低收敛难度。另一种思路是尝试对感知信息进行降维,通过学习一个对自动驾驶的决策规划完备的状态表示,降低强化学习的训练难度。
强化学习的 reward 设计问题
自动驾驶的奖励函数如何设计是一个尚无明确结论的前沿问题。一个驾驶巡线任务一般只在顺利完成巡线的时刻才能算是完成了既定目标,能够收获奖励。但这样的奖励函数在强化学习环境当中过于稀疏,极大拉高了模型优化的难度。因此,实际使用中通常针对巡线状态设计了可以实时反馈的奖励函数,并对一些危险行为进行惩罚。在强化学习方法的研究中也有些能解决稀疏 reward 问题的新进展,如课程学习(Curriculum learning)采用从简单任务到逐渐复杂的难度递增方式进行训练;model-based RL 基于模型来进行动作选择,例如基于 MCTS 的 Alpha-Go 方法;逆强化学习(Inverse RL)从专家策略中学习奖励函数等。
虚拟环境与真实环境的 gap
对于采用仿真环境训练的驾驶策略来说,一个很尴尬的现状就是它们难以部署在实车环境中。仿真环境与真实环境的区别体现在方方面面,除了对传感信号的模拟、对系统状态的仿真计算外,仿真环境的运行引擎无论做的多么逼真也不可能与现实世界一致。很多仿真器上使用的感知信号在现实世界中往往不能拿到,或者成本高昂。实际驾驶中可能遇到的各种复杂的环境和他车交互情况也难以在仿真器中模拟。【在 OpenDILab 的自动驾驶应用:DI-drive 中对这一问题做了最大程度的努力,DI-drive 构建了“Casezoo”,将实车采集到的驾驶数据和场景转化到了仿真环境中,并构建了场景的运行逻辑,而非采用一般仿真方法中只通过起始点、终点和路径来判断成功与否。Casezoo对于解决仿真 gap 尤其是对他车行为的近似上取得了不小的进步。】
自动驾驶的安全性问题
安全问题是自动驾驶的核心问题,然而对深度学习模型来说,这一点是难以保证的。在端到端的方法中,一个简单的思路是将网络模型的输出和传统方法的输出做融合,或者只在部分情况下信任网络模型的输出。在模块化的方法上,一般通过最终的控制器模块来确保驾驶信号的安全性,也可以在中间输出中添加安全性检查。深度学习的训练集同样对模型的安全性起着重要作用。一些方法通过在数据集中添加负面专家样本,或者使用负面驾驶策略(Evil expert)进行模仿学习来提高模型对极端情况的可靠性。但总体上,包含深度学习组件的系统安全性依然是个悬而未决的问题。
参考文献
[1] Kiran, B. R. , et al. "Deep Reinforcement Learning for Autonomous Driving: A Survey." IEEE Transactions on Intelligent Transportation Systems PP.99(2021):1-18.
[2] Grigorescu, S. , et al. "A survey of deep learning techniques for autonomous driving." Journal of Field Robotics 37.3(2020):362-386.
[3] H. Xu, Y. Gao, F. Yu and T. Darrell, "End-to-End Learning of Driving Models from Large-Scale Video Datasets," 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 3530-3538, doi: 10.1109/CVPR.2017.376.
[4] Bansal, Mayank, Alex Krizhevsky, and Abhijit Ogale. "Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst." arXiv preprint arXiv:1812.03079 (2018).
[5] Codevilla, F. , et al. "End-to-end Driving via Conditional Imitation Learning." IEEE (2018).
[6] Codevilla, F. , et al. "Exploring the Limitations of Behavior Cloning for Autonomous Driving." IEEE (2019).
[7] Chen, D. , et al. "Learning by Cheating." (2019).
[8] Liang, X. , et al. CIRL: Controllable Imitative Reinforcement Learning for Vision-Based Self-driving: 15th European Conference, Munich, Germany, September 8–14, 2018, Proceedings, Part VII. Springer, Cham, 2018.
[9] Toromanoff, M. , E. Wirbel , and F. Moutarde . "End-to-End Model-Free Reinforcement Learning for Urban Driving using Implicit Affordances." (2019).
[10] Kendall, A. , et al. "Learning to Drive in a Day." 2019 International Conference on Robotics and Automation (ICRA) 2019.
本文转载:















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









