






http://scott.fortmann-roe.com/docs/BiasVariance.html
当我们谈到预测模型,预测误差可以被分解成两个子组件:由偏差产生的误差和由方差产生的误差。这是一个模型最小化偏差和方差能力的权衡。理解这两类误差能够帮我们诊断模型结果和避免过拟合、欠拟合。
1、偏差和方差
了解不同的误差来源如何导致偏差和方差能够帮助我们改善数据拟合过程,得到更准确的模型。我们从三个方面定义偏差和方差:概念、图形和数学。
1.1 概念定义
- **偏差导致的误差:**由偏差导致的误差被视为我们模型的预期(均值)预测和我们试图预测的真实值之间的差异。当然,我们只有一个模型,说预期或者预测值的均值可能有些奇怪。但是,想象你将建立模型的整个过程重复多次:每一次收集新数据,运行新的分析建立新模型。由于数据中潜在的随机性,由此产生的模型有一个预测范围。偏差衡量的是一般来说这些模型的预测值和真实值之间偏离多远。
- **方差导致的误差:**由方差导致的误差被视为模型对一个给定数据点的预测的变化性。再次,想象你能多次重复整个模型构建过程。方差是对于给定点的预测在模型的不同实现之间有多少变化。
1.2 图形定义
我们使用一个牛眼图来可视化偏差和方差。想象目标的中心是模型完美预测是真实值。随着我们从牛眼图向外偏离,我们的预测越来越坏。想象我们可以完全重复创建模型的过程,这些模型在目标靶上得到一些分离的点。考虑到我们收集的训练数据的机会可变性,每个点代表我们的一个模型的实现。有时我们得到了一个很好的训练数据的分布,所以我们的预测很好,很接近牛眼。有时我们的训练数据会有很多离群点和非标准值,他们导致可怜的预测效果。这些不同的实现会导致命中目标上的分散。
下面给出代表高和低、偏差和方差不同组合情况的可视化:
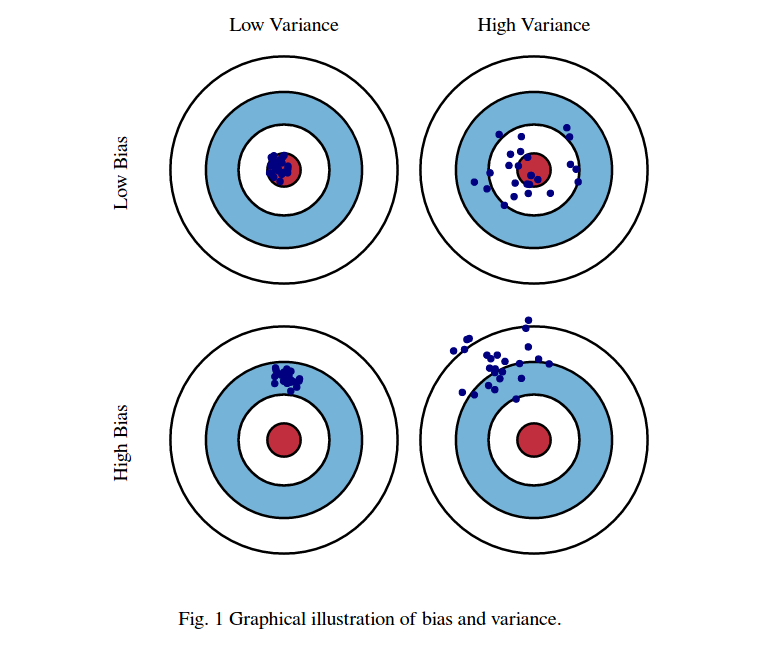
1.2 数学定义
我们使用
y
f
(
x
)
+
ϵ
yf(x)+\epsilon
yf(x)+ϵ来拟合y和x的关系,其中误差项
ϵ
\epsilon
ϵ服从均值为0,方差为
σ
ϵ
\sigma_{\epsilon}
σϵ的正态分布
ϵ
N
(
0
,
σ
ϵ
)
\epsilon \mathcal{N}(0, \sigma_{\epsilon})
ϵN(0,σϵ)。通过线性回归或者其他建模技术,我们用
f
^
(
x
)
\hat{f}(x)
f^(x)来估计模型
f
(
x
)
f(x)
f(x)。那么预测误差平方为:
E
r
r
(
x
)
=
E
[
(
Y
−
f
^
(
x
)
)
2
]
Err(x) = E[(Y - \hat{f}(x))^2]
