







了解attention始于bert,对这样简洁的模型感到惊讶,再对attention发展的历史学习发现,大道至简啊!
两种Attention结构
- 2015年 ICLR 《Neural machine translation by jointly learning to align and translate》首次提出 attention(基本上算是公认的首次提出),文章提出了最经典的 Attention 结构(additive attention 或者 又叫 bahdanau attention)用于机器翻译。
- 2017年 NIPS《Attention is all you need》提出 transformer 的结构(涉及 self-attention,multi-head attention)。基于 transformer 的网络可全部替代sequence-aligned 的循环网络,实现 RNN 不能实现的并行化,并且使得长距离的语义依赖与表达更加准确。
Bahdanau attention
Bahdanau attention模型可以抽象为三个function:
- score function :度量环境向量与当前输入向量的相似性;找到当前环境下,应该 focus 哪些输入信息(i表示decoder的输出步,hj表示encoder的输出state) e t j = a ( s t − 1 , h j ) = v a T t a n h ( W a ∗ s t − 1 + U a ∗ h j ) e_{tj}=a(s_{t-1},h_j)=v_a^Ttanh(W_a*s_{t-1}+U_a*h_j) etj=a(st−1,hj)=vaTtanh(Wa∗st−1+Ua∗hj)
- alignment function :计算 attention weight,通常都使用 softmax 进行归一化; a t j = e x p ( e t j ) ∑ k = 1 T x e x p ( e t k ) a_{tj}=\frac{exp(e_{tj})}{\sum_{k=1}^{T_x}exp(e_{tk})} atj=∑k=1Txexp(etk)exp(etj)
- generate context vector function :根据 attention weight,得到上下文向量向量 c t = ∑ j = 1 T x a t j h j c_t=\sum_{j=1}^{T_x}a_{tj}h_j ct=j=1∑Txatjhj
获取上下文向量后,根据上下文向量做出预测
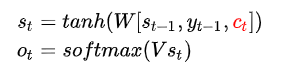

transformer attention
从seq2seq到目前的attention 一文读懂BERT(原理篇) 讲解的很详细了
transformer中的attention。假设输入为 q,Memory 中以(k,v)形式存储需要的上下文。k 是 question,v 是 answer,q 是新来的 question,看看历史 memory 中 q 和哪个 k 更相似,然后依葫芦画瓢,根据相似 k 对应的 v,合成当前 question 的 answer。


未完待续
《Attention is All You Need》浅读(简介+代码)
seq2seq中的两种attention机制(图+公式)
BahdanauAttention与LuongAttention注意力机制简介
遍地开花的 Attention ,你真的懂吗?














 5261
5261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









