







【生信】统计学基础知识
本文图片来源网络或学术论文,文字部分来源网络与学术论文,仅供学习使用。
本文参考统计学知识大梳理_lovenankai的专栏-CSDN博客
目录
1、首先建立思维模式
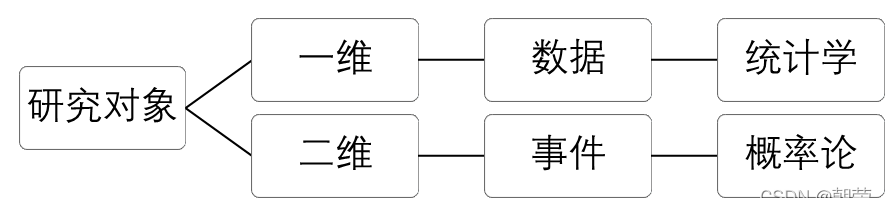
当我们开始处理数据时,首先需要明确统计学中的研究对象,可以将对象分别看做“一维”和“二维”的。拿到具体的研究对象后,接下来确定属于一维/二维数据,然后分支检索需要用到的知识。
所谓“一维”和“二维”就是:
一维数据就是摆在面前的一组/一批/一堆数据,统计学将这类数据作为研究对象。
二维数据就是当我们研究某个事件时(即在数据的基础上加上时间轴因素),考虑过去、未来的发生几率和可能性,这类问题是概率论的研究范畴。
2、如何处理“一维”数据
对于一维数据采用统计学方法:
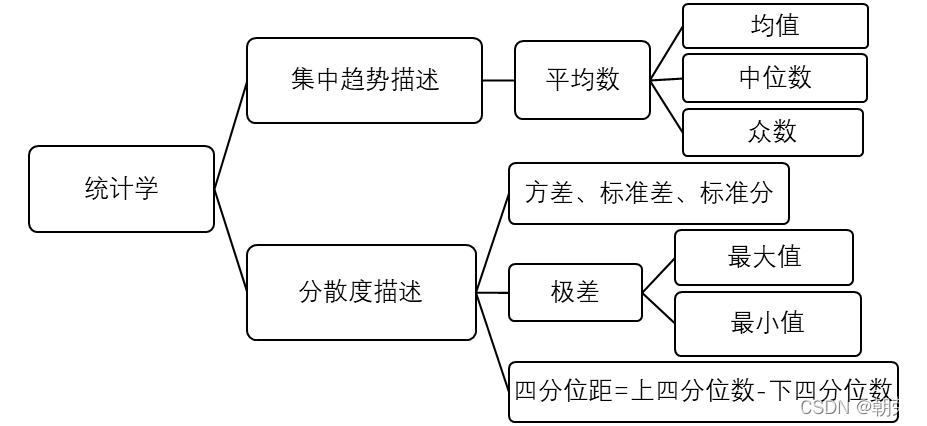
集中趋势量度:即为这批数据找到它们的“代表”。
集中趋势量度(平均数)能让我们知道数据集典型值——数据中心所在处,但若要给数据下具体的结论,则还是缺少足够的信息。通过分析各种距和差,来判断数据集离平均值的波动程度。
分散程度(或变异性的量度):全距,迷你距,四分位数,标准差,标准分
几个数值的计算方法:
(1)均值:均值是最常用的平均数之一。
(2)中位数:又称中点数,中值。是按顺序排列的一组数据中居于中间位置的数。
(3)众数:样本观测值在频数分布表中频数最多的那一组的组中值。
(4)全距(极差):一组数据中最大值与最小值之差。可以用于度量数据的分散程度。
(5)迷你距(四分位距):不再度量整个数据集的全距,而是度量中央部分数据集的全距,通过迷你距可以有效忽略异常值的存在。而通过一个统一的方法来对数据集进行划分,将有助于我们确保多批数据集处理时所有都是以相同的方式忽略了异常值。
四分位距一定程度上反应了数据的分散程度,但是却无法精准的告诉我们,这些数值具体出现的频率
计算方法:所有观测值从小到大排序后四等分,处于三个分割点位置的数值就是四分位数:Q1,Q2和Q3。
- Q1:第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
- Q2:第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字
- Q3:第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
迷你距= 上四分位数 - 下四分位数