Err(x)=E[(Y−f^(x))2]
它可以被分解为偏差和方差
E
r
r
(
x
)
=
(
E
[
f
^
(
x
)
−
f
(
x
)
]
)
2
+
E
[
(
f
^
(
x
)
−
E
[
f
^
(
x
)
]
)
2
]
+
σ
e
2
E
r
r
(
x
)
=
B
i
a
s
2
+
V
a
r
i
a
n
c
e
+
I
r
r
e
d
u
c
i
b
l
e
E
r
r
o
r
Err(x) = (E[\hat{f}(x)-f(x)])^2 + E[(\hat{f}(x)-E[\hat{f}(x)])^2] + \sigma_e^2 \\ \ \\ Err(x) = Bias^2 + Variance + Irreducible\ Error
Err(x)=(E[f^(x)−f(x)])2+E[(f^(x)−E[f^(x)])2]+σe2 Err(x)=Bias2+Variance+Irreducible Error
第三项,Irreducible Error是XY关系中的噪声项,无法通过模型来消除。给定一个真实的模型使用无限的数据来校准,偏差和方差都可以减少到0。但是,在只有不完善的模型和有限数据的情况下,减小方差还是减小偏差的权衡就很有必要了。
2.一个说明性的栗子:投票意向
我们做一个投票意向调查。我们希望建立一个模型预测在下次选举中投共和党的比例。这个工作远比人们认知中的模型的概念更为简单,但是它能够帮助我们阐明偏差和方差之间的不同。
一个直接的方法是,从电话薄上随机抽取50个电话号码,打电话询问受访者他们打算下次大选时将票投给谁。假设我们得到的结果如下:

从数据上看,我们估计共和党的得票率是13/(13+16)=44.8%。我们的结论是民主党得票率比共和党高10个百分点。但是当正式投票过后,结果与我们的预测大相径庭。我们的模型出了什么问题?
显然地,我们建立的模型存在很多问题。首先,我们通过电话簿进行采样,这会使我们样本类别过于单一,因为只有在电话簿上留号码的人才有可能被抽到。
我们不能将所有的起因都归为一类。它们可能是有偏差导致的,也可能是方差导致的。
例如,调查中使用电话簿采样产生受访者是偏差的来源之一。只调查某一些类别的人,无论调查过程重复多少次都会产生一致而且扭曲的结论。没有跟进受访者是偏差的另一个来源。在牛眼图中,这些因素会使我们偏离中心目标,但是不会使多次估计的结果分散。
另一方面,样本量的大小是方差的一个诱因。如果增加样本量,每次重复调查的结果会更加一致。虽然由于很大的偏差结果依然不准确,但是预测方差会减少。在牛眼图上,样本量少导致估计的分散。增加样本量可以使估计点簇聚集在一起,但是依然偏离目标。
