







目录
任务简介:
学习PyTorch数据读取机制中的两个重要模块Dataloader与Dataset。
详细说明:
本节介绍pytorch的数据读取机制,通过一个人民币分类实验来学习pytorch是如何从硬盘中读取数据的,并且深入学习数据读取过程中涉及到的两个模块Dataloader与Dataset。
一、人民币二分类

机器学习模型训练步骤:

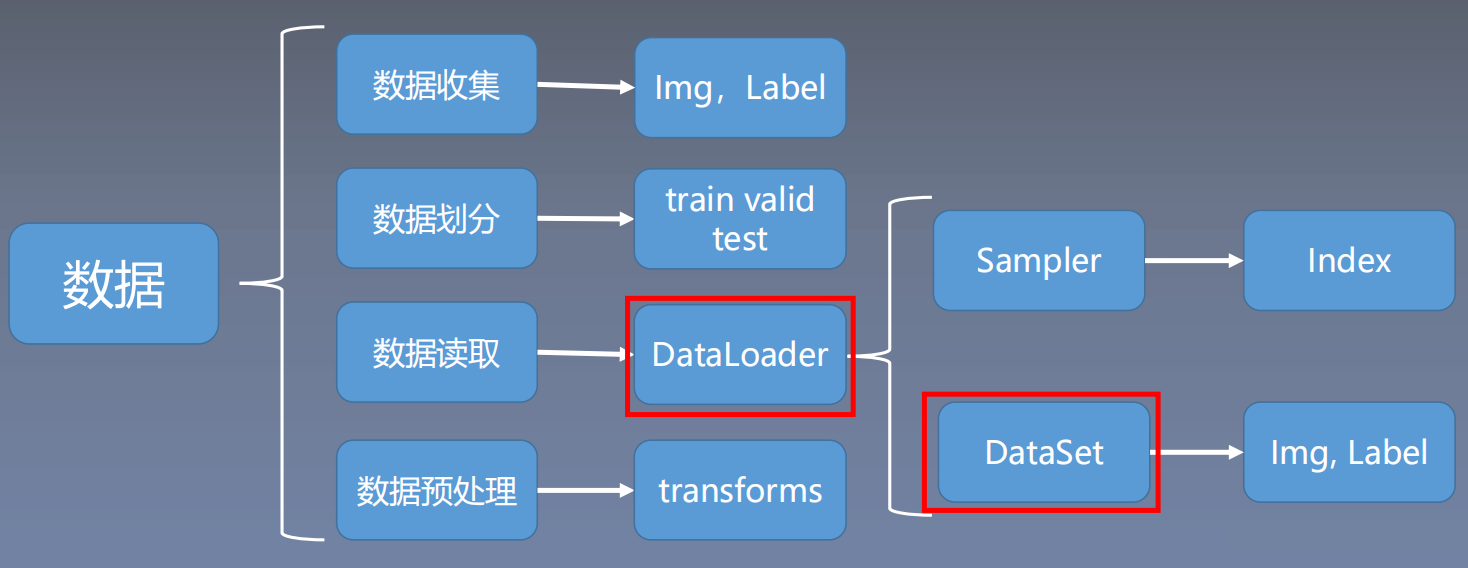 二、Dataloader与Dataset
二、Dataloader与Dataset
1. Dataloader

 2. Dataset
2. Dataset
 三、人名币二分类实现
三、人名币二分类实现
本节重点:数据读取问题

1. 数据集的划分
代码:
# -*- coding: utf-8 -*-
"""
# @file name : 1_split_dataset.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2020-07-24 10:08:00
# @brief : 将数据集划分为训练集,验证集,测试集
"""
import os
import random
import shutil
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
dataset_dir = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "data", "RMB_data"))
split_dir = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "data", "rmb_split"))
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
if not os.path.exists(dataset_dir):
raise Exception("\n{} 不存在,请下载 02-01-数据-RMB_data.rar 放到\n{} 下,并解压即可".format(
dataset_dir, os.path.dirname(dataset_dir)))
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count = len(imgs)
train_point = int(img_count * train_pct)
valid_point = int(img_count * (train_pct + valid_pct))
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
shutil.copy(src_path, target_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
print("已在 {} 创建划分好的数据\n".format(out_dir))输出:
Class:1, train:80, valid:10, test:10
已在 D:\Scientific Research\Py_Data\data\rmb_split\test\1 创建划分好的数据
Class:100, train:80, valid:10, test:10
已在 D:\Scientific Research\Py_Data\data\rmb_split\test\100 创建划分好的数据在文件夹中划分的结果:

2. 模型训练
代码:
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
print("模型获得{}元".format(rmb))
输出:
Training:Epoch[000/010] Iteration[010/010] Loss: 0.6578 Acc:56.88%
Valid: Epoch[000/010] Iteration[002/002] Loss: 1.0045 Acc:56.88%
Training:Epoch[001/010] Iteration[010/010] Loss: 0.3343 Acc:89.38%
Valid: Epoch[001/010] Iteration[002/002] Loss: 0.1628 Acc:89.38%
Training:Epoch[002/010] Iteration[010/010] Loss: 0.0836 Acc:98.75%
Valid: Epoch[002/010] Iteration[002/002] Loss: 0.0362 Acc:98.75%
Training:Epoch[003/010] Iteration[010/010] Loss: 0.2507 Acc:95.00%
Valid: Epoch[003/010] Iteration[002/002] Loss: 0.0157 Acc:95.00%
Training:Epoch[004/010] Iteration[010/010] Loss: 0.0389 Acc:98.75%
Valid: Epoch[004/010] Iteration[002/002] Loss: 0.0119 Acc:98.75%
Training:Epoch[005/010] Iteration[010/010] Loss: 0.0402 Acc:98.75%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0001 Acc:98.75%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.0043 Acc:100.00%
Valid: Epoch[006/010] Iteration[002/002] Loss: 0.0008 Acc:100.00%
Training:Epoch[007/010] Iteration[010/010] Loss: 0.0178 Acc:99.38%
Valid: Epoch[007/010] Iteration[002/002] Loss: 0.0000 Acc:99.38%
Training:Epoch[008/010] Iteration[010/010] Loss: 0.0381 Acc:99.38%
Valid: Epoch[008/010] Iteration[002/002] Loss: 0.0000 Acc:99.38%
Training:Epoch[009/010] Iteration[010/010] Loss: 0.0065 Acc:100.00%
Valid: Epoch[009/010] Iteration[002/002] Loss: 0.0001 Acc:100.00%

其他文件:
my_dataset.py
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_label = {"1": 0, "100": 1}
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
lenet.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
class LeNet2(nn.Module):
def __init__(self, classes):
super(LeNet2, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
四、数据读取流程和细节
















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