我们度量每批数据中数值的“变异”程度时,可以通过观察每个数据与均值的距离来确定,各个数值与均值距离越小,变异性越小数据越集中,距离越大数据约分散,变异性越大。方差和标准差就是用于表征数据变异程度的概念。
(6)方差:数值与均值的距离的平方数的平均值。
(7)标准差:标准差为方差的开方。

(8)标准分:表征距离均值的标准差的个数。当比较均值和标准差各不相同的数据集时,我们可以把这些数值视为来自同一个标准的数据集,然后进行比较。标准分将把每一个数据集转化为通用的分布形态,进行比较。标准分可以把正态分布变为标准正态分布。
通过标准分使多批数据集转化成一种统一通用的分布,进而可以对不同数据集的数据进行比较,而这些不同数据集特性可以互不相同,比如各均值和标准差各不相同。

小结——对于“一维”数据进行统计学方法分析的思路如下:
-
描述一批数据,通过集中趋势分析,找出其“代表值” ;通过分散和变异性的描述,查看这批数据的分散程度。
-
集中趋势参数:均值,中位数,众数
-
分散性和变异性参数 : 全距,四分位距,方差,标准差,标准分
3、如何处理“二维”数据
对于二维数据(即事件)采用概率论方法:

1、对于一个事件的情况
首先明确几个关于事件的概念:
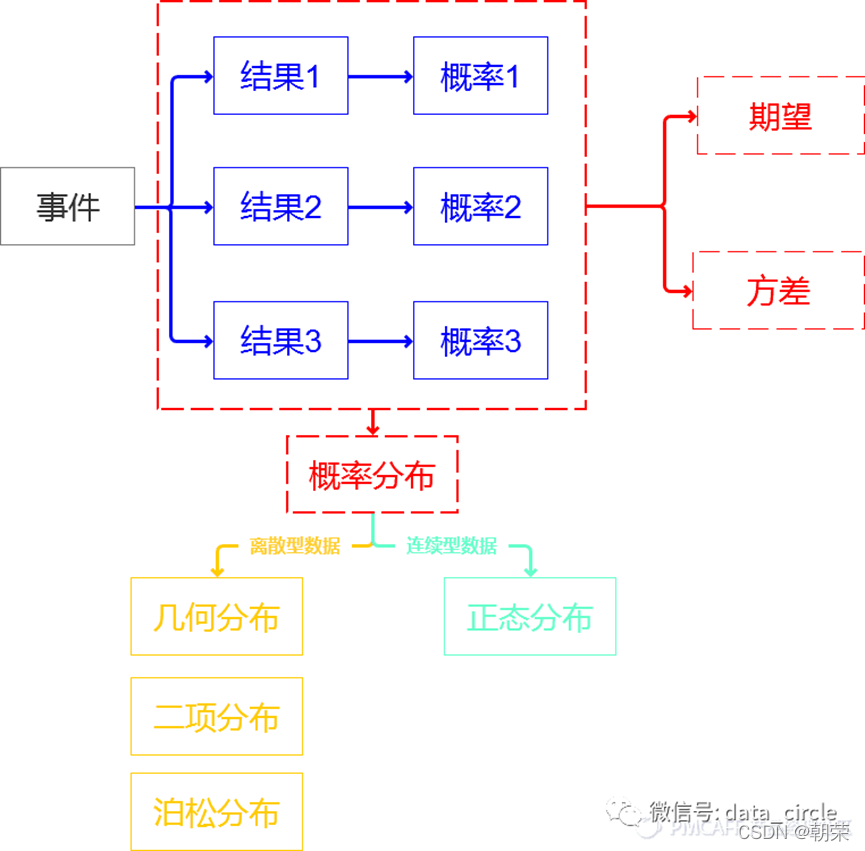