通常数据集的收集与提供是在建模之前,所以不能简单的说:“让我们增大样本量来减少方差吧”。在实际中明确的偏差与方差权衡是存在的,减少一个就会增加另一个。最小化模型总的错误率需要小心平衡这两种模式的error。
3.一个应用案例: 选民政党登记
4.控制偏差和方差
试图控制偏差和方差,有一些关键的点可以考虑
4.1 克服直觉
许多人的直觉是,要减少偏差,即使是以牺牲方差为代价。他们认为偏差的存在反映了模型中存在一些基本的错误。他们承认,高方差也不好,但是高方差的模型至少能预测出比较好的平均值。这至少不是根本上的错误。
这个逻辑是错的。高方差低偏差的模型在一种长期的平均意义上确实表现良好。然而,在实际中,只会在数据集上实现单个模型,并在一个测试样本上预测一次。这么来看长期平均水平是不存在的,重要的是模型在实际数据上的性能。偏差和方差同样重要。不应该以牺牲一方的代价来改善另一方。
4.2 装代法和重采样
装袋法和其他重采样技术能够降低预测方差。大量复制和随机替换原始数据集,派生出的数据用来训练许多新模型,这些模型合成一个Ensemble。预测时,Ensemble中的所有模型投票,他们的结果平均化。
RandomForest是一个使用bagging的强大算法。它在不同的resampling数据集上训练大量的tree。整个模型的偏差与每棵树的偏差相等。通过average单个数大大降低整个模型的方差。实际上,如果不是计算时间的制约,训练无数颗树,在不增加偏差的情况下,降低方差。
4.3 算法的渐近属性
统计学术文章讨论预测算法通常提到渐近一致性和渐近效率。实际上那是暗指,随着样本量趋于无穷大,模型的偏差会趋于0(渐近一致性),同时模型的方差不会比可能使用的其他潜在模型更差(渐近效率)
这两个都是我们希望模型拥有的属性。我们不可能有无穷大的样本量,所以渐近属性一般没有实际的应用。一个渐近一致且高效的算法在小样本上的表现可能比一个不渐近一致且低效的算法更差。所以在实际的工作中还是要抛开算法的理论属性,关注给定场景下的实际准确率。
4.4 理解过拟合和欠拟合
从根本上,处理偏差和方差实际上是在处理过拟合和欠拟合。偏差降低方差增大,这与模型的复杂度直接相关。当增加更多参数,模型复杂度增加,我们需要关注的主要问题是方差,而偏差趋于稳定。
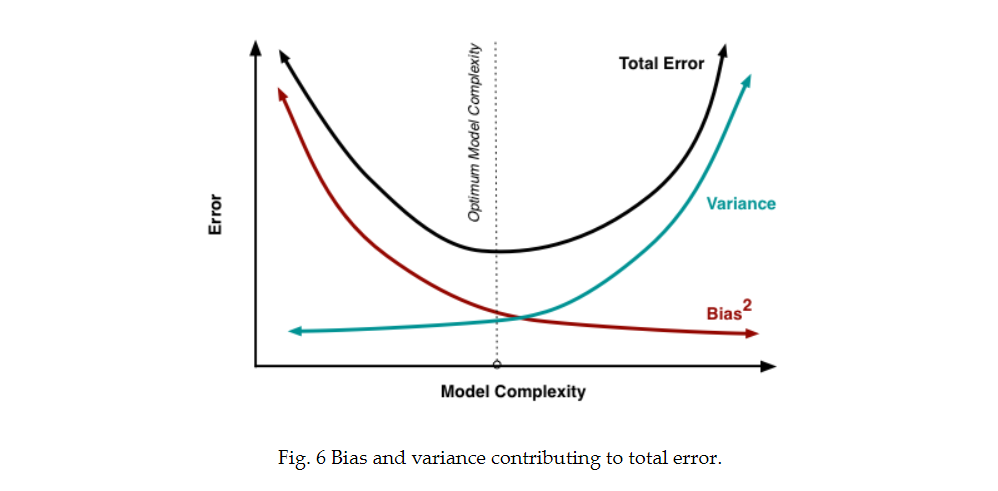
理解偏差和方差对于理解模型的行为至关重要。但是通常我们真正关注总误差,而不是将其分解来看。模型的均衡点是复杂度在偏差减少方差增大的交点上。















 5451
5451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









