







 本文探讨了CNN模型压缩的重要工作,包括SqueezeNet的FireModule设计,通过1x1和3x3卷积减少参数量,以及MobileNet提出的Depth-wise Separate Convolution,利用分组卷积和1x1卷积实现高效轻量化。这些方法在保持模型性能的同时显著降低了计算复杂度。
本文探讨了CNN模型压缩的重要工作,包括SqueezeNet的FireModule设计,通过1x1和3x3卷积减少参数量,以及MobileNet提出的Depth-wise Separate Convolution,利用分组卷积和1x1卷积实现高效轻量化。这些方法在保持模型性能的同时显著降低了计算复杂度。
本文主要总结近年来CNN的模型压缩方案
第一个代表性的工作是在2016年SqueezeNet,这篇文章中,作者总结模型设计三个原则
–(1)使用1*1网络代替3*3网络
•替换3x3的卷积kernel为1x1的卷积kernel可以让参数缩小9X为了不影响识别精度,并不是全部替换,而是一部分用3x3,一部分用1x1
•如何用1x1和3x3组合替换3x3? Fire modules
–(2)减少3*3滤波器的输入通道数
•一层卷积层参数量
#inputChannel * #outputChannel * #filters * (3*3)
–(3)降采样层移到网络的后端
延迟降采样有助于保留信息,提升性能


FireModule是本文的核心构件,思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是1x1的卷积kernel,数量记为S1x1;在expand层里面有1x1和3x3的卷积kernel,数量分别记为E1x1和E3x3,要求S1x1< input map number即满足上面的设计原则(2)。expand层之后将1x1和3x3的卷积outputfeature maps在channel维度拼接起来。
三个超参数:s(1x1):squeeze层的1*1滤波器个数;e(1x1):expand层的1*1滤波器个数;e(3x3):expand层的3*3滤波器个数;
第二个代表性的工作是2017年的MobileNet,提出Depth-wise separate convolution的结构(下图b和c),以此代替传统的convolution(下图a),如下图所示。
图b其实是group-wise convolution的一种特例,M个输入通道就有M个group,每个group只有一个channel或者说一张图。
然后再采用1x1卷积将M个group合并。
参数量变换(a-->bc):M*N*Dk*Dk --> M*1*1*Dk*Dk + M*N*1*1

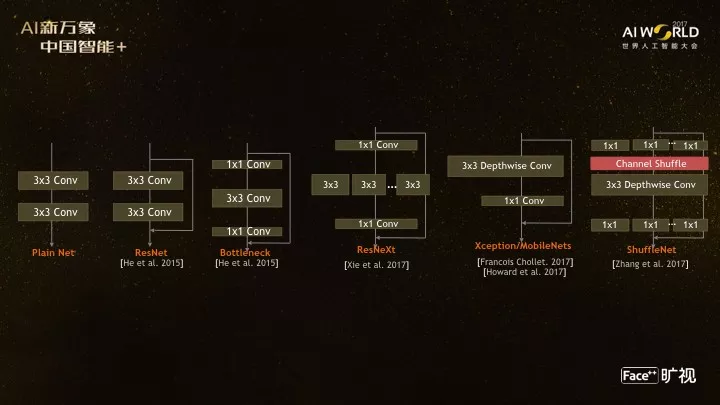
最后,贴上face++总结的CNN结构演化路径















 5512
5512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