(1)事件:有概率可言的一件事情,一个事情可能会发生很多结果,结果和结果之间要完全穷尽,相互独立。
(2)概率:每一种结果发生的可能性。所有结果的可能性相加等于1,也就是必然。
(3)概率分布:我们把事件和事件所对应的概率组织起来,就是这个事件的概率分布。概率分布可以是图象,也可以是表格。
(4)期望:表征了综合考虑事情的各种结果和结果对应的概率后这个事情的综合影响值。(一个事件的期望,就是代表这个事件的“代表值”,类似于统计里面的均值)
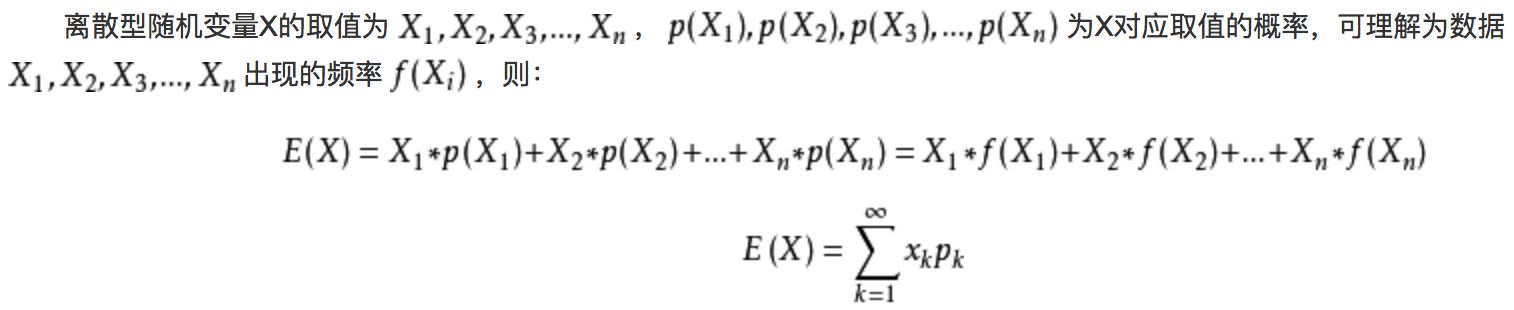
(5)方差:表征了事件不同结果之间的差异或分散程度。方差=E (x²)-E (x)²
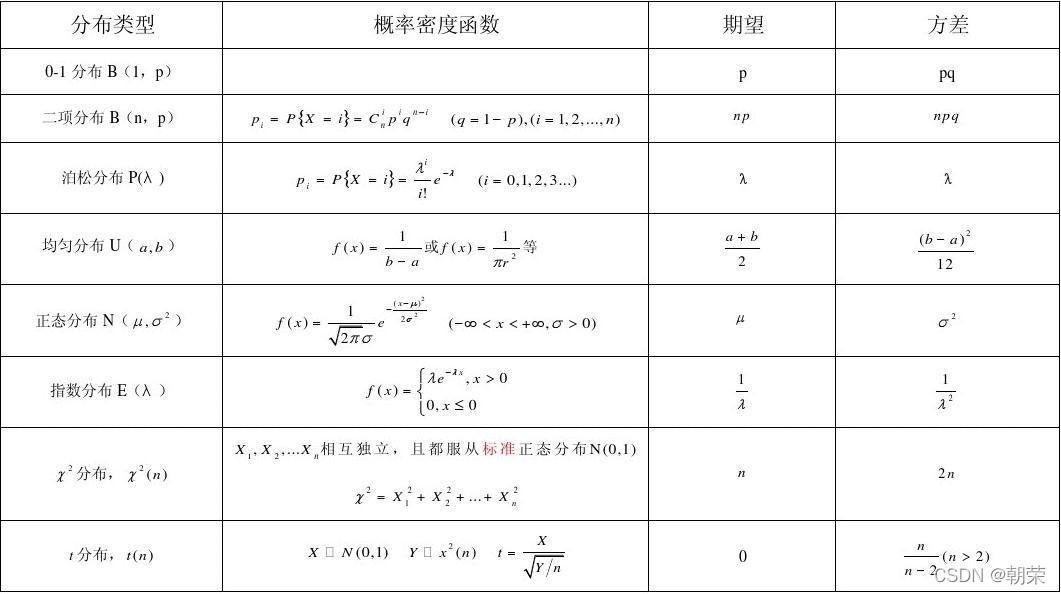
均匀分布的方差与期望:

2、对于一个分布
现实情况中,当某些事件,满足某些特定的条件,那么我们可以直接根据这些条件,来套用一些固定的公式,来求解这些事件的分布,期望以及方差。
区分离散/连续数据:判别一个数据是连续还是离散最本质的因素在于,一个数据组中数据总体的量级和数据粒度之间的差异。差异越大越趋近于连续型数据,差异越小越趋近于离散型数据。
(1)离散型分布:离散数据的概率分布,就是离散分布。这三类离散型的分布,在“0-1事件”中可以采用,就是一个事只有成功和失败两种状态。

(2)连续型分布:连续型分布本质上就是求连续的一个数据段概率分布。
最典型的是正态分布 。
正态分布概率的求法:确定分布和范围 ,求出均值和方差; 利用标准分将正态分布转化为标准正态分布 。最后查表找概率
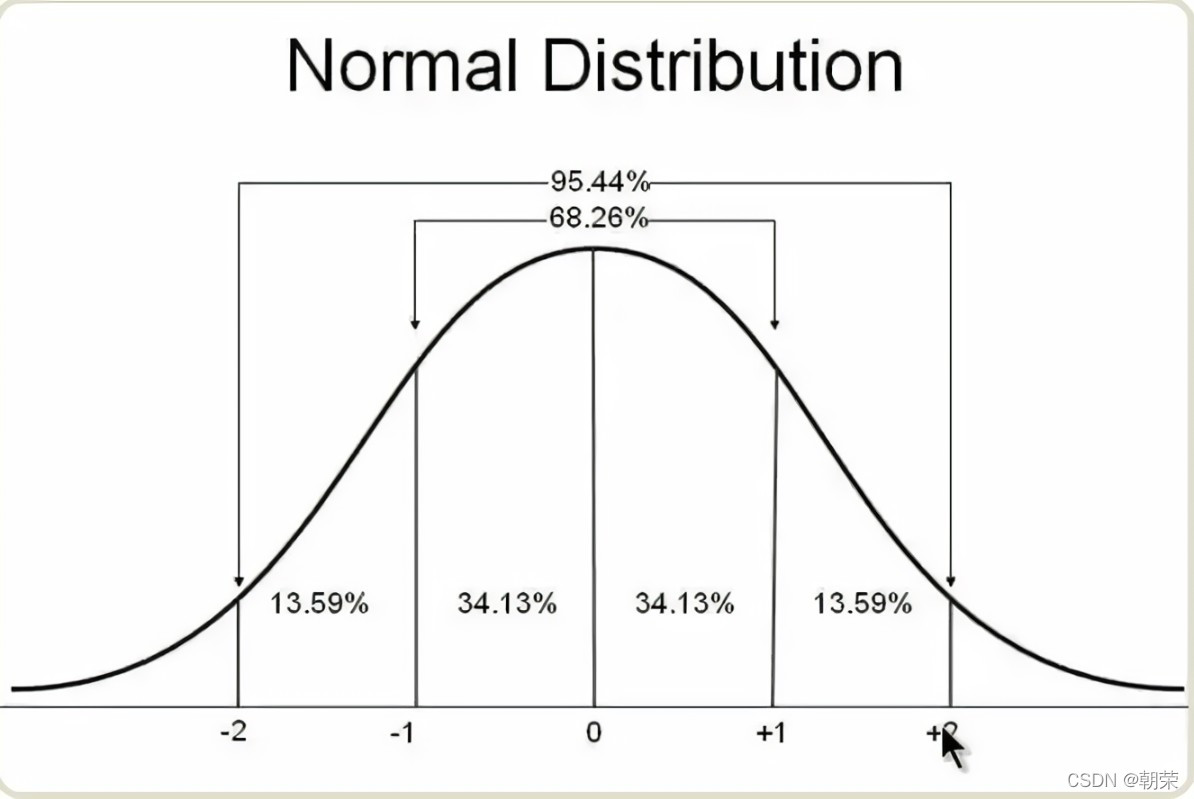
连续型数据和离散型数据是一对相对的概念,那么这就意味着在某种“边界”条件下,离散型分布和连续型分布之间是可以相互转化的。进而简化概率分布的计算。
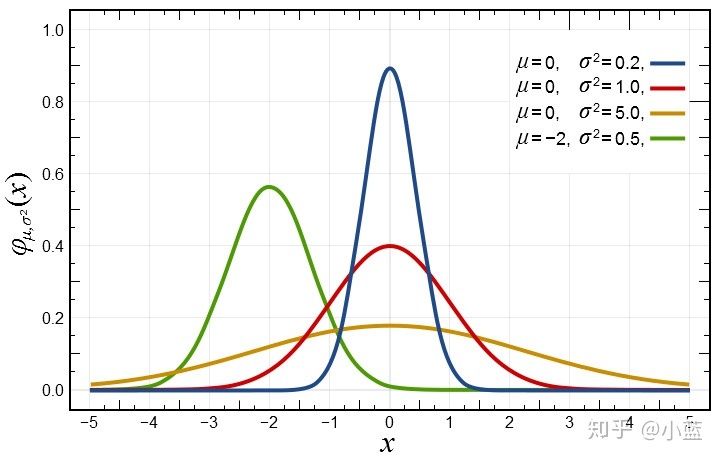
3、对于多个事件的情况
多个事件就要探讨事件和事件之间的关系。采用“概率树”和“贝叶斯定理”的方法。
对立事件:如果一个事件,A’包含所有A不包含的可能性,那么我们称A’和A是互为对立事件
穷尽事件:如何A和B为穷尽事件,那么A和B的并集为1
互斥事件:如何A和B为互斥事件,那么A和B没有任何交集
独立事件:如果A件事的结果不会影响B事件结果的概率分布那么A和B互为独立事件。
相关事件:如果A件事的结果会影响B事件结果的概率分布那么A和B互为独立事件。
条件概率:条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。 条件概率表示为:P(A|B)。

贝叶斯公式 :设B1,B2,…Bn…是一完备事件组,则对任一事件A,P(A)>0,有
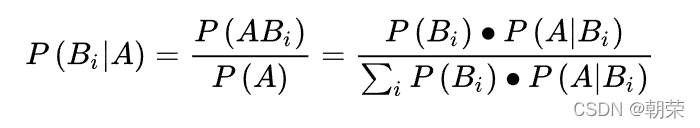
当我们知道A发生的前提下B发生的概率,可以用贝叶斯公式来推算出B发生条件下A发生的概率。
小结——对于“二维”事件的处理方法:
1. 事件,概率,概率分布之间的关系
2. 期望,方差的意义
3. 连续型数据和离散型数据之间的区别和联系
4. 几何分布,二项分布,泊松分布,正态分布,标准正态分布
5. 离散分布和正态分布可以转化
6. 多个事件之间的关系,相关事件和独立事件,条件概率和贝叶斯公式
4、“小样本”预测“大总体”
现实生活中,总体的数量如果过于庞大我们无法获取总体中每个数据的数值,进行对总体的特征提取进而完成分析工作。

step1:抽取样本
- 总体:你研究的所有事件的集合
- 样本:总体中选取相对较小的集合,用于做出关于总体本身的结论
- 偏倚:样本不能代表目标总体,说明该样本存在偏倚
- 简单随机抽样: 随机抽取单位形成样本。
- 分成抽样: 总体分成几组或者几层,对每一层执行简单随机抽样
- 系统抽样:选取一个参数K,每到第K个抽样单位,抽样一次。
step2:预测总体(点估计预测,区间估计预测)
- 点估计量:一个总参数的点估计量就是可用于估计总体参数数值的某个函数或算式。
- 区间估计量:点估计量是利用一个样本对总体进行估计,区间估计是利用样本组成的一段区间对样本进行估计。
step3:验证结果(假设检验)
- 假设检验是一种方法用于验证结果是否真实可靠。具体操作分为六个步骤。
接下来详细阐述step2-3的具体方法:
1、step2预测总体——点估计量的几场景
场景1: 样本无偏的情况下,已知样本,预测总体的均值,方差。
样本的均值 = 总体的估算均值(总体均值的点估计量) ≈ 总体实际均值(误差是否可接受)

总体方差 估计总体方差

场景2:已知总体,研究抽取样本的概率分布
比例抽样分布:考虑从同一个总体中取得所有大小为n的可能样本,由这些样本的比例形成一个分布,这就是“比例抽样分布”。样本的比例就是随机变量。
举个栗子:已知所有的糖球(总体)中红色糖球比例为0.25。从总体中随机抽n个糖球,我们可以求用比例抽样分布求出这n个糖球中对应红球各种可能比例的概率。

样本均值分布:考虑同一个总体中所有大小为n的可能样本,然后用这个样本的均值形成分布,该分布就是“样本均值分布” ,样本的均值就是随机变量。

中心极限定理:如果从一个非正态总体X中抽出一个样本,且样本极大(至少大于30),则图片.png的分布近似正态分布。

2、step2预测总体——区间估计量的几场景


3、step3验证结果

两类错误---即使我们进行了“假设检验”依然无法保证决策是百分百正确的,会出现两类错误

小结——对于小样本预测大总体的方法:
1. 无偏抽样
2. 点估计量预测(已知样本预测总体,已知总体预测样本)
3. 区间估计量预测(求置信区间)
4. 假设检验

















 5648
5648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









